

On this page
Modern ML engineering relies on pipelines to automate data preparation, model training, evaluation, and deployment. However, selecting the right orchestration tool can be a significant challenge for ML engineers and data scientists, as there are a lot of platforms capable of running ML pipelines.
This Flyte vs Airflow vs ZenML article compares these platforms’ features, integrations, and pricing so that you can read and understand which of the three is the best one for you.
A quick note before we get started: Rather than positioning the three platforms as competitors, in this article, we explore how these platforms complement each other in modern ML operations. Many successful teams use combinations of these tools, leveraging each platform’s strengths while mitigating individual weaknesses.
Flyte vs Airflow vs ZenML: Key Takeaways
🧑💻 Flyte: An open-source, Kubernetes-native orchestration engine for ML and data workflows. It emphasizes reproducibility and scale: workflows are fully versioned and can be rolled back, and task outputs can be cached to avoid recomputation. Flyte pipelines and tasks are defined with @task and @workflow decorators in Python.
🧑💻 Apache Airflow: A mature, general-purpose workflow scheduler. Airflow pipelines are defined in Python using TaskFlow or DAG code. It excels at long-running batch or streaming workflows with retries, notifications, and a stable UI. Airflow is data-agnostic, extensible via providers/plugins (for cloud services, ML tasks, etc.), and entirely open-source.
🧑💻 ZenML: ZenML pipelines are simple Python functions decorated with @pipeline, composed of @step functions. The platform automatically stores each step’s outputs as artifacts, creating full data lineage. It provides built-in logging of parameters, metrics, and artifacts, and integrates with 50+ external tools (MLflow, W&B, Comet for experiment tracking; S3 or GCS for storage; and various orchestrators).
Flyte vs Apache Airflow vs ZenML: Feature Comparison
Here’s a TL;DR of comparable features of Flyte, Airflow, and ZenML:
| Capability | Best-suited |
|---|---|
| Workflow Orchestration |
|
| Artifact and Data Versioning |
|
| Experiment Tracking |
|
| Integration Ecosystem |
|
If you want to learn more about how each of the above features compares to one another for the three MLOps platforms, read ahead.
In this section, we compare Flyte, Apache Airflow, and ZenML across the three most important MLOps features:
- Workflow orchestration
- Artifact and Data Versioning
- Experiment Tracking
Feature 1. Workflow Orchestration
Workflow orchestration is the process of coordinating the execution of various steps in an ML pipeline. It is a critical component of any MLOps strategy.
Flyte
Flyte is a Python-native, Kubernetes-centric workflow orchestrator specifically designed for complex, data-intensive AI/ML workflows. It lets you define tasks and workflows using Python decorators, which are then compiled into a Directed Acyclic Graph (DAG) for execution on a Kubernetes cluster.
This design choice allows Flyte to manage complex, heterogeneous dependencies within the same workflow by containerizing workloads.
One standout feature of Flyte is versioned workflows: every time you change and deploy a Flyte workflow, it is recorded as a new version. You can then select or roll back to previous versions on the Flyte UI.
Flyte also supports output caching: if you set cache=True, a task will reuse results from a previous run of inputs and an optional cache_version tag.
What’s more, Flyte supports dynamic workflows, allowing the DAG shape to change at runtime based on data, and offers native compute capabilities for GPU/TPU instances and spot instances, which can cut costs for model training.
import pandas as pd
from flytekit import Resources, task, workflow
from sklearn.datasets import load_wine
from sklearn.linear_model import LogisticRegression
@task(requests=Resources(mem="700Mi"))
def get_data() -> pd.DataFrame:
"""Get the wine dataset."""
return load_wine(as_frame=True).frame
@task
def process_data(data: pd.DataFrame) -> pd.DataFrame:
"""Simplify the task from a 3-class to a binary classification problem."""
return data.assign(target=lambda x: x["target"].where(x["target"] == 0, 1))
@task
def train_model(data: pd.DataFrame, hyperparameters: dict) -> LogisticRegression:
"""Train a model on the wine dataset."""
features = data.drop("target", axis="columns")
target = data["target"]
return LogisticRegression(**hyperparameters).fit(features, target)
@workflow
def training_workflow(hyperparameters: dict) -> LogisticRegression:
"""Put all of the steps together into a single workflow."""
data = get_data()
processed_data = process_data(data=data)
return train_model(
data=processed_data,
hyperparameters=hyperparameters,
)Apache Airflow
Airflow is a general-purpose DAG-based scheduler. You define a pipeline in Python using the TaskFlow API or by instantiating operator tasks, and Airflow’s scheduler runs tasks according to dependencies. Its Python-native design makes it easy to incorporate ML code and integrate libraries.
It excels at complex dependencies, retries, and monitoring: for example, Airflow natively supports dynamic pipelines, conditional branching, and a mature UI for monitoring and alerting.
However, Airflow was originally built for data engineering (ETL/ELT) and does not inherently provide ML-specific primitives. It requires more setup to manage things like model artifacts or metrics. In practice, Airflow pipelines often delegate ML work to specialized tools (TensorFlow, PyTorch scripts, etc.) or external services.
Any Python function or shell command can be run as a task, and a wide set of providers and operators exist to connect Airflow with cloud services (AWS Sagemaker, GCP Vertex, Docker, etc).<>prpre
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.empty import EmptyOperator
from datetime import datetime, timedelta
# Example Python function to be used in a task
def extract_data():
print("Extracting data...")
def transform_data():
print("Transforming data...")
def load_data():
print("Loading data...")
# Define the DAG
with DAG(
'etl_pipeline_example',
description='A simple ETL pipeline using Apache Airflow',
start_date=datetime(2023, 2, 5),
schedule_interval=timedelta(minutes=5),
catchup=False
) as dag:
start = EmptyOperator(task_id='start')
extract = PythonOperator(
task_id='extract',
python_callable=extract_data
)
transform = PythonOperator(
task_id='transform',
python_callable=transform_data
)
load = PythonOperator(
task_id='load',
python_callable=load_data
)
end = EmptyOperator(task_id='end')
# Set task dependencies
start >> extract >> transform >> load >> endZenML
When it comes to workflow orchestration, ZenML takes a different approach. The platform is specifically built for ML pipelines and emphasizes ease of use and portability.
