

On this page
Building AI applications with agentic workflows where large language models (LLMs) autonomously orchestrate tools, data retrieval, and multi-step reasoning has become a key challenge for ML engineers.
Two popular frameworks have emerged to streamline this process: LlamaIndex and LangChain.
In this LlamaIndex vs LangChain comparison guide, we compare both platforms in depth, focusing on how each supports agentic AI workflows. We break down their approaches to orchestration, agent building blocks, observability, integrations, and more, to help you decide which framework fits your needs.
👀 Note on LangChain and LangGraph: While this comparison frames LlamaIndex and LangChain side by side, it’s worth pointing out that the LangChain team now positions LangGraph as the primary way to build agentic workflows within the LangChain ecosystem. In fact, even the official LangChain quickstart guides often use LangGraph constructs by default when demonstrating agent orchestration. In practice, this means the gap between LangChain and LangGraph is slim; LangGraph is essentially the modern agent framework of LangChain, and much of its functionality overlaps with what we’ll cover in this article.
LlamaIndex vs LangChain: Key Takeaways
**🧑💻 **LlamaIndex: Go-to framework for data-intensive agentic workflows. Its fundamental strength lies in deep integration with a vast array of data sources, advanced RAG capabilities, and a flexible, event-driven orchestration model called Workflows.
**🧑💻 **LangChain: A comprehensive ‘LLM application framework’ known for its modular design and wide-ranging capabilities. LangChain provides many building blocks, models, prompts, memory, tools, chains, and agents that developers can mix and match to create complex agent systems.
LlamaIndex vs LangChain: Framework Maturity and Lineage
The maturity and development history of LlamaIndex and LangChain set expectations for stability, ecosystem depth, and long-term support. The table below compares key metrics.
| Metric | LlamaIndex | LangChain |
|---|---|---|
| First public release | November 2022: Launched as ‘GPT Index,’ later rebranded to LlamaIndex. | October 2022 |
| Pricing | Open source + managed services | Open source + managed services |
| GitHub stars | ~44.1K | ~115K |
| Forks | ~6.3K | ~18.9K |
| Commits (repo history) | ~7,022 | ~14,099 |
| Core orchestrator | Workflows: event-driven, async steps, and typed events | LangGraph: state, nodes, edges with conditional routing and cycles |
👀 Note: Metrics are from project GitHub pages viewed on September 8, 2025; numbers might change over time.
While LangChain leads in terms of GitHub stars, forks, and ecosystem size, it also comes with the complexity of a large, rapidly evolving codebase. Its head start since October 2022 has allowed it to establish itself as the most recognizable LLM application framework, with a growing set of primitives and a vibrant contributor community.
LlamaIndex, first launched as GPT Index in November 2022, has grown steadily into a specialized framework focused on data integration and retrieval-augmented generation (RAG). With over 44K GitHub stars and 300+ connectors through LlamaHub, it has become the default choice for data-centric agentic applications.
LlamaIndex vs LangChain: Features Comparison
To understand how LlamaIndex and LangChain stack up for agentic AI development, we’ll compare their capabilities across several core features:
| Feature | LlamaIndex | LangChain |
|---|---|---|
| Orchestration Model | Workflows: event-driven, async steps with typed events for flexible branching and parallel tasks. | LangGraph: stateful graph with nodes and conditional edges, supports loops for iterative agents. |
| Agent Primitives and Patterns | Built around Indexes and Query Engines; supports ReAct and function-calling agents. Strong for data-heavy workflows. | Wide library of Tools and Chains; includes prebuilt agents for faster prototyping. |
| Observability and Evaluation | CallbackManager with native integrations (Langfuse, W&B, Phoenix) and built-in RAG evaluation. | LangSmith platform for tracing, debugging, and automated evaluation with test sets and metrics. |
| Structured Outputs | Pydantic Programs with output_cls or custom structured_output_fn; strong JSON validation and retries. | Output Parsers + Pydantic support; integrates with model-native function calling. |
| Pricing | Open-source (MIT). Managed: Free (10k credits) Starter $50/mo (50k credits) Pro $500/mo (500k credits) Enterprise: Custom | Open-source (MIT). Managed: Free (10k nodes/mo) Developer (100k nodes) Plus ($0.001/node) Enterprise: Custom |
👀 Note: Both frameworks cover additional aspects like memory management. LlamaIndex can store chat history in SQLite or vector memory, while LangChain offers various short and long-term memory utilities. However, the table above highlights the most salient differences for building agentic systems.
Next, we delve deeper into each feature area and how LlamaIndex and LangChain handle them.
Feature 1. Orchestration Model
Orchestration is how you define the control flow of an agent: the sequence of steps, branching logic, and concurrency that transform a basic LLM into a reliable multi-step agent. LlamaIndex and LangChain approach orchestration differently.
LlamaIndex Relied on Event-Driven Orchestration

LlamaIndex approaches orchestration with its Workflows module, an event-driven, async-first framework designed to manage complex, multi-step processes. The platform leverages this approach specifically to overcome the rigidity of DAGs, offering a more flexible and Pythonic way to build agentic systems.
The architecture is composed of two primary building blocks :
- Events: These are
Pydanticmodels that carry data and serve as triggers for different parts of the workflow. The framework defines specialStartEventandStopEventclasses to mark the boundaries of the workflow's execution. You then create custom events to pass information between steps. - Steps: These are asynchronous Python functions decorated with
@step. Each step is designed to handle one or more specific event types and can emit new events to trigger subsequent steps. The framework cleverly uses Python's type hints to automatically route an emitted event to the correct step function that is ‘listening’ for it.
The standout feature of this model is its asynchronous-first nature. This design makes Workflows a natural fit for modern web applications built with frameworks like FastAPI and enables highly efficient parallel execution of independent tasks.
