

On this page
ML teams have a wealth of MLOps tools to choose from when it comes to experiment tracking and lifecycle management. Neptune AI, MLflow, and ZenML are three popular options.
With Neptune AI being acquired by OpenAI and shutting down its SaaS platform in March 2026, you should consider a Neptune alternative like the two we will talk about in this comparison.
This Neptune AI vs MLflow vs ZenML comparison will help you understand these frameworks’ key dimensions: maturity and lineage, core features, integrations, and pricing. By the end, you will understand the strengths of each platform and which ML experiment tracking stack is best suited for your needs.
Neptune AI vs MLflow vs ZenML
🧑💻 Neptune AI: Neptune AI was a hosted experiment tracking tool focused on structured metadata logging, model comparison, and collaboration. It offered a strong UI and scalable storage for large experiments. After its acquisition by OpenAI, Neptune announced the shutdown of its public platform, so teams must migrate to alternatives.
🧑💻 MLflow: MLflow is an open-source framework for experiment tracking, model registry, and reproducible ML execution. It logs parameters, metrics, and artifacts through a simple API and can run fully self-hosted. It is widely adopted but limited to basic tracking, with no built-in pipeline orchestration or advanced collaboration features.
🧑💻 ZenML: ZenML is an open-source MLOps framework that treats experiment tracking as part of reproducible ML pipelines. It versions data, artifacts, and models automatically and integrates with orchestrators like Airflow, Kubernetes, and cloud tools. ZenML offers a unified workflow for training, evaluation, and deployment, making it ideal for engineering-heavy teams.
Neptune AI vs MLflow vs ZenML: Maturity and Lineage
When selecting a core component of the ML infrastructure stack, an assessment of the tool’s lineage, stewardship, and development velocity is as critical as feature comparison. The risk profile of a tool is determined not just by what it does today, but by who maintains it and where it is going.
The following table synthesizes the maturity metrics for each platform, providing a snapshot of their market footprint as of late 2025.
| Metric | Neptune AI | MLflow | ZenML |
|---|---|---|---|
| First Public Release | 2016/2017 (Founded 2016) | June 2018 (Alpha Release) | Dec 2020 / Early 2021 |
| Stewardship Model | Proprietary (Neptune Labs → OpenAI) | Open Core (Databricks / Linux Foundation) | Commercial Open Source (ZenML GmbH) |
| Primary License | Proprietary SaaS / Apache 2.0 Client | Apache 2.0 | Apache 2.0 |
| GitHub Stars | 620+ (Client Repo) | 23,200+ | 5,100+ |
| Forks | ~66 | 5,000+ | ~559 |
| Commit Activity | 2,100+ (Client) | 9,600+ | 8,300+ |
Neptune AI and MLflow both emerged around 2018 and have had several years to mature. Neptune was originally prototyped in 2016 and spun off from Polish AI firm deepsense.ai in 2018.
MLflow has been open-source from day one and continues to thrive under community and commercial stewardship. It was introduced by Databricks in June 2018 as a framework to ‘simplify the machine learning lifecycle,’ and was quickly embraced by the industry.
ZenML is the youngest of the three, but its lineage is notable for rapid growth and a modern approach. Founded in 2021 by a Germany-based team, ZenML set out to bridge the gap between experimentation and production ML from the start.
Neptune AI vs MLflow vs ZenML: Feature Comparison
Let’s compare how Neptune, MLflow, and ZenML stack up on core features for the MLOps lifecycle. The table below shows a quick overview of the sections that follow.
| Feature | Neptune AI | MLflow | ZenML |
|---|---|---|---|
| Experiment tracking and run metadata | Dedicated tracking SaaS with rich UI. Logs metrics, parameters, hyperparameters, images, etc., with a flexible metadata structure. | Comes with open-source Tracking API and server. Logs parameters, metrics, tags, and artifacts via Python/R/Java APIs. | Tracking is integrated into pipelines. Automatically logs each pipeline step’s inputs/outputs and metrics to its metadata store. |
| Artifact, Dataset, and Model Versioning | Logs artifacts (files, models) as Artifacts with MD5 hashes and metadata. Supports dataset versioning by tracking data file hashes instead of full uploads. | Artifact store built into MLflow. Artifacts are saved to a configured storage. Has a Model Registry for versioning models: register models from any run, track versions, and mark stages. | Artifacts are automatically versioned in ZenML’s artifact store (local or cloud) on each pipeline execution. Every dataset, model, or output gets a version number, and ZenML can retrieve specific versions by name. |
| Pipeline/Workflow Orchestration | Not an orchestrator. | Provides a “Projects” format to package code and run it on different platforms, and a CLI to execute projects with reproducibility. More of a basic orchestrator. | ZenML is fundamentally a pipeline orchestrator that can run on any backend (local, Kubernetes, Airflow, etc.). You declare a pipeline of steps with ZenML’s API, and ZenML handles execution order, caching, scheduling (via integrated orchestrators), and parallelism. |
Feature 1. Experiment Tracking and Run Metadata
At its core, experiment tracking is the digitalization of the scientist’s lab notebook. It captures the inputs (hyperparameters, code, data config) and outputs (metrics, images, models) of every training run.