In ZenML, you write each step as a normal Python function annotated with @step, and then define a @pipeline that wires steps together. Running the pipeline is as simple as calling that function (for example, my_pipeline()).
By default, ZenML runs steps locally for easy experimentation. Then you can scale up by switching the pipeline to a remote orchestrator: ZenML supports Airflow, Kubeflow Pipelines, Amazon SageMaker, Google Vertex AI, and more, via simple stack configurations.
This means you get an orchestration back-end of your choice, but you still define pipelines with ZenML’s simple abstractions.
ZenML also auto-handles resource caching similar to Flyte; you can cache steps to skip redundant work, and when you re-run a pipeline, ZenML knows which steps have changed. The key advantage of this functionality is flexibility: you can prototype locally, then run on your favorite Kubernetes cluster or cloud service without rewriting pipeline code.
Bottom line: Flyte provides robust, Kubernetes-native ML-centric orchestration with strong typing and reproducibility guarantees, ideal for teams deeply embedded in the Kubernetes ecosystem and requiring fine-grained control over ML-specific compute.
Apache Airflow is a versatile, general-purpose orchestrator widely adopted for its DAG-as-code approach and extensive integrations for diverse data pipelines, though it requires external tools for comprehensive ML-specific features.
ZenML distinguishes itself as a meta-orchestrator, abstracting away the underlying execution environment and offering unparalleled flexibility to switch between orchestrators without code changes, bridging local development and scalable cloud deployments with ML-specific optimizations.
# zenml integration install kubeflow
# zenml orchestrator register kf_orchestrator -f kubeflow ...
# zenml stack update my_stack -o kf_orchestrator
from zenml import pipeline, step
@step
def preprocess_data(data_path: str) -> str:
# Preprocessing logic here
return processed_data
@step
def train_model(data: str):
# Model training logic here
return model
@pipeline
def my_pipeline(data_path: str):
processed_data = preprocess_data(data_path)
model = train_model(processed_data)
# Run the pipeline
my_pipeline(data_path="path/to/data")Feature 2. Artifact and Data Versioning
Effective artifact and data versioning are fundamental for reproducibility, debugging, and governance in machine learning.
Flyte
Flyte offers robust artifact and data versioning capabilities, which are fundamental for reproducibility in ML workflows. Flyte versions entire workflows every time you deploy, so you can reproduce or roll back a pipeline run to an exact definition.
In addition to versioned workflows, Flyte has a concept of data and task outputs being cached and tracked. If you enable caching on a task, Flyte records its outputs in a Data Catalog, keyed by the code version and inputs. Later runs with the same inputs will fetch the cached outputs instead of re-running the computation. This implicit artifact caching is akin to the versioning of data artifacts.
Flyte’s UI (Flyte Console/Deck) also shows metadata for each task execution (input/output hashes, parameters). While Flyte doesn’t have a dedicated ‘model registry’ like ZenML, its versioned workflows and caching ensure that data and code stay consistent.
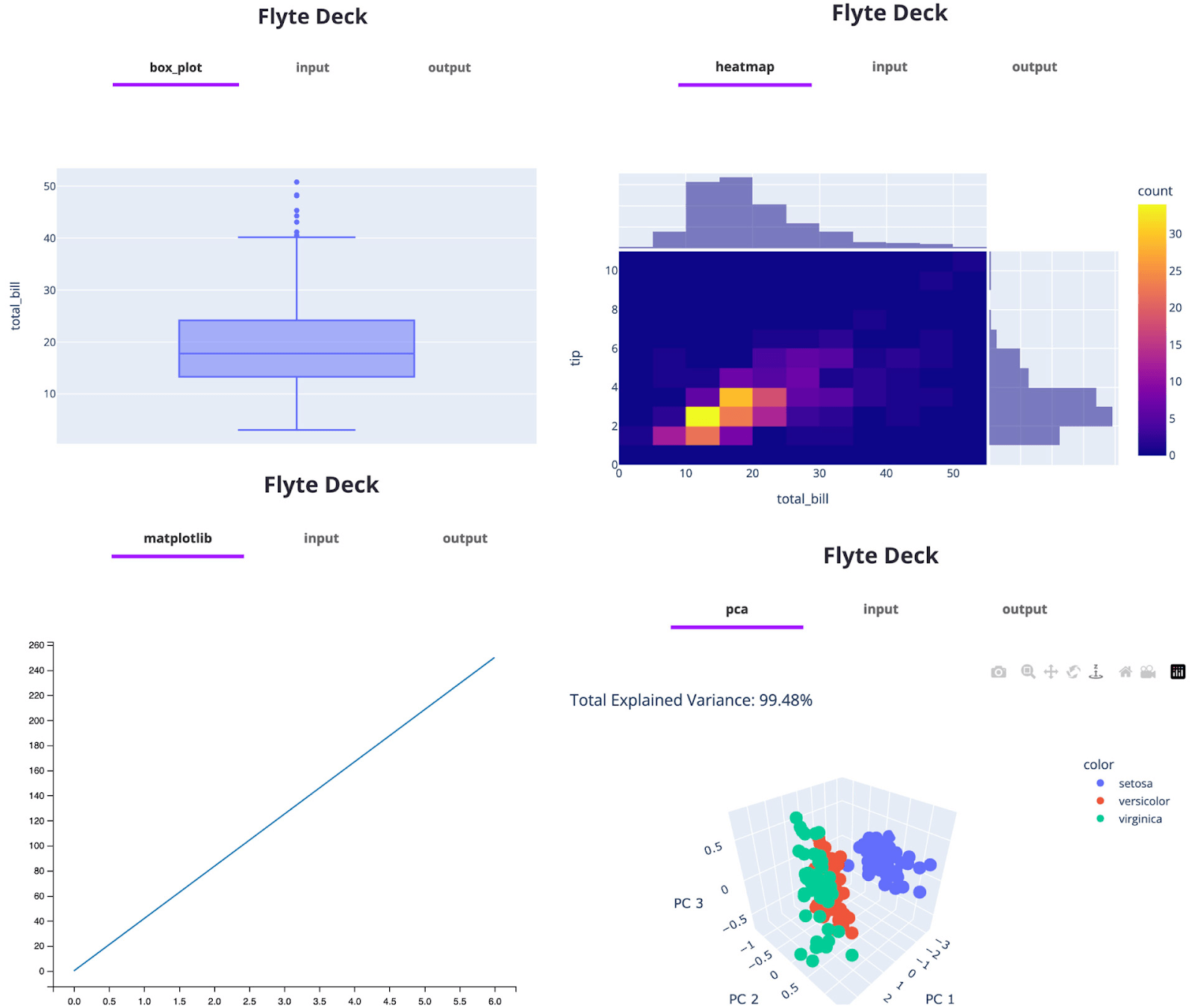
Apache Airflow
Apache Airflow does not provide built-in version control for data or artifacts. It treats tasks as ephemeral computations.