📚 Other LlamaIndex articles to read:
LangChain Uses LangGraph and Chains
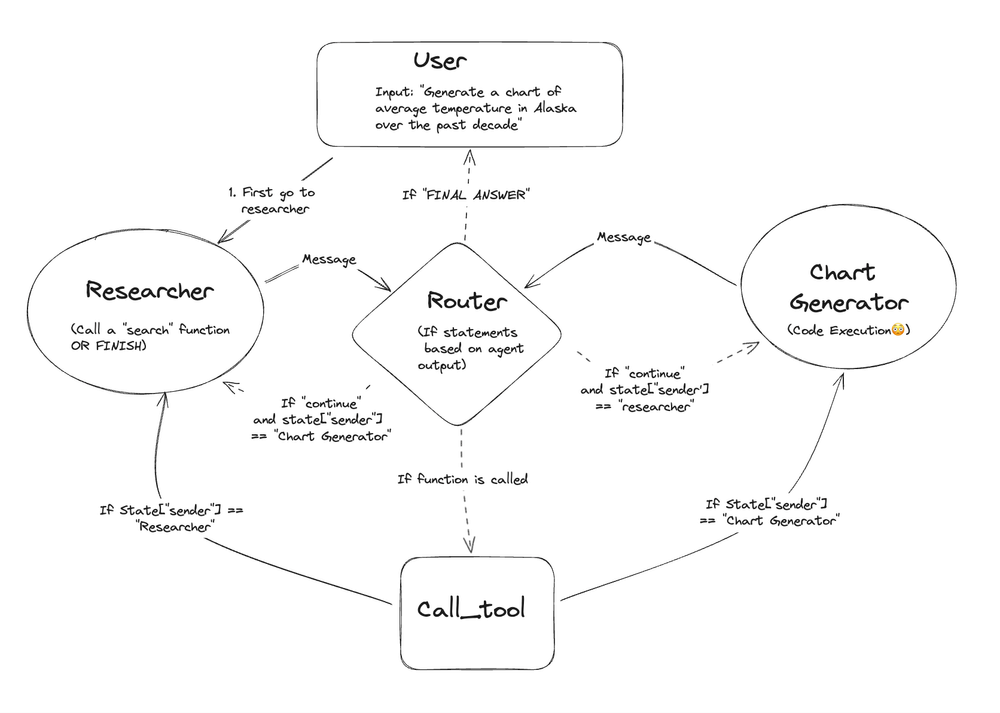
LangChain’s answer to the limitations of linear chains and Directed Acyclic Graphs (DAGs) is LangGraph, a library designed specifically for building resilient language agents as graphs. This model provides a structure that is both powerful and predictable.
The architecture is built on three core components :
- State: This is the central, shared data structure that persists throughout the workflow's execution. It acts as the agent's memory at any given moment and is typically defined using Python
TypedDictor aPydanticmodel. - Nodes: These are the ‘workers’ of the graph. Each node is a Python function or a LangChain Runnable that performs a specific action, like calling an LLM, executing a tool, or processing data. After executing, a node returns an update to the state.
- Edges: These are the ‘directors’ that connect the nodes, defining the flow of control. LangGraph's power is most evident in its
conditional_edges. These are special edges that execute a function to inspect the current state and dynamically decide which node to run next.
A critical advantage of this model is its native support for cycles. Unlike traditional DAGs, which prohibit loops, LangGraph is designed for them. This is fundamental for creating true agentic behavior, like self-correction, reflection, and iterative refinement, where an agent can loop through a series of steps until a specific goal is achieved.
Feature 2. Agent Primitives and Patterns
It takes several components to create an agentic AI: LLMs, tools (like web search or calculators), memory, etc., and defining how the agent decides to use them. Here’s how LlamaIndex and LangChain differ in the building blocks and patterns they offer for agent development.
LlamaIndex: Indices, Tools, and Lightweight Agents
LlamaIndex’s origin as a RAG (Retrieval-Augmented Generation) toolkit shows in its agent primitives. The fundamental objects are Indexes - data structures for storing text + embeddings, and Query Engines that use those indexes to answer questions.
In an agent context, these become powerful tools. For example, a LlamaIndex agent can have a tool that queries a document index for information.
LlamaIndex provides a variety of index types (vector index, list index, keyword table, etc.) and a simple interface to turn them into tools; for example, QueryEngineTool with a description that an agent can call./
from llama_index.core.tools import ToolMetadata
from llama_index.core.tools.eval_query_engine import EvalQueryEngineTool
query_engine_tools = [
EvalQueryEngineTool(
evaluator=evaluator,
query_engine=lyft_engine,
metadata=ToolMetadata(
name="lyft",
description=(
"Provides information about Lyft's financials for year 2021. "
"Use a detailed plain text question as input to the tool."
),
),
),
EvalQueryEngineTool(
evaluator=evaluator,
query_engine=uber_engine,
metadata=ToolMetadata(
name="uber",
description=(
"Provides information about Uber's financials for year 2021. "
"Use a detailed plain text question as input to the tool."
),
),
),
]On the agent logic side, LlamaIndex introduced support for ReAct agents and function-based agents to complement its data abilities. There’s an OpenAI FunctionCallingAgent that leverages OpenAI’s function-calling API to decide when to invoke a tool.
There’s also a ReActAgent implementation that uses the classic Reasoning + Act prompting loop, which can work with any chat LLM.
A key difference is that LlamaIndex does not come with as many pre-baked ‘agent personas’ or chains as LangChain. Instead, it gives you the lower-level components to construct what you need.
Common Patterns in LlamaIndex: One pattern is the retrieval QA agent, whose main job is to fetch info from documents.
Another pattern is the central Orchestrator agent that breaks a user query into sub-tasks for specialist tools/agents. This was introduced with AgentWorkflow in llama-agents, where one ‘brain’ agent delegates to others.
LangChain: Tools, Chains, and Agent Templates
LangChain, by design, offers a smorgasbord of agent primitives.
LangChain comes with an extensive library of tools like search engines, calculators, translators, APIs for services like Wolfram Alpha, etc. If something isn’t built-in, you can easily wrap a Python function or an API call as a Tool by providing a name, description, and a callable.
Agents in LangChain are essentially loops where the LLM observes the state and chooses a tool to act with next, so having a rich set of tools is crucial.
Then there are Chains, which can be thought of as predetermined sequences of steps.
For example, a simple LLMChain is just a prompt → LLM → output.
