On this page
Machine learning teams today have several MLOps frameworks to choose from, each covering different parts of the workflow. Metaflow, MLflow, and ZenML all aim to streamline ML pipelines, but they focus on different core problems.
This Metaflow vs MLflow vs ZenML article compares these platforms’ features, integrations, and pricing to help ML engineers and data scientists pick the best fit.
A quick note before we get started: We’ve not written this comparison to compare and conclude which one out of these three is the best MLOps platform. Instead, we educate you about how to leverage these platforms in tandem to increase efficiency.
Metaflow vs MLflow vs ZenML: Key Takeaways
🧑💻 Metaflow: The platform is a Netflix-built, open-source ML workflow framework. It lets you define complex pipelines in Python, debug locally, and run at scale on the cloud. Metaflow automatically versions data and code within each run, and supports running flows on AWS, Azure, GCP, or Kubernetes with minimal changes. It’s best suited for large-scale data pipelines and event-driven workflows.
🧑💻 MLflow: An open-source tracking and model lifecycle platform from Databricks. It provides APIs and a UI to log experiments (metrics, parameters, artifacts) and a Model Registry for versioning models. MLflow is framework-agnostic (supports TensorFlow, PyTorch, scikit-learn, etc.) and can run anywhere - local machines, Databricks, SageMaker, Azure ML.
🧑💻 ZenML: An open-source MLOps framework for portable, production-ready pipelines. ZenML lets you write normal Python code with @step and @pipeline decorators, and then run those steps on any backend, local, Airflow, Kubeflow, SageMaker, Vertex AI, etc. It provides built-in auto-logging of parameters and artifacts, and can plug into experiment trackers like MLflow, Weights & Biases, and more, for rich visualization.
Metaflow vs MLflow vs ZenML: Feature Comparison
A TL;DR for the feature comparison:
| Capabilities | Best-suited |
|---|---|
| Workflow orchestration |
|
| Experiment tracking |
|
| Artifact and data versioning |
|
| Production deployment |
|
| Integration ecosystem |
|
If you want to learn about how we came to the conclusions above, read ahead.
In this section, we compare Metaflow, MLflow, and ZenML across three key features:
- Workflow Orchestration
- Experiment Tracking
- Artifact and Data Versioning
For each feature, we highlight how the three tools carry out the process.
Feature 1. Workflow Orchestration
Workflow orchestration is a critical component of any MLOps strategy as it is the process of coordinating the execution of various steps in an ML pipeline.
Metaflow
Metaflow’s core feature is Python-based flow orchestration. You define a FlowSpec class with @step functions, and Metaflow handles execution. Run flows locally for quick iteration and then deploy them unchanged to the cloud.
Metaflow runs steps on AWS Batch (and can use AWS Step Functions to chain flows), but it also supports Kubernetes. In fact, there are integrations that help you deploy Metaflow pipelines to Apache Airflow, Agro Workflows, or other schedulers.
This means the platform can be orchestrated by your existing infrastructure: it generates an Airflow DAG or Step Functions workflow from the same Python code.
Metaflow includes retry and parallel execution features, and automatically manages resources via decorators. It’s primarily code-driven (has no built-in GUI), making it ideal for teams comfortable with Python and cloud infrastructure.
import time
from metaflow import FlowSpec, step, Config, timeout
class TimeoutConfigFlow(FlowSpec):
config = Config("config", default="myconfig.json")
@timeout(seconds=config.timeout)
@step
def start(self):
print(f"timing out after {self.config.timeout} seconds")
time.sleep(7)
print("success")
self.next(self.end)
@step
def end(self):
print("full config", self.config)
if __name__ == "__main__":
TimeoutConfigFlow()📚 Also read: Metaflow alternatives
MLflow
MLflow itself is not a full-fledged orchestrator. Its ‘Projects’ component lets you package ML code into a runnable format, and the UI/CLI can launch these jobs.
Recent MLflow versions introduced an (experimental) MLflow Pipelines framework, but it’s still fairly lightweight.
In practice, most teams use external tools (Airflow, Kubeflow, etc.) to schedule MLflow jobs. MLflow can run Python or R code locally or in Docker, and it integrates easily with platforms like Databricks, SageMaker, or Azure ML for orchestration.