While Airflow has an internal metadata database for scheduling state and supports XCom for passing small pieces of data between tasks, it does not automatically track or version model artifacts or datasets.
To ensure data lineage or reproducibility in Airflow, you have to rely on manual techniques (for example, storing outputs in versioned S3 paths or using database migrations).
In short, Airflow leaves artifact management to you: it orchestrates jobs but does not record the inputs/outputs of those jobs beyond logs.
ZenML
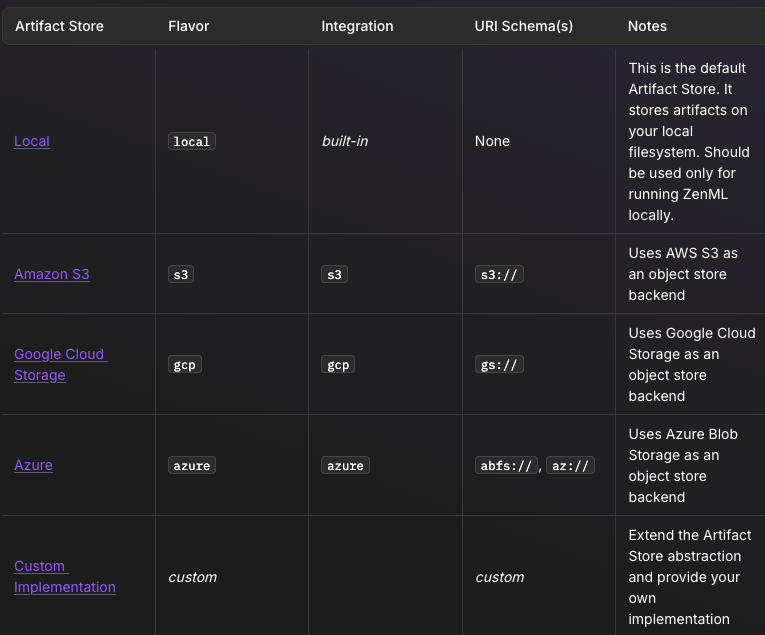
ZenML builds artifact tracking into its core. Every output produced by a ZenML step becomes a tracked artifact. These artifacts are stored in the configured artifact store, like S3, GCS, local filesystem, and recorded in ZenML’s metadata store. More importantly, ZenML automatically manages these artifacts and their lineage.
The system captures the relationship between each artifact and the steps that produced it, creating a full data lineage. This means that every dataset, model, or file generated during a pipeline run is versioned by ZenML. You can later retrieve artifacts from any previous run or inspect what data led to a particular model.
In practice, this makes ZenML pipelines reproducible: rerunning a pipeline with the same code and inputs will find matching artifacts and reuse them.
Bottom line: Flyte offers automatic versioning of all entities and data flowing through its strongly-typed workflows, providing deep lineage and reproducibility out of the box.
Airflow’s native capabilities are more focused on DAG versioning and task-level artifact storage, requiring external solutions or manual effort for full data versioning and end-to-end lineage.
ZenML provides robust, built-in artifact and data versioning through its metadata store and Model Control Plane, ensuring end-to-end lineage and reproducibility across pipeline runs, and it has the capability to integrate external data sources.
Feature 3. Experiment Tracking
Experiment tracking is a vital functionality for managing the iterative nature of ML developments. The functionality allows ML engineers and data scientists to log, compare, and reproduce results.
Flyte
Flyte doesn’t include a built-in experiment tracker. However, the platform offers a powerful UI called Flyte Deck. When enabled, Flyte Deck can visualize metrics and artifacts for your workflows.
For example, Flyte has an MLflow plugin that automatically logs metrics to the Flyte UI or to a real MLflow server.
Flyte can serve as an experiment monitor when you use its plugins or Deck. You can also manually call MLflow and other experiment trackers that integrate with Flyte from Flyte tasks. But unlike ZenML, Flyte does not bundle experiment tracking as a core concept – it’s available via integrations.
Apache Airflow
Airflow doesn’t provide dedicated experiment tracking capabilities. The platform focuses on workflow orchestration and execution monitoring rather than ML-specific experiment management.
Teams using Airflow for ML workflows typically integrate with external experiment tracking tools. Airflow can orchestrate experiment tracking workflows and integrate with platforms like MLflow, but the experiment tracking functionality comes from these external integrations.
ZenML
ZenML is designed with experiment tracking in mind. The platform logs pipeline metadata (parameters, artifact versions) in its metadata store, but it also provides first-class flavors for integrating with major trackers.
ZenML’s architecture separates the notion of an experiment tracker into optional stack components. It ships with connectors for MLflow, Weights & Biases, Comet, Neptune, and others.
When you enable an experiment tracker in a ZenML pipeline, the framework automatically logs metrics, parameters, and models to that service as steps execute.
For example, using the MLflow integration, ZenML will record each run’s metrics and push them to an MLflow tracking server.