A SequentialChain might take the output of one chain and feed it to the next.
from langgraph.graph import START, StateGraph
builder = StateGraph(State)
# Add nodes
builder.add_node(step_1)
builder.add_node(step_2)
builder.add_node(step_3)
# Add edges
builder.add_edge(START, "step_1")
builder.add_edge("step_1", "step_2")
builder.add_edge("step_2", "step_3")Chains are building blocks that you can use to handle parts of an agent’s task.
What’s more, LangChain provides prebuilt agent templates that implement common patterns. The most famous is the ReAct agent (AKA zero-shot-react-description in the API), which uses a prompt format combining thought and action and can operate with any list of tools.
Memory is also a first-class primitive in LangChain. You can attach a Memory object to an agent or chain to automatically manage context – e.g., a ConversationBufferMemory to remember recent dialogue turns, or a VectorStoreRetrieverMemory to do RAG-style recall of facts.
What this means is that you don’t have to wire up storing and retrieving conversation history manually; the agent’s prompt will include memory if configured.
Common Patterns in LangChain: Besides ReAct, we see Plan-and-Execute, where one agent generates a multi-step plan and another executes it.
Another pattern is Tool-using question answering, where the agent uses a search tool, then a lookup tool, and multi-agent conversational simulations.
Feature 3. Observability, Tracing, and Evaluation
In a production environment, you need to monitor what your AI agents are doing: Are they choosing the right tools? How long are the steps taking? Why did a particular chain of thought fail? You also want to evaluate their performance, either through automated metrics or user feedback.
LlamaIndex and LangChain have different approaches here, reflecting their ecosystem.
LlamaIndex: Integrations and Tracing
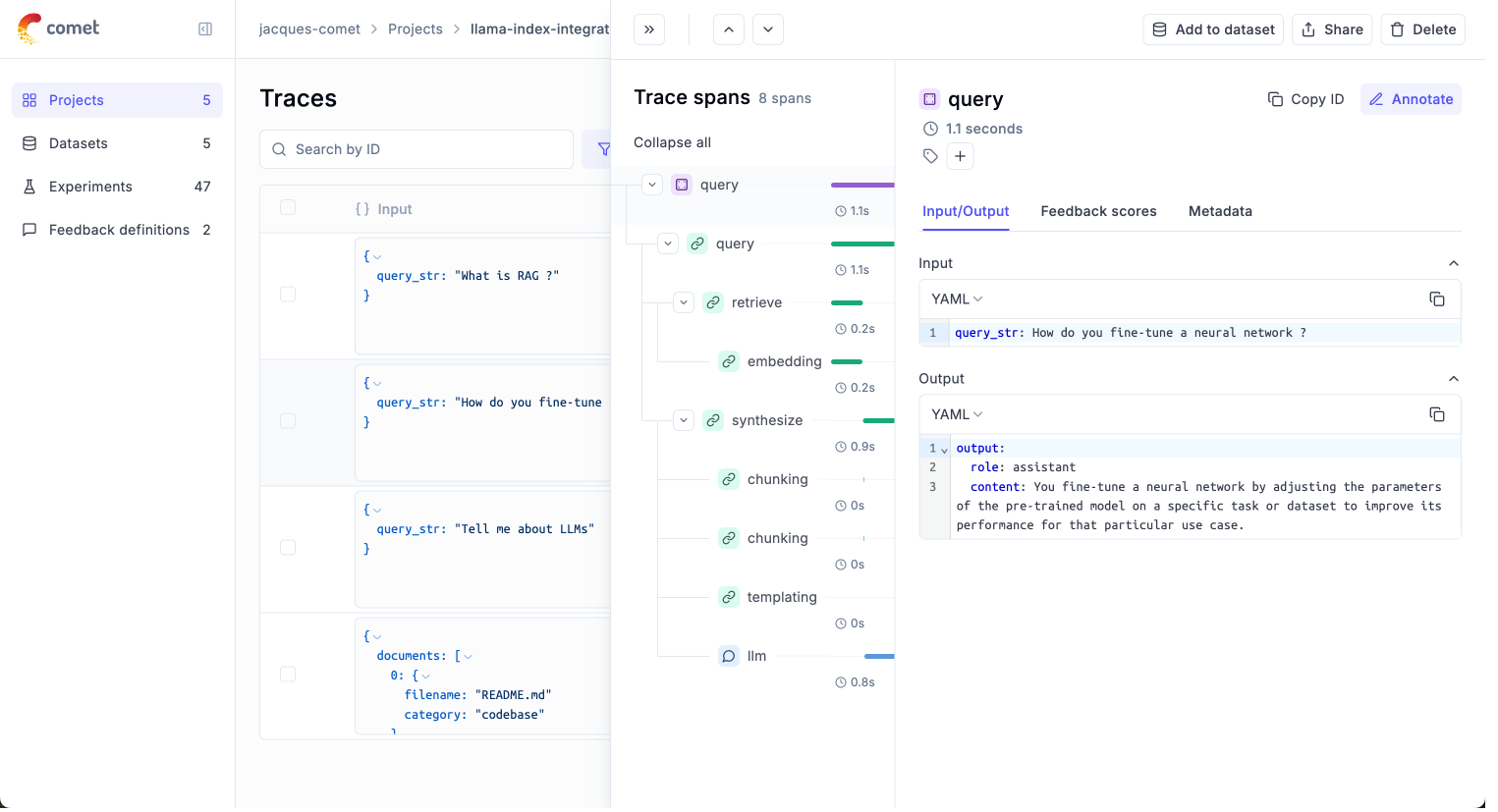
LlamaIndex champions a ‘best-of-breed’ philosophy for observability. Instead of a single first-party tool, it provides ‘one-click observability’ through its CallbackManager, which integrates with a wide range of leading third-party tools.
Key integrations and features include:
- Callback Handlers: This is the core mechanism for observability in the framework, allowing traces and events to be sent to external platforms.
- Leading Partner Tools: LlamaIndex has strong, native integrations with platforms like Langfuse, Arize Phoenix, and Weights & Biases. These tools offer sophisticated tracing, evaluation, and performance monitoring capabilities tailored for LLM applications.
- Built-in RAG Evaluation: The framework also includes its own modules specifically for evaluating RAG pipelines, focusing on critical metrics like faithfulness (is the answer supported by the context?) and relevancy.
