

This edition is shorter and more focused—we want to talk about the future of ZenML and, more importantly, how you can help shape it. With almost 5,000 of you subscribed (still can’t believe that number!), your input matters more than ever.
** 📿 The Pattern Repeats Itself**
When we wrote the first lines of ZenML four years ago, our goal wasn’t to build yet another MLOps tool that solved one narrow problem. We wanted to introduce a standardized process for shipping ML workloads to production.
The idea was simple: there are so many brilliant platforms and tools out there—how do we combine them and get the best of all worlds in one coherent stack?
This led us to create the concept of components and stacks. Components are configurable entities that define how a workload (a pipeline) gets executed. We wanted to disconnect business logic from infrastructure logic, making ML development truly portable and reproducible.
This model has worked well. Companies from JetBrains to Adeo Leroy Merlin now use these abstractions for standardized ML development at massive scale.
The last two years have seen LLM-powered applications dominate the space. This year—the so-called “year of agents”—is gripping everyone’s attention. And we’re seeing the The last two years have seen LLM-powered applications dominate the space. This year—the so-called “year of agents”—is gripping everyone’s attention. And we’re seeing the exact same patterns unfold that we witnessed in early MLOps:exact same patterns unfold that we witnessed in early MLOps: unfold that we witnessed in early MLOps:☯The last two years have seen LLM-powered applications dominate the space. This year—the so-called “year of agents”—is gripping everyone’s attention. And we’re seeing the The last two years have seen LLM-powered applications dominate the space. This year—the so-called “year of agents”—is gripping everyone’s attention. And we’re seeing the exact same patterns unfold that we witnessed in early MLOps:exact same patterns unfold that we witnessed in early MLOps: unfold that we witnessed in early MLOps:☯
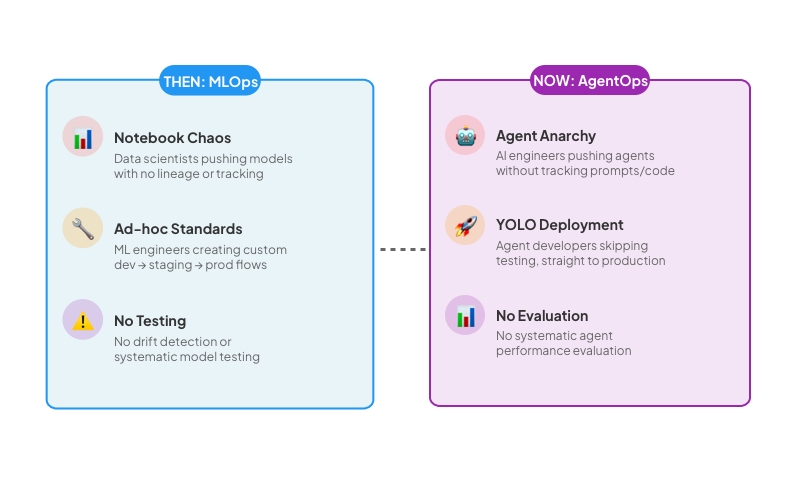
Look familiar?
After watching agents struggle and fail in production for a few years, we’re confident enough to apply what we learned in MLOps to the LLMOps/AgentOps space. There are enough scattered practices (check out our LLMOps Database if you haven’t) that we can start unifying them under one umbrella.
** 📺 Our Three-Pillar Vision**
Based on extensive feedback from customers doing some really cool stuff, we’re developing ZenML around three core pillars:
1. LLM Abstractions as First-Class Citizens
We’re building native LLM stack components that bring the same standardization to LLM development that we brought to traditional ML:
- LLM Provider Component: Unified API management across OpenAI, Anthropic, Google, with automatic cost tracking, fallback models, and rate limiting
- Prompt Manager Component: Version-controlled prompt templates with Git integration and Jinja2 templating
- LLM Evaluator Component: Standardized interface with LLM-as-judge capabilities for comprehensive model comparison
- LLM Tracer: Deep observability for tracing every LLM call and agent session (powered by tools such as OpenTelemetry)
The beauty? These work alongside your existing MLOps stack. Same patterns, expanded capabilities.
The following code snippets are just indicators of what the interface(s) might look like. Nothing’s written in stone yet and this is certainly work in progress…


Note that here we are invoking an “agent” from within ZenML — a pattern we expect to see a lot more often (batch evals, invoking in production, iterating while developing etc).
2. MLOps Principles for Agentic Development
Having an MLOps flywheel while developing an agent is something that excites us here at ZenML. Picture a ZenML pipeline that orchestrates your agent (LangGraph, CrewAI, whatever you use) while automatically:
- Setting up tracing observability through our stack components
- Versioning prompts as artifacts with full lineage tracking
- Running systematic evaluations after each agent execution
- Creating feedback loops for continuous improvement
- Providing unified visibility across traditional ML and agent workloads
This is our vision of the complete agent development lifecycle—not the current “build it and pray” approach.


3. Faster, More Reliable Orchestration

As stated above, there will be cases where you might want to invoke agents within a ZenML pipeline. However, there are also other cases where it might make sense to bake the LLM calls directly into the workflows directly. As we discussed last month, we’ve learned that workflows are often better than fully autonomous agents for production use cases. More autonomy means more entropy, which enterprise applications can’t tolerate.
Read about a concrete example with the Steerable Deep Research product that we recently wrote about
We’re building orchestration that’s lightning-fast for agent workloads. We already have a PR open for Modal orchestration that executes agents at scale with proper resource management and monitoring.
The insight from our Paris keynote holds: “Start simple before you go full autonomous. Never go full autonomous.” Our 200x performance improvements unlock workflow complexity that simply wasn’t feasible before, making these orchestration patterns practical at enterprise scale.
Moving, we expect ZenML to support both cases, i.e., integrating into LLM orchestration frameworks like Pydantic AI and Langgraph, and also integrating LLM provider component to invoke LLMs directly in the workflow.
** 🙏 We Need Your Input**
This is where you come in. We’re not building this in isolation—we want to solve real problems you’re facing today.
Whether you’re:
- Struggling with agent evaluation in production
- Managing multiple LLM providers and their costs
- Trying to apply MLOps discipline to LLM workflows
- Building hybrid applications that combine traditional ML with agents
- Or just curious about where this is all heading
We want to hear from you.
Take our 5-minute survey to help shape ZenML’s LLMOps direction. Your feedback will directly influence what we build first and how we prioritize features. You will also be placed in a lucky draw to win 3 months of ZenML Pro for free!
The infrastructure we build today determines which organizations can deploy AI at scale versus which ones stay stuck in pilot mode. That’s the opportunity we’re all working toward.
Until next time,
Hamza