What’s more, ZenML also provides a lightweight experiment concept by itself: every pipeline run is an experiment, and ZenML’s own metadata store keeps track of the results. This means you can query past runs, compare them, and tie them to artifacts in ZenML’s UI.
To sum it up, ZenML tightly integrates with experiment tracking tools, making it easy to have a visual history of all runs.
Bottom line: Flyte and Apache Airflow don’t offer experiment tracking as their primary functionality. There are, of course, workarounds and integrations you can leverage to track experiments, but a better solution is to use ZenML.
ZenML offers a highly flexible and extensible approach by integrating seamlessly with a wide array of best-in-class experiment trackers. This allows you to choose your preferred tool while maintaining a unified pipeline experience and leveraging ZenML’s built-in metadata management for end-to-end lineage.
Flyte vs Apache Airflow vs ZenML: Integration Capabilities
This section explores how easily each MLOps platform integrates with existing workflows, tools, and cloud services, highlighting their respective ecosystems and architectural approaches to connectivity.
Flyte
Flyte is Kubernetes-native, so it easily integrates with cloud and container platforms. Any Kubernetes cluster can serve as its execution environment, and Flyte can use any cloud object storage (e.g., S3, GCS) for data persistence.
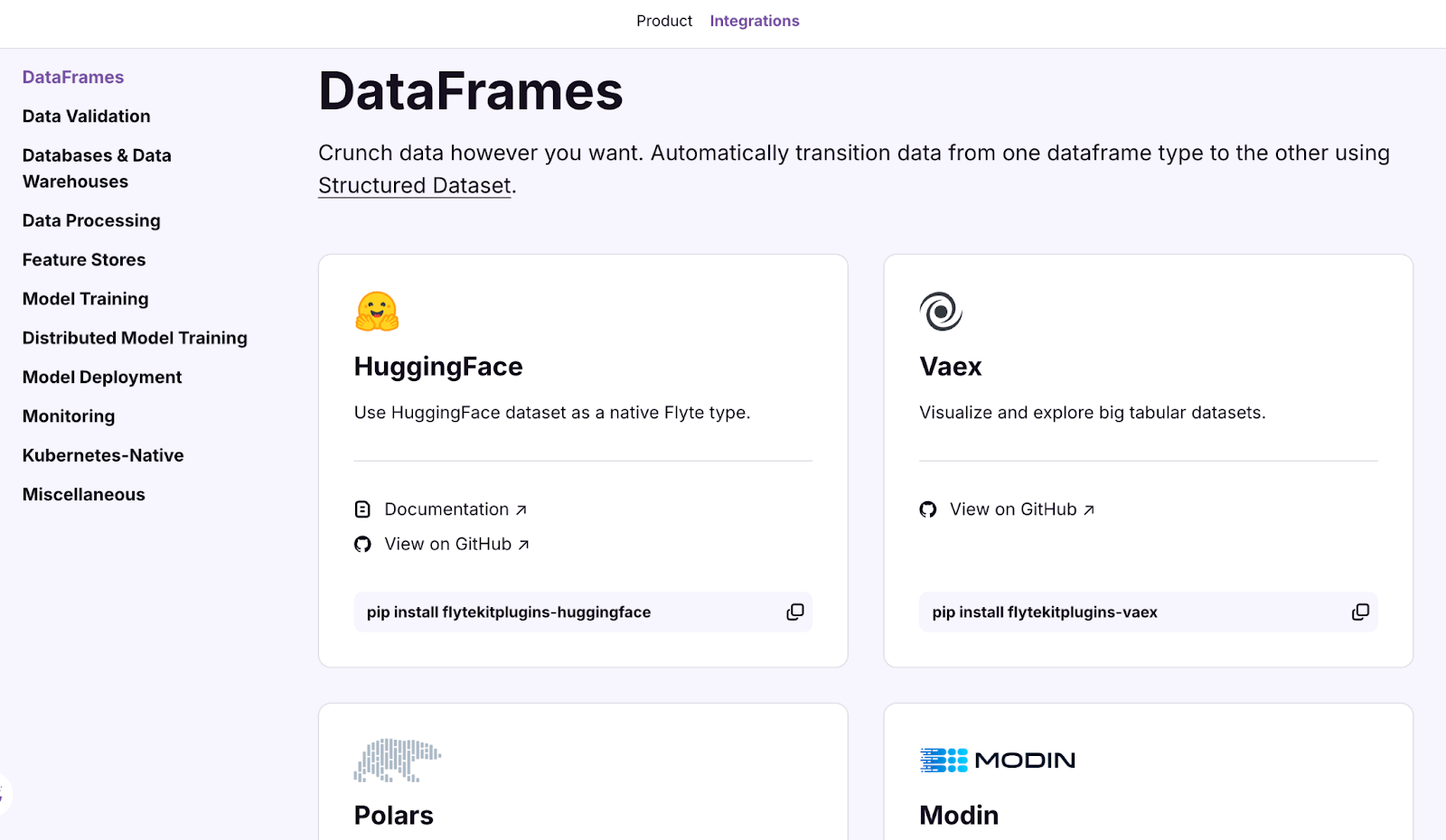
Here are all the different integrations you get with Flyte:
- DataFrames: HuggingFace, Vaex, Polars
- Data Validation: Great Expectations and Pandera
- Model Training: AWS Sagemaker
- Model Deployment: ONNX TensorFlow, PyTorch, and Scikit Learn
- Monitoring: MLflow and Whylogs
Apache Airflow
Apache Airflow has a vast and mature integration ecosystem, primarily through its extensive provider packages, operators, and hooks. It’s highly tool-agnostic and can orchestrate actions across a wide range of systems.
Airflow offers deep integration with major cloud platforms, including AWS, Google Cloud (GCP), and Microsoft Azure, with dedicated providers for services like SageMaker, Databricks, BigQuery, and Azure ML.
For ML/AI Tools, it integrates with MLflow, Weights & Biases, Cohere, OpenAI, Weaviate, OpenSearch, and various vector databases, allowing engineers to automate the end-to-end model lifecycle.