But by design, MLflow does not enforce a workflow graph; it focuses on running one experiment (or model training) at a time and logging its results.
# MLflow manual usage
import mlflow
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("my_experiment")
with mlflow.start_run():
# Load and preprocess data
X, y = load_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Train model
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Log parameters
mlflow.log_param("n_estimators", model.n_estimators)
mlflow.log_param("max_depth", model.max_depth)
# Log metrics
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
mlflow.log_metric("accuracy", accuracy)
# Log model
mlflow.sklearn.log_model(model, "random_forest_model")
# Retrieve and print the run ID
current_run = mlflow.active_run()
print(f"MLflow Run ID: {current_run.info.run_id}")📚 Also read: Kubeflow vs MLflow
ZenML
ZenML is designed as a meta-orchestrator that can use many underlying orchestrators. You define pipelines in Python, but you then choose a backend - Databricks, Dagster, Flyte, Kubeflow, Kedro, etc. The platform handles scheduling the steps on that backend, including resource provisioning, step caching, and parallelism.
For example, ZenML lets you tag steps with @step and then run the pipeline on Kubeflow or in Docker, without changing the pipeline code. What’s more, ZenML also supports ‘step operators’ to run individual steps on specialized infrastructure (for example, one step on SageMaker, another on Vertex).
In short, ZenML’s orchestration provides flexibility: switch cloud providers or orchestrators on the fly, and ZenML will manage the execution. It treats the orchestrator as a pluggable component.
# zenml integration install kubeflow
# zenml orchestrator register kf_orchestrator -f kubeflow ...
# zenml stack update my_stack -o kf_orchestrator
from zenml import pipeline, step
@step
def preprocess_data(data_path: str) -> str:
# Preprocessing logic here
return processed_data
@step
def train_model(data: str):
# Model training logic here
return model
@pipeline
def my_pipeline(data_path: str):
processed_data = preprocess_data(data_path)
model = train_model(processed_data)
# Run the pipeline
my_pipeline(data_path="path/to/data")Bottom line: Metaflow provides robust Python-native workflow orchestration ideal for cloud-based, code-centric teams.
MLflow isn’t built for orchestration; it primarily supports experiment logging and requires external orchestration tools.
ZenML offers the most flexibility by acting as a meta-orchestrator, seamlessly running pipelines across multiple backends like Airflow, Kubeflow, or cloud platforms, without altering your pipeline code.
Feature 2. Experiment Tracking
Experiment tracking is a vital functionality to manage the iterative nature of ML developments. It allows ML engineers and data scientists to log, compare, and reproduce results.
Metaflow
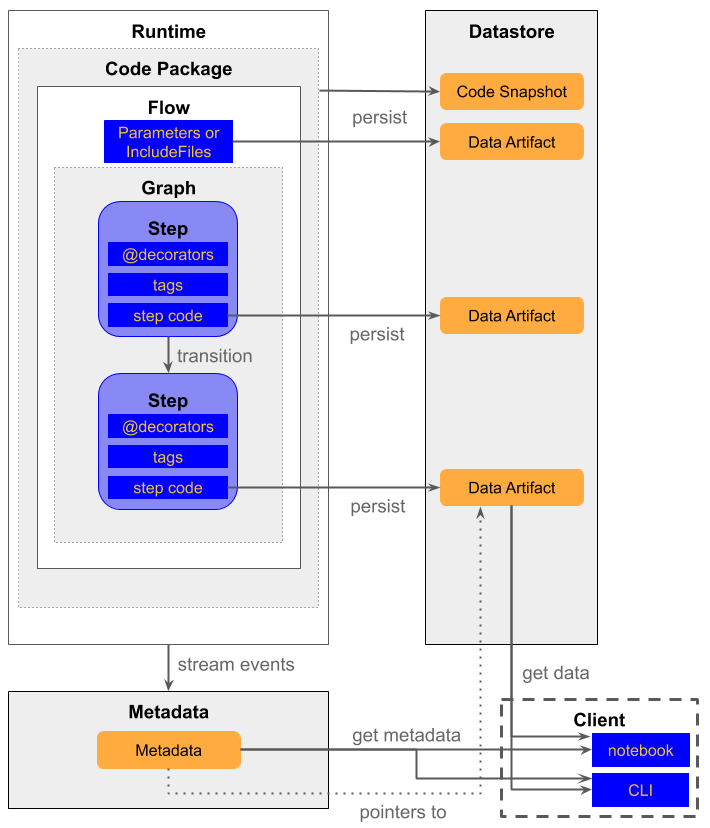
Metaflow automatically records the outputs and variables of each step. This data and code versioning happens behind the scenes: every run is logged to a data store, and your code is snapshotted. This means you can ‘checkout’ any run and inspect its results.