Neptune AI
Neptune AI is a metadata-first experiment tracker built for large research workflows.
You create a run, log metrics, parameters, artifacts, system metadata, and visual assets, and explore everything in a structured namespace inside Neptune’s UI.
The platform handles thousands of experiments, offers strong comparisons, tagging, filtering, and provides auto-logging hooks for popular ML frameworks.
Teams use it mainly because of its reliability, clean run organization, and flexible metadata structure. But one thing to note is that Neptune never handled orchestration. Instead, it fits inside existing pipelines like Airflow, Kubeflow, or custom training scripts.“
from neptune_scale import Run
if __name__ == "__main__":
run = Run(experiment_name=...)
run.log_configs(
{
"parameters/use_preprocessing": True,
"parameters/learning_rate": 0.001,
"parameters/batch_size": 64,
"parameters/optimizer": "Adam",
}
)
for step in epoch:
# your training loop
run.log_metrics(
data={
"train/accuracy": 0.87,
"train/loss": 0.14,
}
step=step,
)Since the OpenAI acquisition and platform shutdown announcement, teams relying on Neptune must migrate to an alternative.
MLflow
MLflow offers lightweight experiment tracking with parameters, metrics, tags, artifacts, and source versioning. You start a run, call the logging API, and MLflow stores everything locally or on a remote tracking server.
The UI is basic but practical: tables for runs, side-by-side comparisons, simple line plots, and artifact browsing.
MLflow auto-logs several frameworks, making it quick to integrate into training scripts. The platform has added basic system metrics logging in recent versions, though it often requires additional configuration and lacks the deep, out-of-the-box hardware profiling visualization that Neptune provided.
MLflow Projects improves reproducibility through environment capture, but orchestration is outside its scope. Its simplicity and ecosystem support make it a common baseline for experiment tracking.
ZenML
ZenML takes a pipeline-first approach to experiment tracking. Instead of logging individual scripts, you define pipelines and steps, and ZenML automatically versions all inputs, outputs, and intermediate artifacts.
Every dataset, model, and metric becomes a versioned artifact tied to a single pipeline execution. This creates reproducible lineage across the full ML workflow: data, code, configuration, and model states.
ZenML stores metadata in a central metadata store, provides a dashboard, and a CLI for exploring runs. It also supports custom metadata logging inside any step.
ZenML’s built-in tracking is sufficient for many cases. It logs metadata for artifacts (for example, for a DataFrame artifact, ZenML will auto-log its shape and size. You can also attach custom metadata to any artifact or pipeline run using ZenML’s log_metadata() API within a step.
Unlike Neptune and MLflow, ZenML treats experiment tracking and orchestration as a unified layer, with integrations for Airflow, Kubernetes, cloud orchestrators, and even experiment tracking like Neptune and MLflow.
This means you keep familiar UIs while gaining structured pipeline execution.
Bottom line: ZenML wins here because tracking is built directly into pipelines, giving you automatic lineage and structured metadata without extra logging work. This makes experiments reproducible by default and scales better than standalone trackers.
Feature 2. Artifact, Dataset, and Model Versioning
In production AI, the code is often the least important part of the reproducibility equation. The data and the artifacts (model binaries, preprocessors) are the sources of entropy. How each tool manages these assets is a decisive differentiator.
Neptune AI
Neptune AI uses a metadata-only artifact tracking approach. When you call run["artifacts/dataset"].upload("data/train.csv"), Neptune computes a hash, stores metadata, and only uploads the file if small or explicitly requested.
This lets you version large datasets and model files without duplicating storage. Each run shows an Artifacts section with previews, hashes, and references, and you can compare artifacts across runs to see whether data or model files change.