Airflow also provides connectors for numerous databases and data systems (PostgreSQL, MySQL, MSSQL, Oracle, MongoDB, etc.) and robust data transfer capabilities between different storage solutions.
The platform’s extensibility supports custom operators, sensors, and hooks, which allow you to extend functionality for specific needs. Airflow also exposes a REST API for external applications to integrate, further enhancing its connectivity.
ZenML
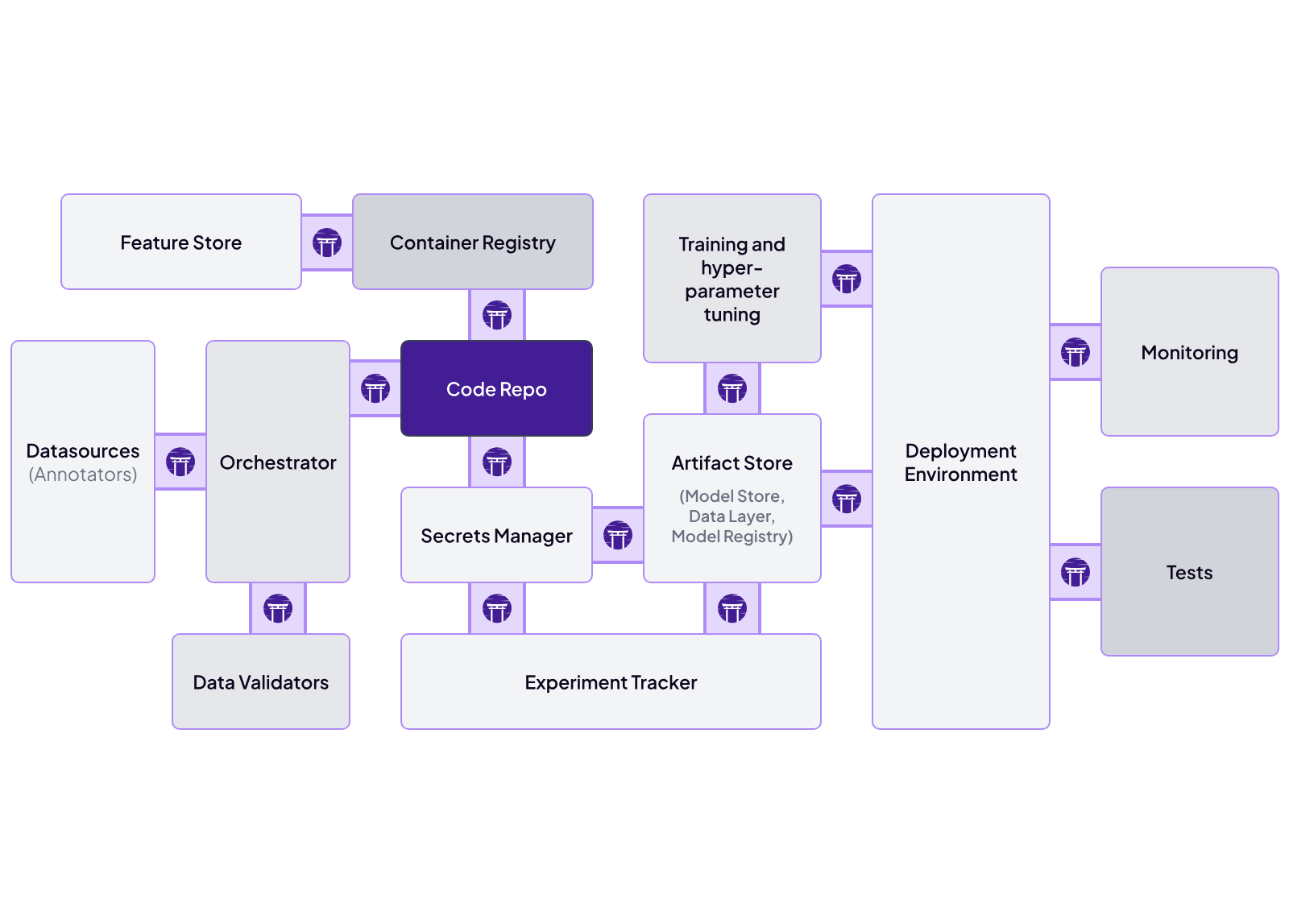
ZenML is designed to be integration-friendly at every layer. Its key abstraction is a stack: you plug in separate components for orchestration, artifact stores, metadata stores, and experiment trackers.
ZenML comes with 50+ built-in connectors across various MLOps categories - orchestrators, artifact stores, container registries, experiment trackers, model deployers, and cloud infrastructure.
- Artifact Store: S3, Azure Blob Storage, GSC
- Cloud Infrastructure: AWS, Google Cloud, Azure
- Container Registry: Azure, Elastic, GitHub, Google Artifact Registry
- Data Visualization: Facets
- Experiment Tracker: Comet, MLflow, Neptune, Weights & Biases
- Orchestrator: Docker, HyperAI, Kubeflow, Modal, Tekton

Flyte vs Apache Airflow vs ZenML: Pricing
This section details the pricing models for Flyte, Apache Airflow, and ZenML, covering their open-source availability and various managed service options.
Flyte
You can deploy Flyte on your own Kubernetes cluster (open source version) or use Union.ai for managed Flyte services.