When it comes to evaluation, LlamaIndex doesn’t (yet) have a full evaluation suite like LangSmith, but you can leverage its primitives to build one.
One area LlamaIndex does help with is token counting and cost estimation. Since it often manages the prompts for you, it can compute how many tokens were used in, say, answering a query and thereby estimate the API cost, which is a form of monitoring so your agent isn’t blowing through a context window or budget.
LangChain: LangSmith and Native Tracing
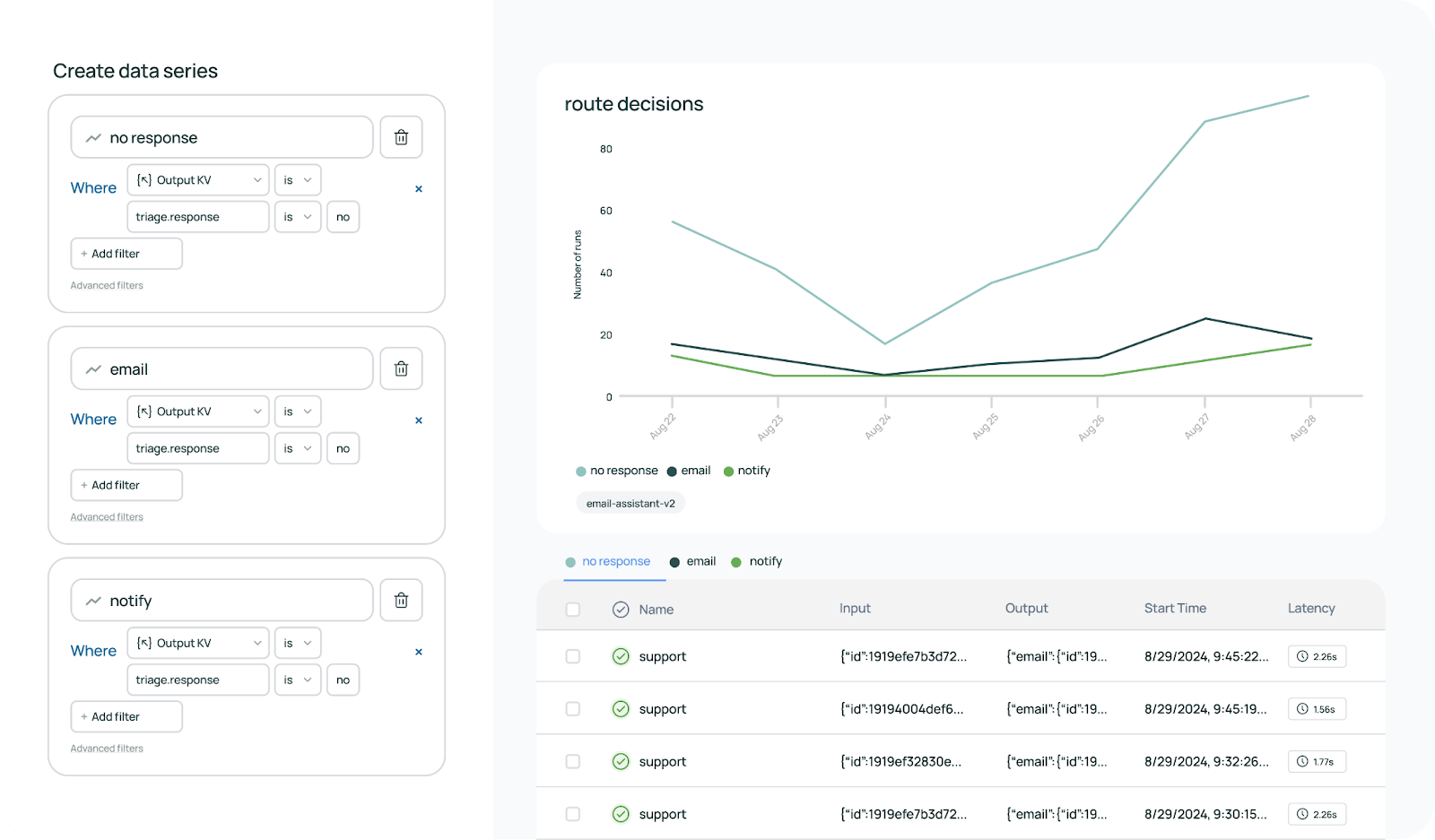
LangChain has significantly invested in first-party monitoring and evaluation via LangSmith.
LangSmith is essentially a cloud service where all your LangChain agent runs can be recorded and analyzed.
With a couple of lines of setup, you can instruct your LangChain agent to send traces to LangSmith. Each trace will capture the sequence of actions: prompts sent to the LLM, LLM responses, tool inputs and outputs, errors, and timings.
The LangSmith UI then lets you replay those traces or drill down into each step. This will give you crucial insights when your agent fails. You can see exactly which step went wrong and adjust accordingly.
LangSmith also integrates evaluation features. You can define evaluation criteria or metrics and run batches of test prompts through your agent, then view summary statistics.
For example, you might have a reference answer for each test query, and LangSmith can auto-compare the agent’s answer to it using an LLM-based grader or string match.
This turns evaluation into a systematic process rather than ad hoc.
Another aspect of observability is real-time monitoring.
LangChain provides callbacks and logging that can be integrated with standard logging tools like LangSmith, Langfuse, Weights & Biases, as well. You can attach a StdOutCallback to print decisions as they happen, or a TracerCallback that streams to LangSmith asynchronously.
Features 4. Structured Output (Pydantic, JSON)
Many agent applications require the AI to return information in a structured format rather than free-form text.
Both LangChain and LlamaIndex recognize this need and provide ways to enforce structured outputs using Pydantic models or JSON schemas.
LlamaIndex: Pydantic Models and Output Classes
LlamaIndex allows you to specify a Pydantic model that the output should conform to. One convenient mechanism is using its LLM Pydantic Program interface.
You give it an output_cls argument (which is a BaseModel subclass you define), and under the hood, it will either use the OpenAI function calling API - if using OpenAI models that support it - or instruct the LLM to output a JSON that fits the schema, then parse it.