Neptune 2.x includes a model registry, but 3.x shifted to run-central model metadata, where you tag specific runs as model candidates instead of using stages.
Neptune’s structure makes it easy to track models, datasets, and checkpoints as versioned metadata and retrieve any artifact via API.
MLflow
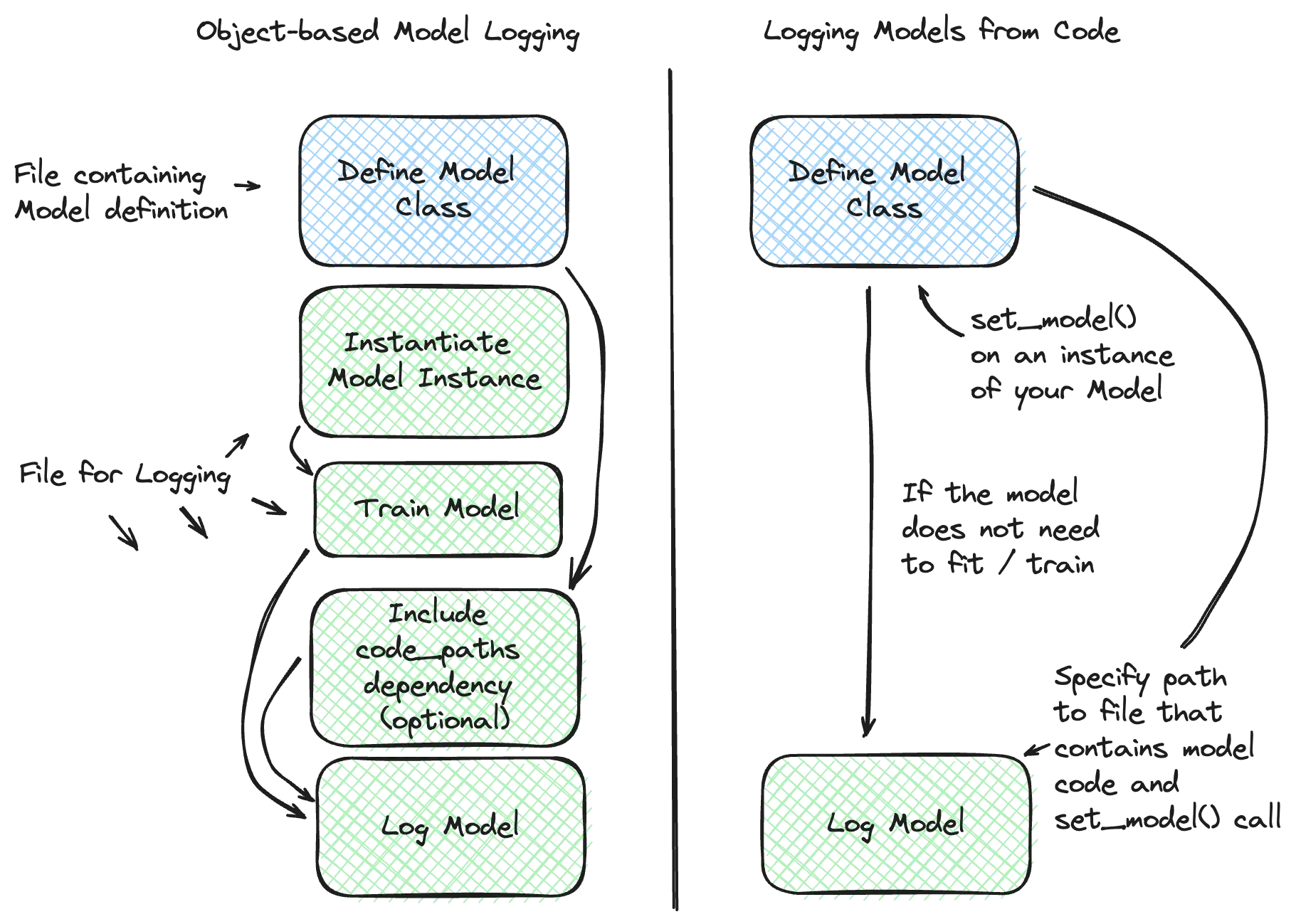
MLflow’s strength is its structured Model Registry. When you log a model, using mlflow.log_artifact() for generic files or a flavor call like mlflow.sklearn.log_model(); MLflow stores it as a run artifact.