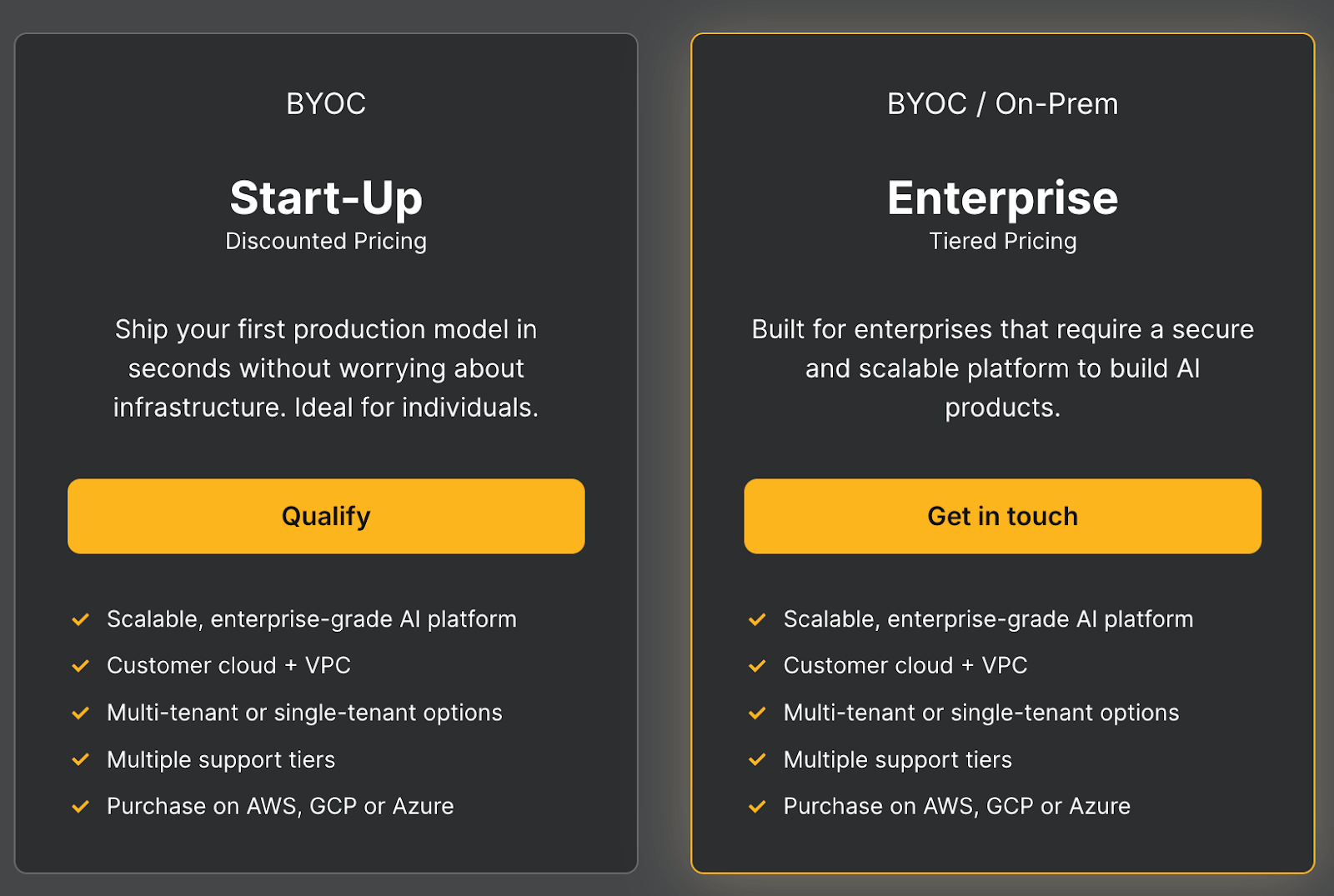
Union.ai offers a hosted Flyte cloud with usage-based pricing, so you pay for the resources you use. It also offers managed Flyte plans that you can deploy on your cloud and on-premises.
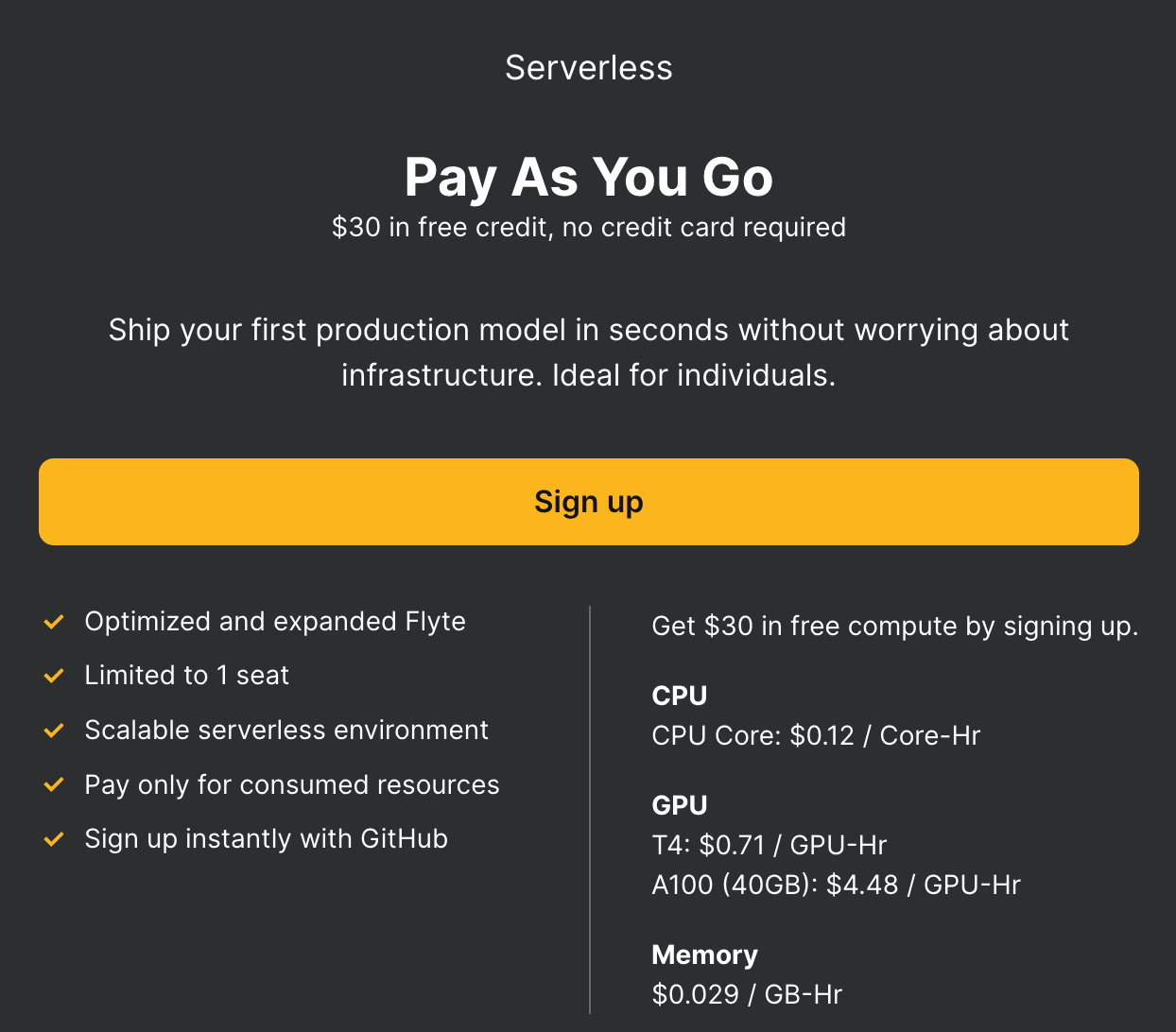
The ‘Our Cloud’ plan is pay-as-you-go and offers:
- $30 in free credit
- 1 seat
- CPU Core: $0.12/Core-hr
- GPU: TA - $0.71/GPU-hr and A100 (40GB) - $4.48/GPU-hr