Let’s suppose you want an agent to extract a person’s name and age from text. You can define a Pydantic class Person(name: str, age: int), and then run a LlamaIndex query or agent with output_cls=Person.
The LLM’s answer will be intercepted and parsed into a Person object. If the LLM returns something that doesn’t validate (say it outputs age as ‘twenty’), LlamaIndex can detect the mismatch and even retry or throw an error.
There are two ways agents can return JSON: either directly via output_cls or by providing a custom structured_output_fn for more advanced control.
# LlamaIndex: enforce structured output with Pydantic
from pydantic import BaseModel
from llama_index import LLMPredictor, ServiceContext
from llama_index.program import LLMPydanticProgram
class UserInfo(BaseModel):
name: str
age: int
program = LLMPydanticProgram.from_defaults(output_cls=UserInfo)
response = program.query("Alice is 30 years old.")
print(response) # returns a UserInfo object with name and ageLangChain: Output Parsers and Function Calling
LangChain approaches structured output by integrating with prompt formatting.
It provides an OutputParser abstraction; basically, a class that knows how to parse an LLM’s raw string into a Python object.
The PydanticOutputParser is a concrete implementation that takes a Pydantic model and automatically generates an expected JSON format in the prompt and a parser for the result.
When you use it with a PromptTemplate, it will append something like: “Your response should be a JSON with the following schema: { … }” to the prompt, ensuring the LLM knows to output JSON. After the LLM responds, the parser will parse the JSON back into the Pydantic object.
LangChain can also leverage the native function-calling feature of models like GPT-4. In LangChain, if you specify a Pydantic model for output, the OpenAI LLM wrappers directly pass the function schema so that GPT-4 returns a JSON complying with it.
Here’s a quick illustration of structured output usage:
# LangChain: enforce structured output with Pydantic
from pydantic import BaseModel
from langchain.prompts import PromptTemplate
from langchain.output_parsers import PydanticOutputParser
from langchain.llms import OpenAI
class UserInfo(BaseModel):
name: str
age: int
parser = PydanticOutputParser(pydantic_object=UserInfo)
prompt = PromptTemplate(
input_variables=["text"],
template="Extract the user's name and age from the text.\n{text}\n{format_instructions}",
partial_variables={"format_instructions": parser.get_format_instructions()}
)
llm = OpenAI(model="gpt-3.5-turbo")
result = llm(prompt.format(text="Alice is 30 years old."))
data = parser.parse(result) # data is an instance of UserInfo
print(data.name, data.age)LlamaIndex vs LangChain: Integration Capabilities
Modern LLM applications rarely live in isolation; they need to connect with various models, data sources, vector databases, and external tools/APIs.
Both LlamaIndex and LangChain are highly extensible and offer a wide array of integrations. However, they focus on slightly different integration strengths.
LlamaIndex
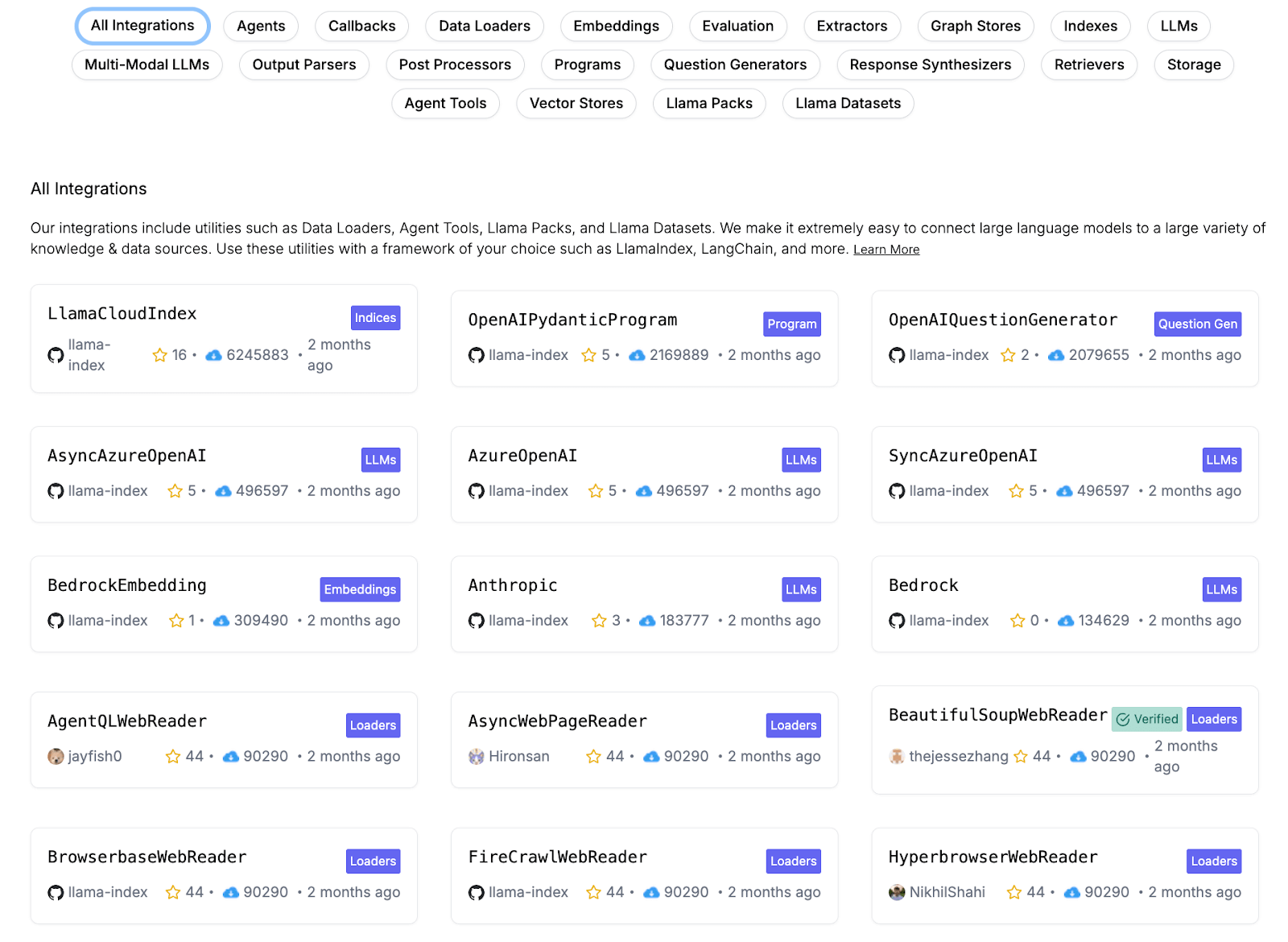
One of LlamaIndex’s biggest selling points is its rich set of integrations for data sources, vector databases, and LLM providers.