Registering it creates a Registered Model, and each logged model becomes a new version with stages such as Staging or Production. This gives you a clear promotion workflow.
Artifacts live in an Artifact Store (S3, GCS, Azure, local), and MLflow retrieves them with mlflow.artifacts.download_artifacts() or model URIs.
What’s more, MLflow adds Datasets, capturing hashes or paths for dataset lineage, though dataset versioning remains tag-based. It doesn’t deduplicate artifacts across runs, so storage grows unless managed externally.
ZenML
ZenML treats artifacts as first-class objects. Every step input or output becomes an artifact stored in your configured artifact store (local, S3, GCS). Creating artifacts in ZenML is pretty easy:“
from zenml import pipeline, step
import pandas as pd
@step
def create_data() -> pd.DataFrame:
"""Creates a dataframe that becomes an artifact."""
return pd.DataFrame({
"feature_1": [1, 2, 3],
"feature_2": [4, 5, 6],
"target": [10, 20, 30]
})
@step
def create_prompt_template() -> str:
"""Creates a prompt template that becomes an artifact."""
return """
You are a helpful customer service agent.
Customer Query: {query}
Previous Context: {context}
Please provide a helpful response following our company guidelines.
"""The framework records the artifact itself plus its metadata in the metadata store. Artifacts auto-version by name, so if a step outputs "iris_dataset", each pipeline run creates a new version unless ZenML’s caching reuses an existing one.
You can fetch any version with load_artifact(name="my_model", version="3"), and ZenML deserializes it automatically.
ZenML also supports manual artifact registration outside pipelines. This makes it behave like a combined model and dataset registry, letting you evolve artifacts across runs; for example, saving an untrained model as version 1 and producing a trained version 2 in a pipeline.
ZenML’s dashboard offers comparison views to inspect differences in artifact metadata or dataset shapes across runs. Because you can load older versions in new pipelines, ZenML enables reproducible “time-travel” workflows for debugging and evaluation.
Model versioning relies on artifact conventions but integrates cleanly with deployers like Seldon or SageMaker.
Bottom line: ZenML provides the strongest versioning model since every artifact versions automatically with each pipeline run. This creates reliable ‘time-travel’ debugging and cleaner lineage than manual logging approaches.
Feature 3. Pipeline and Workflow Orchestration Fit
As AI systems evolve from ‘notebook experiments’ to ‘production agents,’ the ability to orchestrate complex, multi-step workflows becomes the primary engineering constraint.
Neptune AI
Neptune AI is not an orchestrator. It fits inside whatever system runs your training jobs, whether that is a simple Python script, a notebook, or a multi-step pipeline in Airflow, Kubeflow, or SageMaker.
You insert logging calls such as run["metrics/acc"] = 0.92, and Neptune records metadata while the orchestrator handles scheduling, retries, and dependencies.
The platform offers integration guides for Airflow, SageMaker, Azure ML, and custom Kubernetes workloads. Many teams use Neptune with cloud training jobs or with external orchestrators like Prefect or Dagster.
It also supports offline logging for restricted environments. The flow is simple: your pipeline executes elsewhere, Neptune captures the metadata. With the platform shutting down post-acquisition, teams relying on this lightweight, orchestrator-agnostic setup must migrate.
MLflow
name: My ML Project
# Environment specification (choose one)
python_env: python_env.yaml
# conda_env: conda.yaml
# docker_env:
# image: python:3.9
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
max_epochs: {type: int, default: 100}
command: "python train.py --reg {regularization} --epochs {max_epochs} {data_file}"
validate:
parameters:
model_path: path
test_data: path
command: "python validate.py {model_path} {test_data}"
hyperparameter_search:
parameters:
search_space: uri
n_trials: {type: int, default: 50}
command: "python hyperparam_search.py --trials {n_trials} --config {search_space}"MLflow provides basic execution packaging through MLflow Projects, where you define an MLproject file and run it using mlflow run. to ensure reproducibility.
MLflow Projects is not a general orchestrator: it executes a single entry point rather than managing DAGs, retries, or dependencies.
Most users pair MLflow with Airflow, Kubeflow, Jenkins, or Kedro (which has an MLflow plugin). MLflow Model Pipelines add templates for model development, but remain limited compared to full orchestrators.
Databricks users get seamless MLflow integration because jobs and notebooks automatically log to MLflow. Outside that ecosystem, the framework acts as a tracking layer embedded inside external orchestration.