Metaflow’s built-in tracking is basic; its main interface is CLI, but Netflix has open-sourced an optional Metaflow UI service. With that, you get a dashboard to browse runs, parameters, and logs.
**👀 Note: **Netflix built Metaflow (Outerbounds), but it’s now a separate entity, and Netflix doesn’t manage the platform anymore.
In summary, Metaflow provides lineage by default (all step artifacts are versioned) and lets you inspect any run, but it relies on external tools (or its optional UI) for rich visualization.
MLflow
MLflow was built for experiment tracking. It provides a Tracking UI that lets you compare runs side-by-side, filter experiments by parameters, and view logged metrics and charts.
You log to MLflow by calling mlflow.log_param(), mlflow.log_metric(), or mlflow.log_artifact() in your code. All the data goes into a tracking server and an artifact store.
MLflow’s UI then makes this easy to query. It also includes a Model Registry: you can register a trained model under a name, version it, and record metadata like source code or training data references.
In practice, MLflow provides turnkey tracking and registry features, but you must run it within a notebook, script, or managed service (it does not auto-log anything without your code calling it).
📚 Also read: MLflow Alternatives
ZenML
ZenML has a flexible approach to tracking. By default, ZenML auto-logs a wealth of information from each pipeline run: parameters, metrics of each step, and hardware utilization.
You can also plug in any supported experiment tracker as a ‘stack component’ – for example, MLflow, TensorBoard, or W&B. These tools will then collect and visualize the same information with their familiar UIs.
On top of that, ZenML offers a Model Control Plane in its managed dashboard, which acts like a centralized model registry. This Model Control Plane lets you register models, version them, link them to pipelines and artifacts, and see their full lineage across runs.
In short, ZenML ensures every pipeline run (and its artifacts) is tracked, and it integrates with best-in-class UIs for visualization.
Bottom line: Metaflow offers automatic but basic experiment tracking and requires external tools or its optional UI for deeper insights.
MLflow is specifically designed for experiment tracking, providing comprehensive logging, visualization, and a model registry.
ZenML combines automatic logging with the ability to integrate external tracking tools like MLflow or W&B, providing both flexibility and centralized visualization via its Model Control Plane.
Feature 3. Artifact and Data Versioning
Effective artifact and data versioning are fundamental for reproducibility, debugging, and governance in machine learning.
Metaflow
Every piece of data that flows through a Metaflow pipeline is versioned. When a step produces an output, Metaflow saves it to the Metaflow Datastore (often on S3 or Blob storage) along with metadata.
The platform tracks data automatically: as you saw earlier, ‘Metaflow flows data across steps, versioning everything on the way.’
It lets you retrieve any step’s outputs from past runs by using the Metaflow client API.
Code versions are also captured – each run records the Git commit of your Flow code, so you can reproduce any experiment exactly.
In practice, Metaflow provides end-to-end lineage out of the box, but you may need to use its APIs or UI to explore it.
MLflow
MLflow’s artifact management is more manual. Each experiment run can log artifacts (machine learning models, images, data files) to a configured storage location.
For example, mlflow.log_artifact("model.pkl") will upload that file under the run’s directory in S3 or Azure Blob.
The Model Registry holds model binaries and their metadata, effectively versioning models.
MLflow doesn’t inherently version your datasets – if you want to track data versions, you have to log them as artifacts or use external versioning.