- Memory: $0,029/GB-hr
And here are the plans you get with ‘Your Cloud and on-prem’ plan:
Apache Airflow
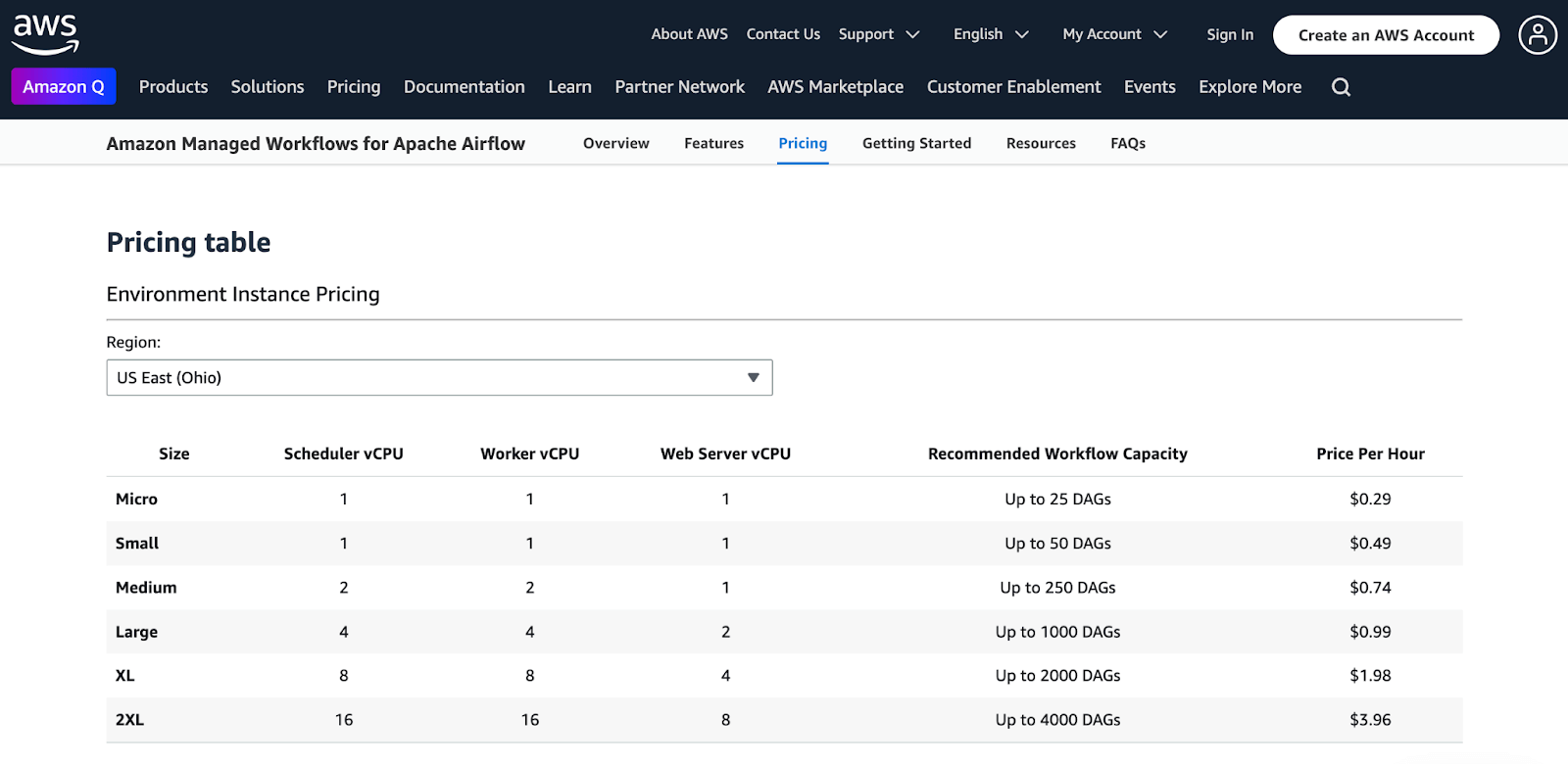
Apache Airflow is open-source and free for self-hosted deployments. You can run Airflow on your own infrastructure without licensing fees, though operational costs include compute, storage, and maintenance.
Managed Apache Airflow services are available from the AWS marketplace.