ZenML
ZenML is built for orchestration. You define steps using @step and connect them inside a @pipeline, and ZenML handles execution order, caching, artifact passing, and metadata tracking automatically.
Pipelines run locally for development, but you can switch to powerful backends like Kubeflow, Airflow, Ray, or cloud orchestrators, simply by changing the ZenML stack. If you choose to do so, ZenML containerizes steps, launches them on the orchestrator, and ensures each step receives the correct inputs and outputs through artifact URIs instead of manual file passing.
This creates reproducible multi-step workflows without forcing you to manage DAGs or infrastructure details.
Because ZenML understands the full graph, it can compare runs, detect changes, and enable time-travel debugging.
Teams also use ZenML for LLMOps and agentic workflows, orchestrating fine-tuning, evaluation, and multi-step chains. Unlike Neptune or MLflow, ZenML provides native pipeline orchestration and experiment tracking in one unified layer.
Bottom line: ZenML is the only true orchestrator in this comparison, giving teams reproducible multi-step pipelines, caching, and backend flexibility without managing DAG logic manually. It’s the best choice if you care about production-grade workflow automation.
Neptune AI vs MLflow vs ZenML: Integrations
Neptune AI
Neptune AI focuses on framework-level and experiment-level integrations. You could plug Neptune into almost any Python training loop and log with a few lines of code using callbacks or hooks.
Key integrations:
- PyTorch Lightning, TensorFlow/Keras, scikit-learn, XGBoost, LightGBM
- Optuna, Ray Tune, Hyperopt for HPO
- Airflow, Kubeflow Pipelines, Prefect for orchestration
- Jupyter notebook extension
- REST API for custom tooling
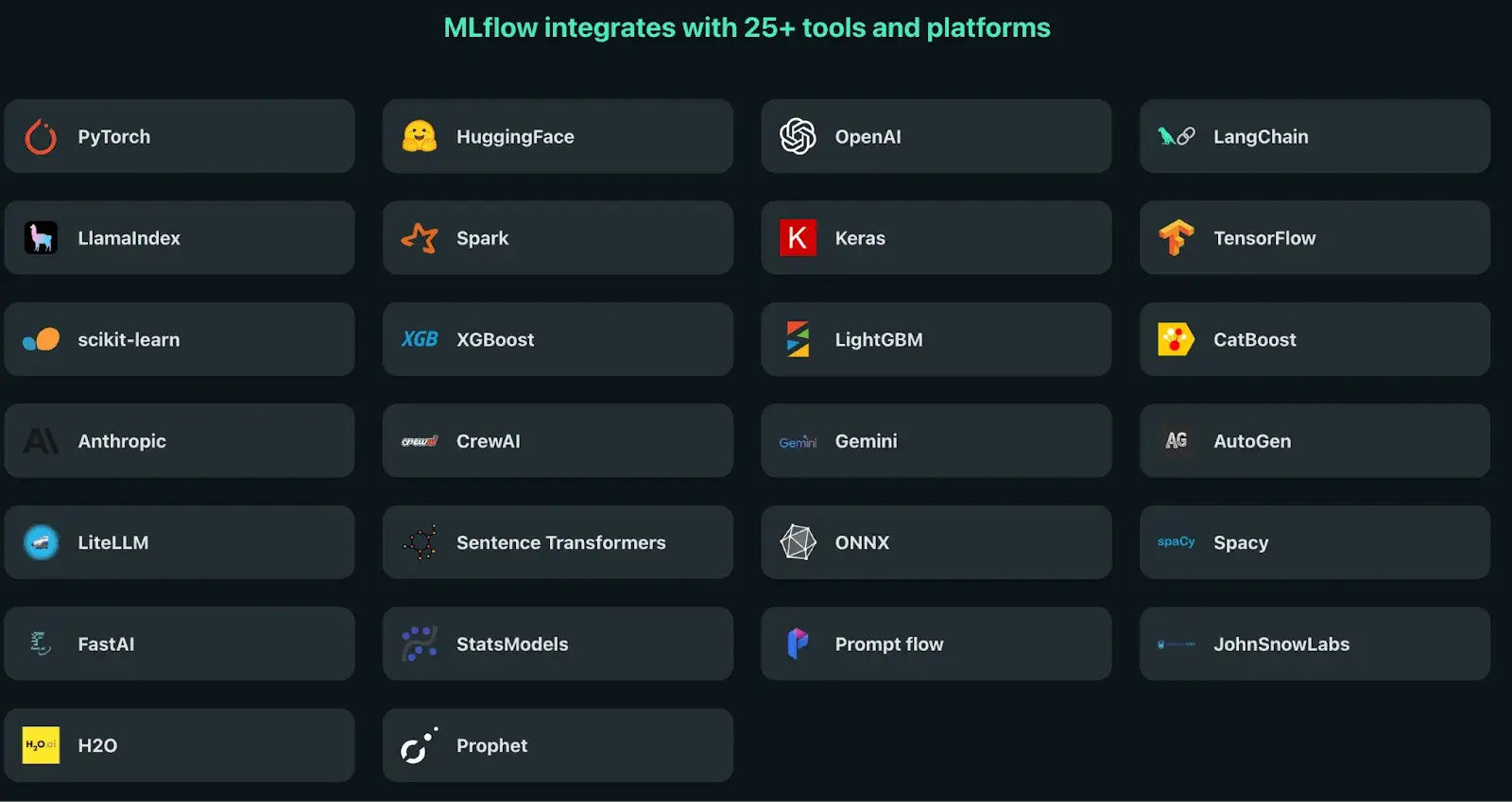
MLflow
MLflow integrates broadly because it is open-source and ecosystem-native. Autologging covers the most popular frameworks:
- TensorFlow, Keras, PyTorch, XGBoost, LightGBM
- Hugging Face, Spark MLlib, Scikit-learn
- Jenkins, GitHub Actions, GitLab CI
- Databricks (native), Airflow, Kubeflow via operators
- Plugins for custom storage, authentication, and model flavors
- Deployment targets: MLflow Serve, SageMaker, Azure ML, Docker
MLflow fits cleanly into almost any existing ML workflow due to its API+plugin architecture.
ZenML
ZenML is integration-heavy by design through its Stack abstraction. You mix-and-match tools, and ZenML coordinates them automatically.
- Orchestrators: Airflow, Kubeflow, Argo, Ray, local
- Experiment trackers: MLflow, W&B, ClearML, Comet
- Artifact stores: S3, GCS, Azure Blob, local FS
- Model deployers: Seldon, BentoML, SageMaker, Ray Serve
- Data validation: Great Expectations, whylogs, Evidently
- Feature store: Feast
- Container registries: Docker Hub, ECR, GCR
- Alerters: Slack, email

ZenML is the most flexible of the three. It acts as the central hub that binds all MLOps tools into one pipeline workflow, without forcing a specific cloud or framework.
Neptune AI vs MLflow vs ZenML: Pricing
Let’s see how much using each platform will potentially cost you:
Neptune AI
Neptune AI previously offered a free plan for individuals and academics. It also had three paid plans to choose from.
However, as of the acquisition announcement, new sign-ups (including free trials) have been permanently disabled.
MLflow
MLflow (open-source) is free to use. You can install the tracking server on your own servers at no licensing cost. The main costs associated with MLflow are infrastructure and maintenance. If you run an MLflow server on an EC2 instance and store artifacts in S3, you’ll pay AWS for those resources.
Many companies use MLflow for free internally. Some choose to pay for Databricks to get a managed MLflow experience. Databricks’ Managed MLflow is part of their platform offering (they don’t sell MLflow standalone; it’s bundled with their Lakehouse platform usage).