LlamaIndex supports integrations with OpenAI, Anthropic, Hugging Face, PaLM, and more LLMs. This means you can plug in your choice of language model easily – whether it’s GPT-4 via OpenAI’s API, Claude via Anthropic, or a local model on Hugging Face.
On the data side, LlamaIndex’s LlamaHub (community-driven) provides over 300 integration packages (often called plugins). These cover everything from specific data connectors like Slack, Notion, Google Drive, databases, to vector store backends like Pinecone, Weaviate, FAISS, Milvus, etc., to even tools and APIs you can call.
👀 Note: LlamaIndex can also integrate with LangChain itself if needed (they aren’t mutually exclusive).
LangChain
LangChain’s integrations are extensive across the board. Since LangChain is more general-purpose, it boasts support for a long list of model APIs - OpenAI, Anthropic, AI21, Cohere, HuggingFace Hub models, Azure, etc., and even has experimental support for model deployment frameworks.
If a new LLM API comes out tomorrow, chances are someone will add it to LangChain quickly.
For data stores: LangChain supports almost every vector database out there:
- Pinecone
- Weaviate
- FAISS
- Chroma
- ElasticSearch
The list goes on…
Where LangChain kicks things up a notch is tool integrations for agents. The platform has tools for things like:
- Web search: SerpAPI, Bing
- Calculations: Wolfram Alpha or a built-in Python eval
- Code execution: Python REPL
- Translation: Google Translate API
And even more creative ones, like playing games or controlling a browser. Moreover, the community has contributed numerous tools.
LlamaIndex vs LangChain: Pricing
Both LlamaIndex and LangChain are open-source projects that you can use for free. However, each also offers managed services or commercial offerings on top of the open-source core, with different pricing models.
LlamaIndex
The open-source LlamaIndex library is MIT-licensed and free to use. You can pip install llama-index and build with it locally or on your own servers without paying anything (aside from costs of the underlying LLM API calls and infrastructure).
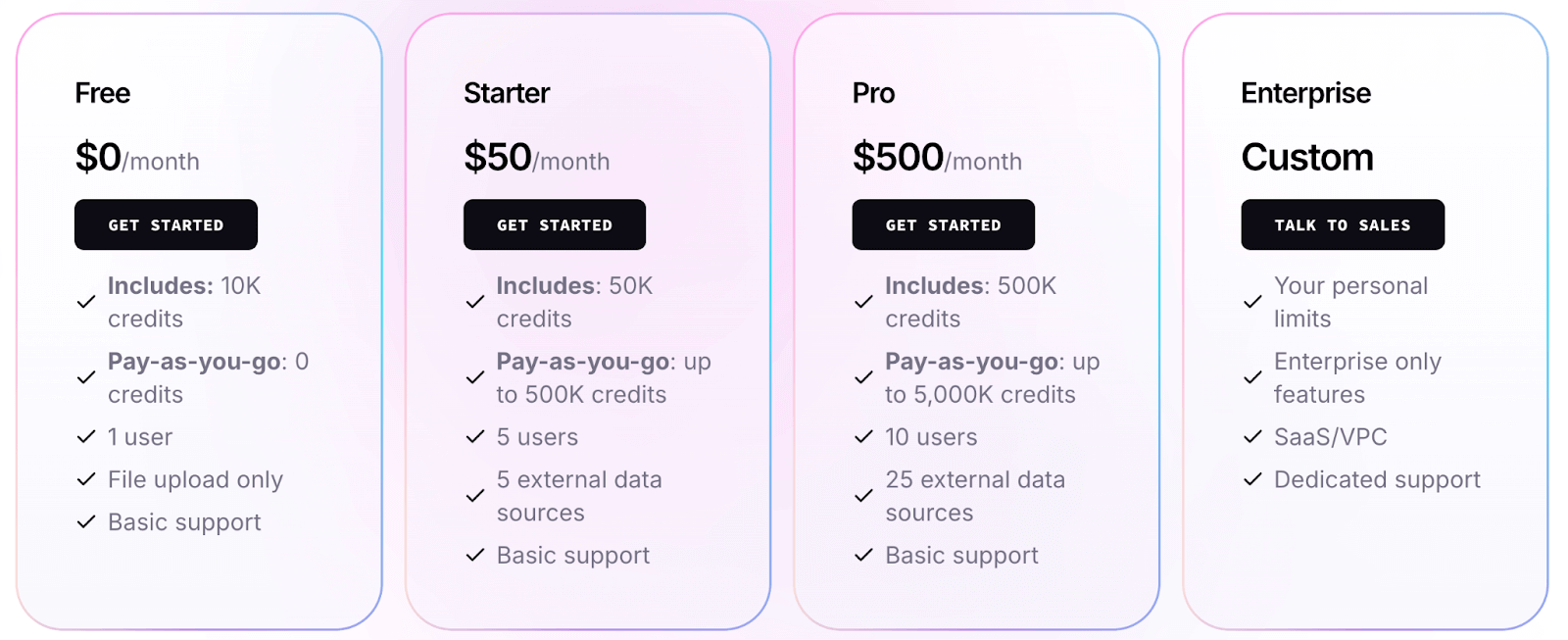
LlamaIndex also provides a hosted platform, which offers more and better features. Their pricing (as of 2025) is credit-based:
- Free tier: $0, includes 10k credits (sufficient to try out with smaller workloads).
- Starter plan: $50 per month, includes 50k credits.
- Pro plan: $500 per month, includes 500k credits.
- Enterprise plan: Custom pricing
LangChain
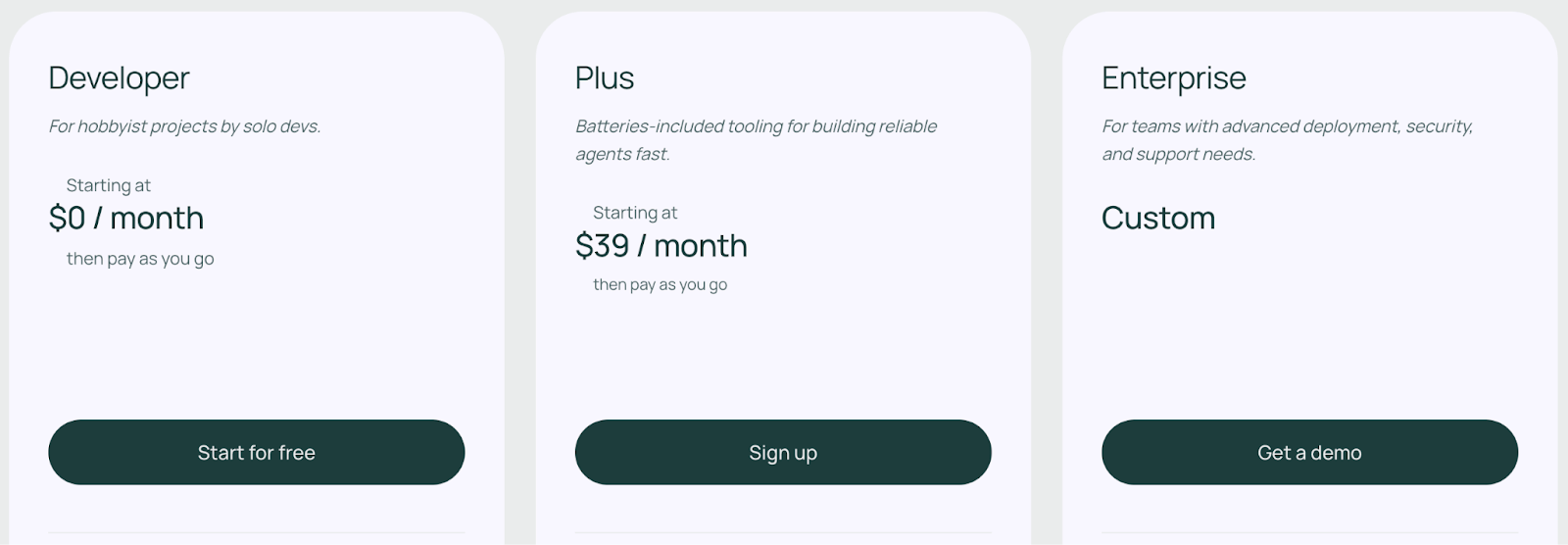
LangChain comes with an open-source plan that’s free to use. If you install the LangChain Python or JS package, you get the MIT-licensed code to design agents with no licensing cost or usage fees. This open-source plan has a limit of executing 10,000 nodes per month.
Apart from the free plan, LangGraph offers three paid plans to choose from:
- Developer: Includes up to 100K nodes executed per month
- Plus: $0.001 per node executed + standby charges
- Enterprise: Custom-built plan tailored to your business needs
How ZenML Manages the Outer Loop for Production Agents
After comparing LlamaIndex and LangChain, you might be thinking: why not use both? In fact, many advanced AI systems do combine them – for example, using LlamaIndex for data retrieval and LangChain for tool orchestration.
However, managing both workflows in production can be challenging. This is where ZenML, an open-source MLOps + LLMOps framework, comes into play.
ZenML acts as the glue and ‘outer loop’ around LlamaIndex and LangChain, allowing you to integrate and deploy workflows that use one or both.
Here’s how ZenML helps streamline the development and deployment of agentic AI systems using LlamaIndex and LangChain:
Feature 1. Pipeline Orchestration
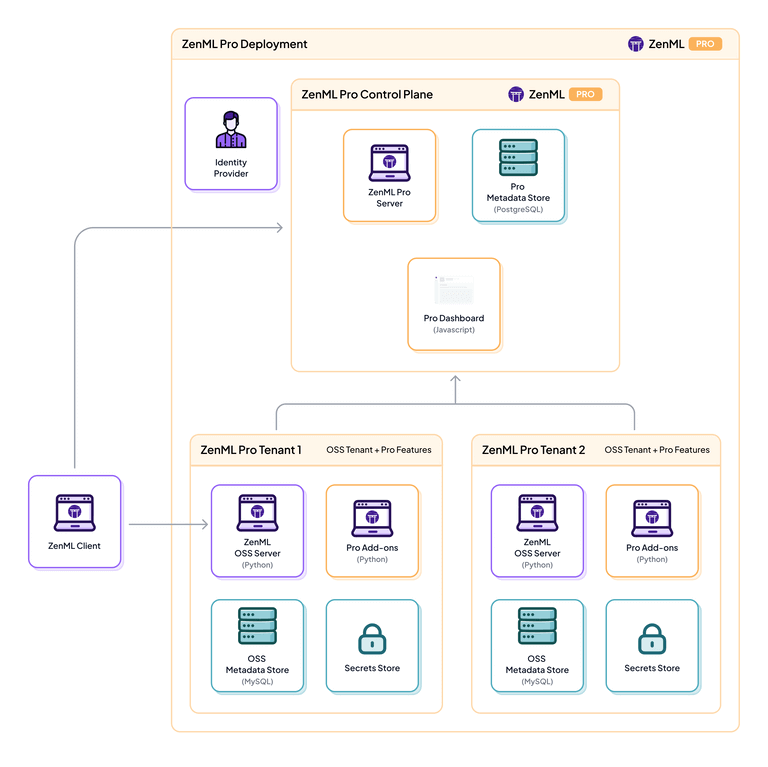
ZenML lets you define end-to-end pipelines that include data prep, model calls, and agent invocations.
You can embed LlamaIndex or LangChain agents as steps in a ZenML pipeline, right alongside other steps like data ingestion or model fine-tuning.
For instance, you could have a pipeline where Step 1 uses LlamaIndex to index documents, Step 2 uses a LangChain agent to answer queries using that index, and Step 3 evaluates the answers.
ZenML ensures these multi-step workflows run reliably and reproducibly, whether on your local machine or in a production environment.
Feature 2. Experiment Tracking
ZenML provides experiment tracking and lineage for all pipeline runs. This means every time your agent runs, our platform automatically logs metadata, tells you which version of LlamaIndex and LangChain was used, what parameters, which data, and of course, the outcomes.
You get a single dashboard to monitor all your agents and how they connect to upstream data and downstream results.
This unified visibility is incredibly useful when you have many moving parts. Instead of juggling separate logs from LlamaIndex and LangChain, ZenML centralizes it.
Feature 3. Continuous Evaluation and Feedback
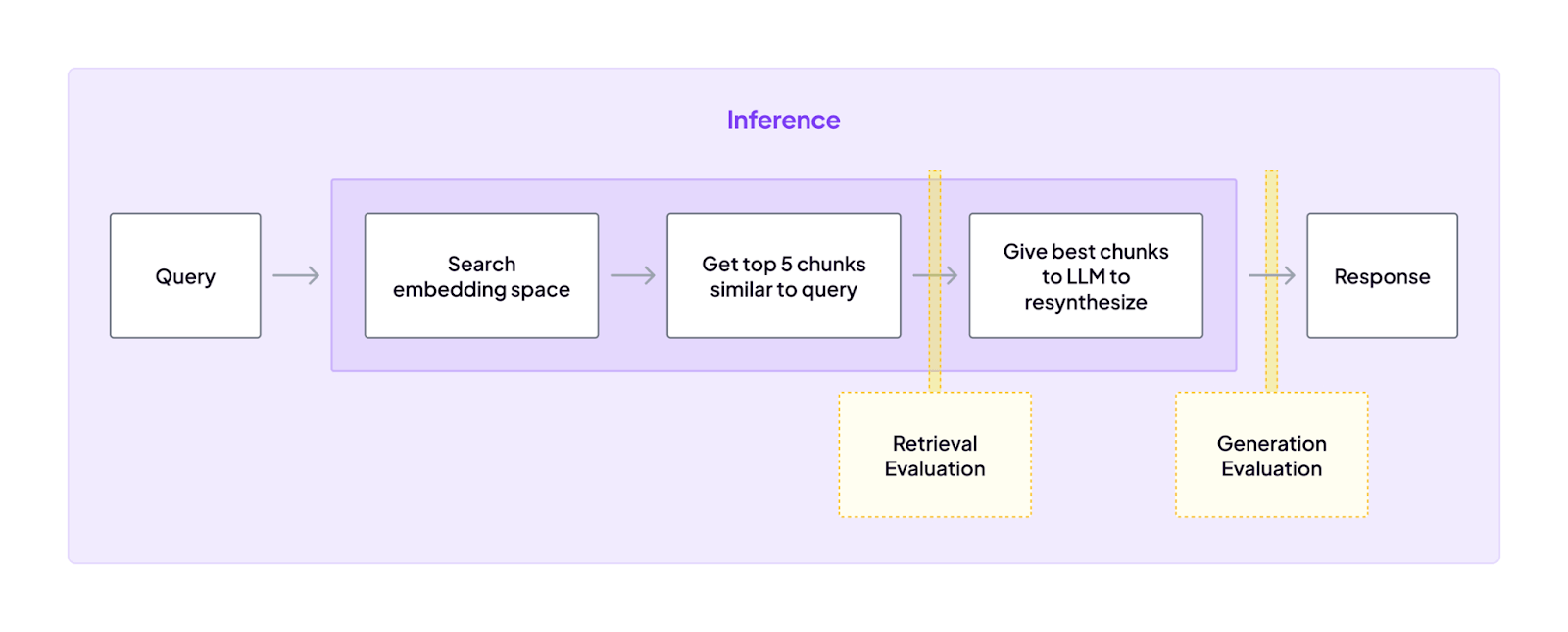
ZenML inserts evaluation steps into the pipeline and triggers actions based on results.
After each agent execution, ZenML can automatically run an evaluator. If a run is flagged as ‘bad,’ ZenML can trigger a feedback loop that reloads data, alerts a human, or retrains a component.
Essentially, ZenML helps implement the outer feedback loop that sits on top of the agent’s inner reasoning loop, enabling continuous improvement and reliability.
In short, LlamaIndex and LangChain excel at the ‘inner loop’ of agent development – indexing data, composing prompts, chaining model calls. ZenML provides the ‘outer loop’ – the infrastructure to deploy, monitor, and govern these agents in a robust way.
👀 Note: At ZenML, we have built several such integrations with tools like LangChain, LlamaIndex, CrewAI, and more. We are actively shipping new integrations that you can find on this GitHub page: ZenML Agent Workflow Integrations.
📚 Other comparison articles to read:
Which Framework of the Two Is Best for Agentic AI Workflows?
Choosing between LlamaIndex and LangChain ultimately depends on your project’s priorities and context. Both are powerful, and as we’ve seen, can even complement each other. Here are some guidelines to help you decide:
✅ Choose LlamaIndex if your primary goal is to build a data-aware LLM application quickly. It’s fantastic for scenarios like enterprise chatbots, document Q&A systems, or assistants that need to pull information from proprietary text sources.
✅ Choose LangChain if you need fine-grained control over multi-step reasoning or a wide variety of integrations. For building complex agent workflows like an AI that plans tasks, calls various external tools in parallel or sequence, iterates on results, etc., LangChain provides the structure and components to do it safely.
Many teams might start with one and incorporate elements of the other as needed. And as mentioned, ZenML can help unify these tools under one roof. With ZenML, you could use LlamaIndex and LangChain together in a single pipeline, and not worry about operational headaches, and focus on building the best agent, rather than wiring the plumbing.
If you’re interested in taking your AI agent projects to the next level, consider joining the ZenML waitlist. We’re building out first-class support for agentic frameworks (like LangChain, LlamaIndex, and more) inside ZenML, and we’d love early feedback from users pushing the boundaries of what AI agents can do. With ZenML, you can seamlessly integrate whichever agent framework you choose into robust, production-grade workflows. Join our waitlist to get started.👇