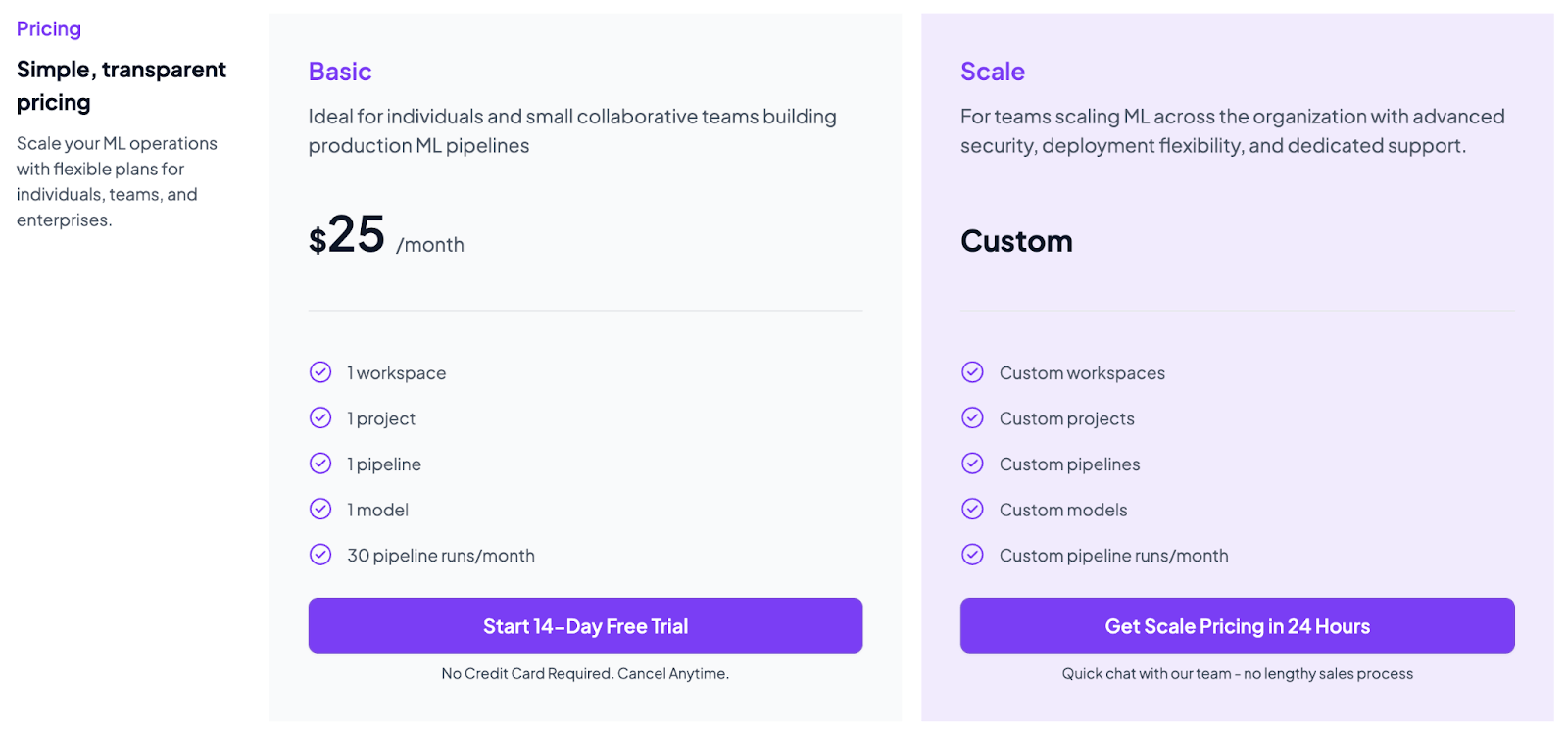
ZenML
ZenML provides an open-source core framework that is free to install and run. You can self-host ZenML (including its metadata store and any orchestrator) without any license fees.
The platform also offers ZenML Pro (a hosted control plane) with tiered plans.
What managed plans do is add convenience (shared UI, team collaboration, enterprise support), but the core pipeline engine has no charge.
There are two Pro plans you can choose from:
- Basic: $25 per month, where you get 1 workspace, 1 project, 1 pipeline, and 30 pipeline runs per month.
- Scale: Enterprise plan with custom pricing
Which MLOps Platform Should You Choose?
Choosing between Flyte vs Airflow vs ZenML depends on your priorities and context:
✅ Choose Flyte if you need cloud-scale ML pipelines with strong reproducibility guarantees. Flyte is excellent for you if you deploy on Kubernetes and require large parallelism, caching, and version control of workflows. If your team builds many large data/ML pipelines and cares about things like workflow rollbacks or auto-recovery, Flyte’s features can be compelling.
✅ Choose Apache Airflow if you already use it for data engineering and need a general-purpose workflow engine. Airflow’s strengths are its maturity, large community, and extensive operators. If your ML pipelines are one piece of a broader data/analytics system, Airflow may fit right in.
✅ Choose ZenML if you want an ML-centric, flexible framework that integrates easily with your existing tools. ZenML shines when your goal is to iterate quickly on pipelines in Python while still using the best infrastructure underneath. It’s particularly appealing if you want built-in artifact tracking and easy ML integrations without reinventing them. ZenML allows you to leverage the orchestration backend of your choice (e.g., you could even run ZenML on Airflow) and plug in MLOps platforms like MLflow or W&B for experiment tracking.
Stop wrestling with vendor lock-in and fragmented MLOps tools. ZenML Pro gives you the flexibility to use your favorite orchestrator (Airflow, Kubeflow, or local) while automatically handling artifact versioning, experiment tracking, and pipeline reproducibility. Want to give it a try? Sign up for the 14-day free trial, no credit card required.
📚 Relevant reading:
- Databricks alternatives: Top 10 alternatives to Databricks to eliminate the pain points you might face when using Databricks.
- MLflow alternatives: Discover the best MLflow alternatives designed to improve all your ML operations.
- Prefect Pricing: Know if Prefect pricing is worth investing.
- Outerbounds Pricing: Read this guide and know if Outerbounds is the right investment for you.