What’s more, the platform’s functionality lets you persist any artifacts per run, tie them to the run ID, and its registry versions model artifacts, but it does not automatically capture the lineage between steps or manage raw data versions.
📚 Also read: MLflow vs Weights & Biases
ZenML
ZenML provides robust artifact versioning and lineage. Every pipeline run’s outputs are saved in ZenML’s metadata store, which automatically snapshots the artifacts and parameters. This means ZenML inherently versions all pipeline artifacts and data.
Moreover, the Model Control Plane ties everything together: a ZenML Model is a logical grouping of related artifacts (weights, metrics, training data) for a specific use case. You register models, and ZenML will record which pipeline version and artifacts produced each model.
This gives end-to-end lineage: you see exactly which code, data, and parameters generated any model version. In practice, ZenML’s lineage visualization makes it easy to trace an artifact from the final model back through each step of the pipeline.
Creating artifacts with ZenML needs just a few lines of code:
from zenml import pipeline, step
import pandas as pd
@step
def create_data() -> pd.DataFrame:
"""Creates a dataframe that becomes an artifact."""
return pd.DataFrame({
"feature_1": [1, 2, 3],
"feature_2": [4, 5, 6],
"target": [10, 20, 30]
})Bottom line: Metaflow automatically versions data and code artifacts with each pipeline step, giving full lineage without extra configuration.
MLflow provides artifact logging capabilities, including robust model versioning through its registry, but does not inherently handle dataset versioning or step-by-step lineage.
ZenML delivers comprehensive artifact versioning and end-to-end lineage through its metadata store and Model Control Plane, tying together data, code, and models within its pipelines.
Metaflow vs MLflow vs ZenML: Integration Capabilities
With integration capabilities, you get to know how easily an MLOps platform fits into existing workflows and tools.
Metaflow
Metaflow integrates deeply with cloud infrastructure. It was originally built on AWS and still has first-class support there. However, Metaflow is cloud-agnostic, so you can deploy it on Google Cloud (GKE + Cloud Storage) or Azure (AKS + Blob Storage) without changing code. It also lets you run Metaflow on any Kubernetes cluster or on-premises setup.
On the tooling side, Metaflow has connectors to several Python libraries - TensorFlow, PyTorch, Pandas, etc.

MLflow
MLflow is designed to integrate with the ML ecosystem. It has plugin APIs so that any library can log to MLflow. In practice, MLflow provides autologging hooks for many frameworks: a few lines of code will automatically record TensorFlow, PyTorch, XGBoost, or scikit-learn metrics and models.
It also integrates with Databricks (where it originated), Databricks offers Managed MLflow, and with cloud ML services.
What’s more, MLflow can use any database for its backend store and any blob storage for artifacts. This flexibility means MLflow can fit into most tech stacks with minimal effort.

ZenML
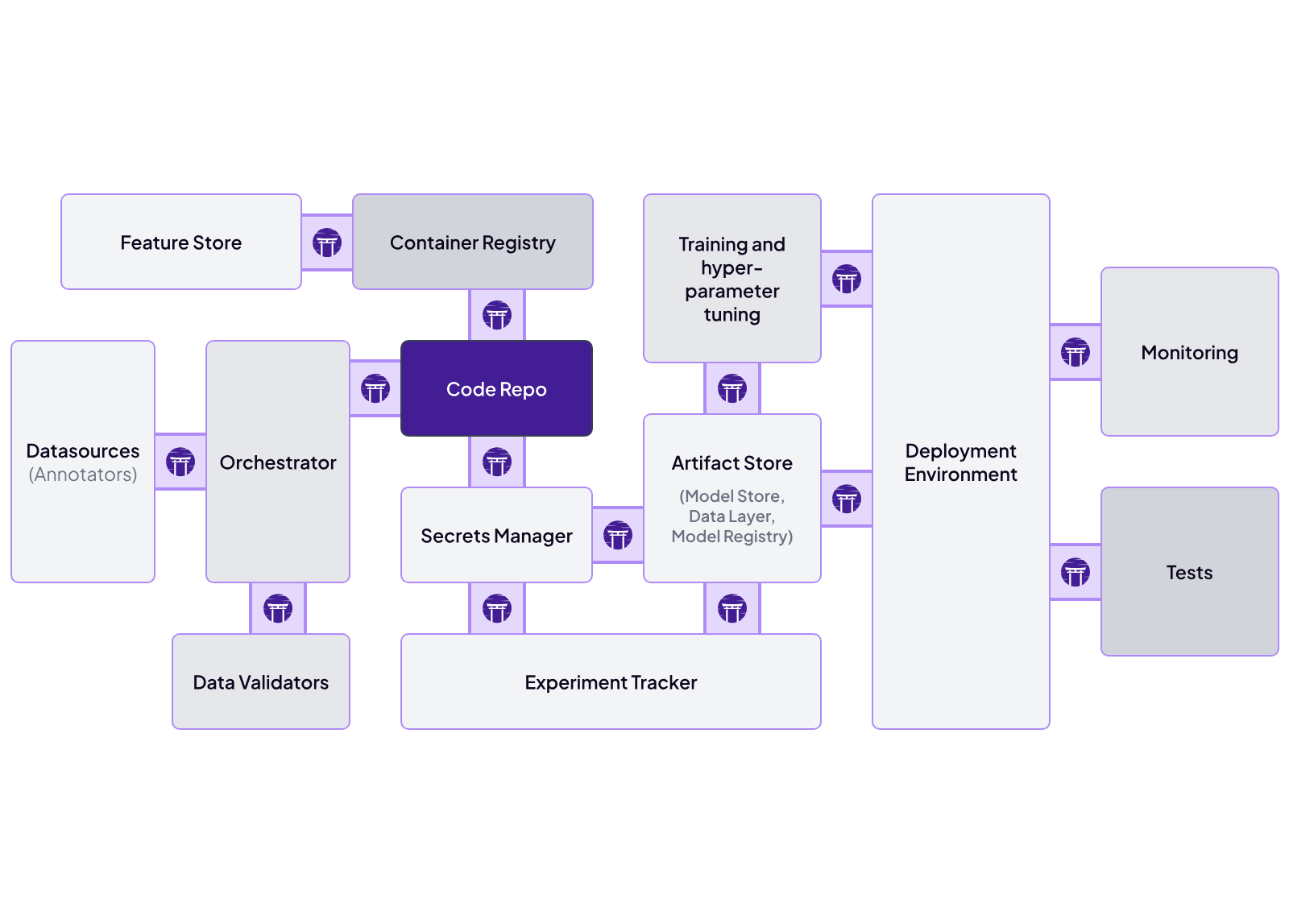
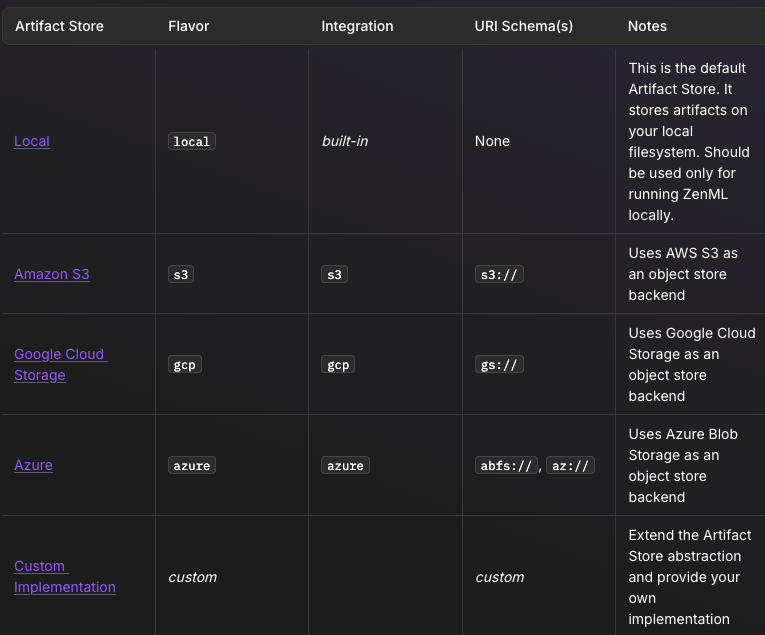
ZenML is fundamentally designed to be an integration-friendly MLOps framework. Its architecture is built around a pluggable ‘stack’ concept, where every major part of the MLOps lifecycle is abstracted as a stack component with multiple flavors.
Our platform offers 50+ out-of-the-box connectors to MLOps tools. Below are some notable integrations:
- Orchestrators: Airflow, Lightning AI, Databricks, Docker
- Artifact store: Amazon S3, Azure Blob Storage, Google Cloud Storage
- Cloud infrastructure: AWS, Google Cloud, Azure
- Experiment tracking: Comet, Weights & Biases, MLflow
ZenML acts like a meta-orchestrator: your ZenML pipeline can invoke pipelines on other platforms. This gives you huge flexibility – you’re not locked into one vendor or service.

Bottom line: Metaflow excels in cloud-native integrations, particularly strong with AWS but cloud-agnostic enough to adapt smoothly to GCP or Azure setups.
MLflow integrates with major ML frameworks and cloud platforms, offering rich auto-logging and flexible backend options.
ZenML stands out from the other two as it provides extensive out-of-the-box integrations. It acts as a meta-orchestrator that allows teams to effortlessly combine with over 50 best-of-the-breed MLOps tools.
Metaflow vs MLflow vs ZenML: Pricing
All three - Metaflow, MLflow, and ZenML have both open-source plans that are free to use and managed services that are paid.
Metaflow
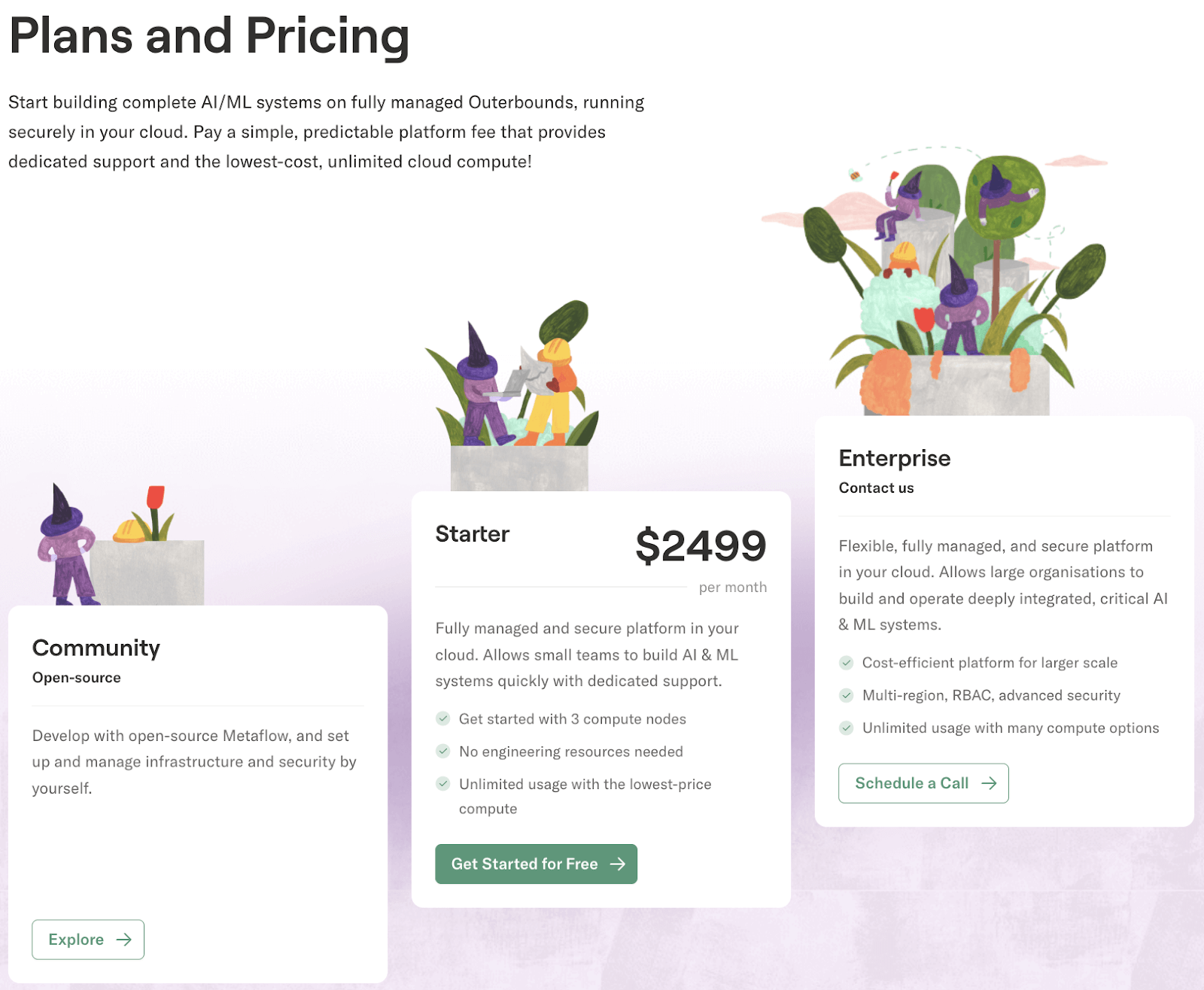
The core Metaflow framework is open-source and free (Apache 2.0). For managed services, the main offering is Outerbounds Platform, which provides a hosted Metaflow with UI and support. Outerbounds has a starter plan at $2,499 per month and a customer Enterprise plan.
Another way to purchase and deploy Outerbounds is via some major cloud marketplaces. The platform is available on AWS, Google Cloud, and the Azure marketplace.
MLflow
MLflow is open-source and free to deploy on your own infrastructure. For managed offerings, pricing depends on the platform:
- Databricks MLflow: Included in Databricks Compute, billed by DBU usage.
- AWS SageMaker MLflow: SageMaker offers an MLflow setup where a small instance (ml.t3.medium) is about $0.642 per hour (plus storage costs).
- Azure ML with MLflow: MLflow tracking is built into Azure ML; you pay for Azure ML compute and storage (no separate MLflow fee).
- Nebius Managed MLflow: Nebius offers dedicated MLflow clusters; a 6 vCPU / 24 GB RAM cluster costs about $0.36/hour.

In short, self-hosting MLflow only costs your compute/storage fees, and all major cloud ML platforms include MLflow as part of their services (billed under their standard pricing)
ZenML
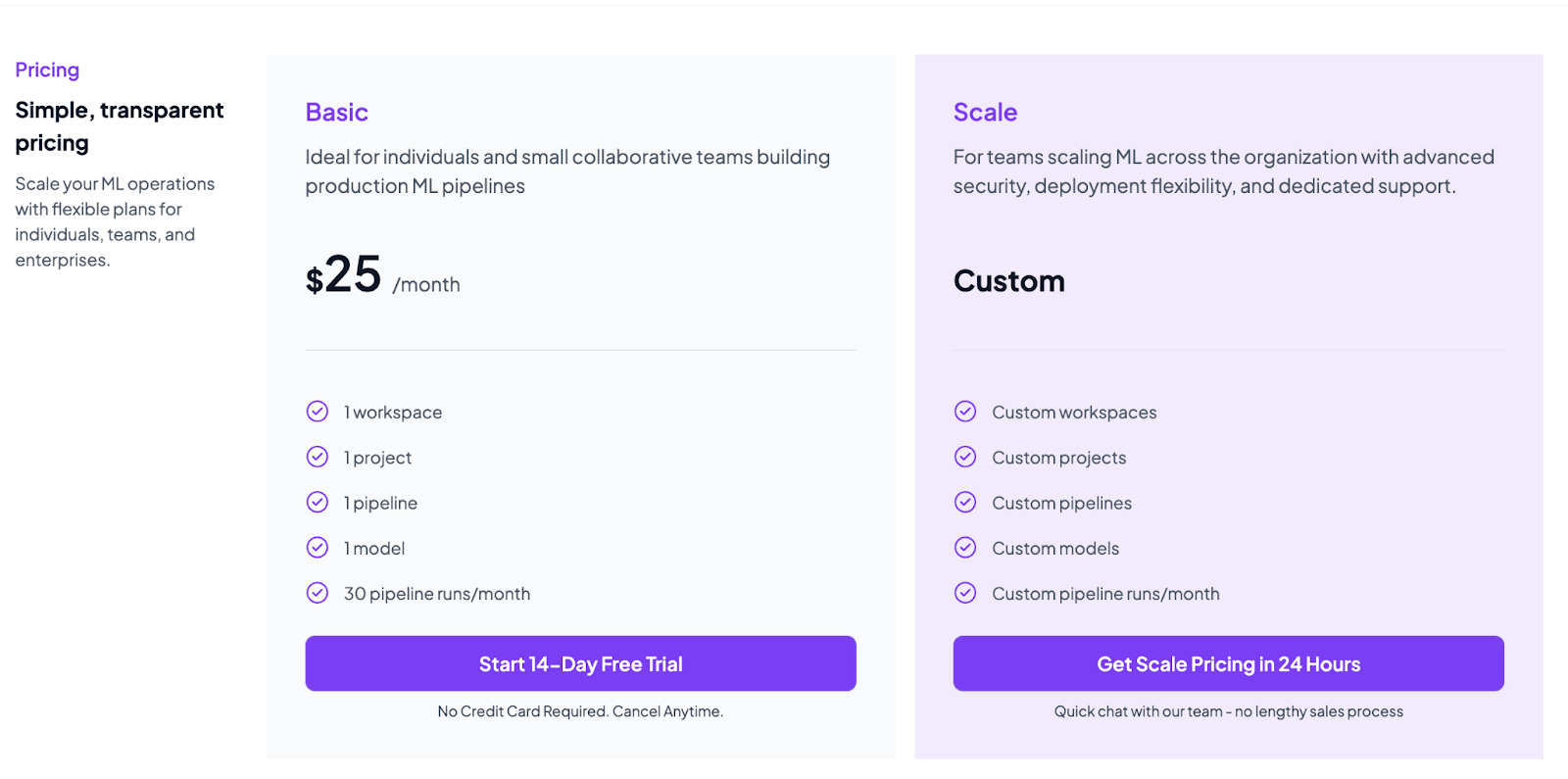
ZenML’s core framework is open-source and free to use. For its managed service (ZenML Pro), there are two main pricing tiers: Basic at $25 per month and Scale with custom pricing.
The Basic plan includes one workspace, one project, one pipeline, and up to 30 runs per month. A 14-day free trial is available (no credit card needed).
If you’re interested in signing up for the Scale Plan, contact us to tell us what you need; we will provide you with a customized plan and pricing.
📚 Also read:
Which of These Three MLOps Platforms Should You Choose?
Selecting an MLOps platform between Metaflow vs MLflow vs ZenML depends on your specific needs.
✅ Choose Metaflow to build robust, Python-native pipelines at scale. The platforms can handle complex data preprocessing or training workflows that must run reliably in production. For example, a large streaming company might use Metaflow to orchestrate nightly retraining of recommendation models on petabytes of data – it handles retries, parallelism, and cloud bursts automatically.
✅ Choose MLflow if your focus is on experimentation and model lifecycle. MLflow is ideal for data science teams who want an easy way to log experiments, compare runs, and manage a central model registry. It’s especially beneficial if you use Databricks or already have a Spark stack, since MLflow integrates seamlessly there.
✅ Choose ZenML if you want a unified solution that spans both worlds. ZenML lets you write pipelines and handle orchestration like Metaflow, while also giving you the option to log runs like MLflow. In fact, ZenML can use MLflow under the hood: configure ZenML to log to MLflow. The platform is built to ‘bridge the gap between experimentation and production’ – it supports both heavy-duty orchestration and easy tracking in one framework.
Want to experience the power of a unified MLOps platform that bridges the experimentation and production gap with 50+ integrations? Book a personalized demo call with our Founder and explore multiple ways how ZenML can cater to your MLOps teams better than any other workflow orchestration platform.