ZenML
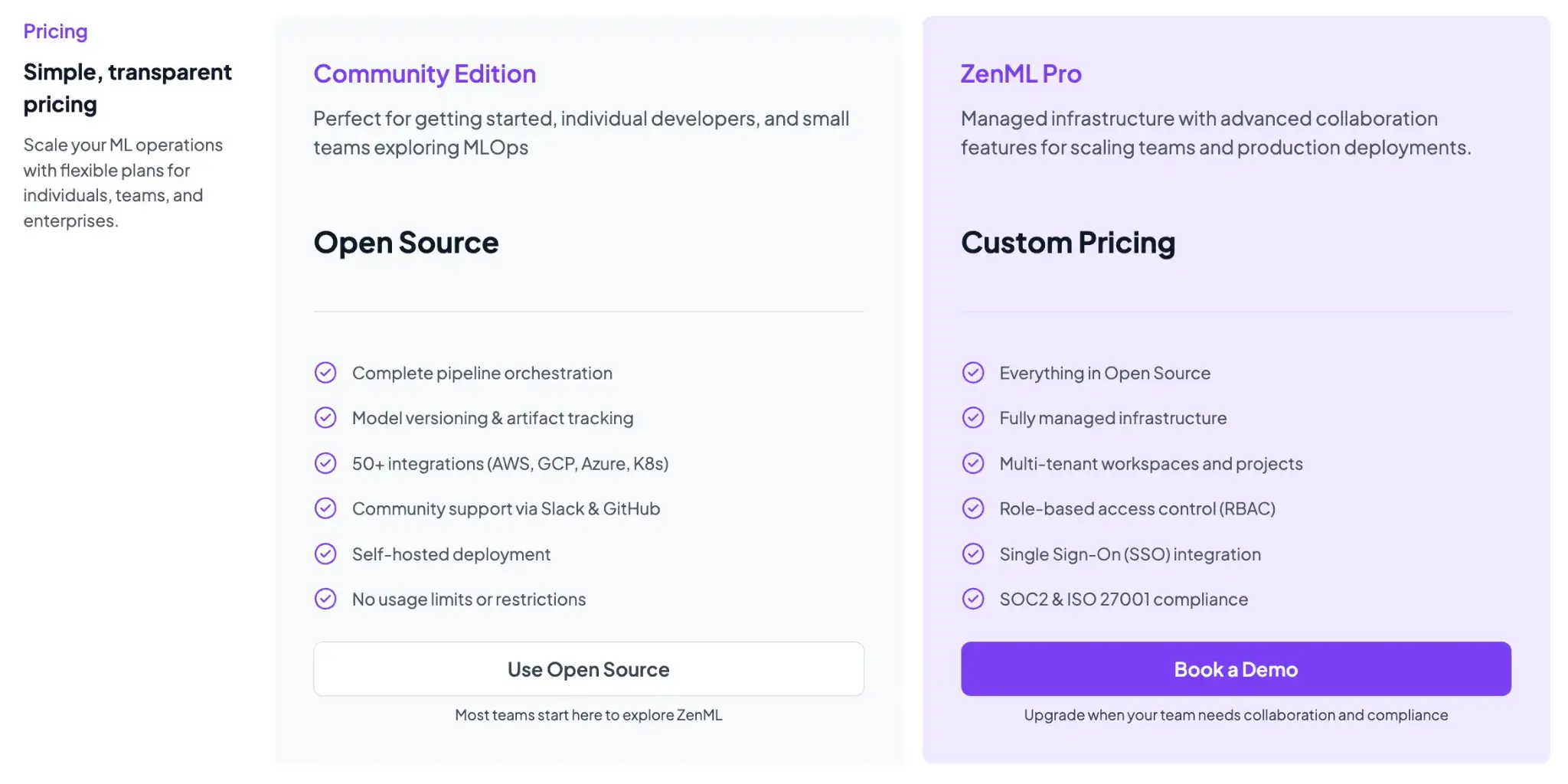
ZenML is free and open-source (Apache 2.0 License). The core framework, including the tracking, orchestration, and upcoming dashboard, can all be self-hosted at no cost. For teams that want a managed solution or enterprise features, ZenML offers business plans (ZenML Cloud and ZenML Enterprise) with custom pricing based on deployment and scale.
These paid plans include features like SSO, role-based access control, premium support, and hosting, but all the core functionality remains free in the open-source version. Essentially, you can start with ZenML’s free tier and only consider paid options if you need advanced collaboration or want ZenML to manage the infrastructure for you.
Which MLOps Platform Is Best For You?
Neptune AI served teams well, but with its shutdown underway, it is no longer a viable choice for 2026 and beyond.
MLflow remains a dependable open-source option if you need lightweight experiment tracking and a simple model registry, especially when you already have an orchestration setup.
ZenML stands out if you want more than tracking. It gives you pipelines, artifact lineage, reproducibility, and integration across the entire MLOps stack in one place. For teams building long-term ML systems or replacing Neptune with something more future-proof, ZenML offers the most complete foundation while still supporting tools like MLflow inside its pipelines.
Lastly, with ZenML, you don’t have to choose. You can keep using ZenML alongside MLflow (or Neptune, for teams still on it) since ZenML integrates seamlessly with external experiment trackers while providing a stronger, pipeline-first foundation for long-term MLOps.
📚 Relevant comparison articles to read:


