

On this page
Hey ZenML community,
Alex here—it’s been a minute. We skipped a month, so this edition is a little fuller than usual. We’ve been heads‑down strengthening Kubernetes reliability, polishing the developer experience, and running a quick survey on what teams actually need to ship agents and LLM workflows into production. We’re also taking ZenML on the road across the US and Europe in September–October and would love to meet if you’re nearby.
Inside you’ll find highlights from four recent releases, what we learned from last newsletter’s survey responses, a set of practical reads and runnable templates, a scan of what’s happening in AI, and our travel schedule. If there’s something you want more (or less) of in future newsletters, just hit reply—your feedback directly shapes what we write and what we build. And if you enjoy this format, it truly helps to hear that too.
Now, on to the updates.
⚡ Product Updates: Kubernetes that withstands failure, faster pipelines, and Pro service accounts (v0.84.0–0.84.3)
Over July–August we shipped four releases focused on dependable orchestration. Kubernetes runs now restart cleanly and survive failures, pipelines compile faster, debugging is easier in the dashboard, and Pro introduces service accounts for automation.
On Kubernetes, we switched to Jobs for both steps and the orchestrator, added step retries, early pipeline stopping, schedule management, clearer failure reasons, and automatic secret cleanup. Name sanitization across resources keeps clusters compliant, and we now require client and orchestrator images to use the same 0.84.x version.
Developer experience and security also got sharper: a redesigned zenml login supports Pro API keys plus organization/workspace service accounts and external service accounts. We tightened artifact handling with symlink/hardlink validation and remote‑path/Docker‑tag sanitization, improved exception capture and logging reliability, fixed the Vertex step operator credential refresh and Weights & Biases init, and sped up server‑side fetching and large‑pipeline compilation.
The dashboard picked up practical wins: paginated logs with search, copy, and download, and Run Templates moved from raw YAML to a validated form that’s friendlier for non‑infra teammates.
At a glance:
- Resilient, restartable Kubernetes runs with real‑time step status and retries.
- Faster feedback loops: quicker compilation, clearer failures, better logs.
- Safer automation: Pro service accounts and stricter defaults by design.
Upgrade note: if you use the Kubernetes orchestrator, upgrade both client and cluster images to the same 0.84.x version; some legacy pod‑level settings are deprecated due to the move to Jobs.
For the full changelog and examples, see the 0.84.0–0.84.3 release notes.
🔍 Survey insights: What teams need in production
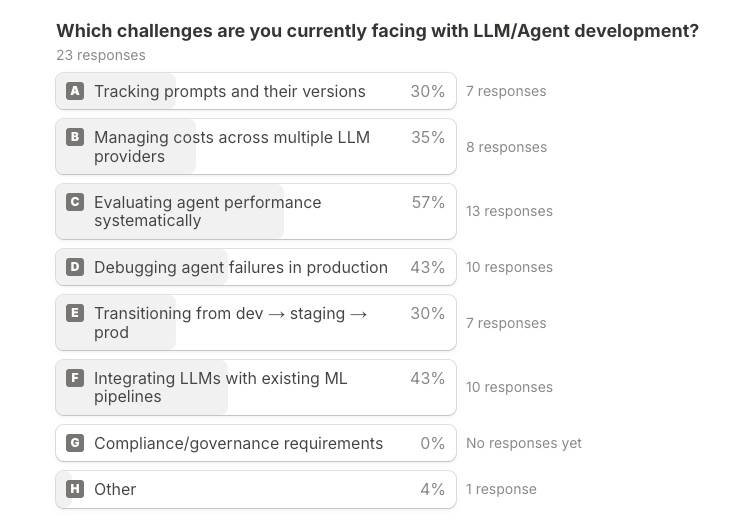
Across 37 responses — mostly hands‑on builders with a meaningful slice already in production — the message was clear: teams don’t want more autonomy, they want control. The biggest friction points are evaluation quality, debugging real production sessions, moving safely from dev → staging → prod, keeping prompts and artifacts versioned alongside code, and seeing (and capping) costs across providers.
How they want to run it reflects that pragmatism. The plurality prefers pipeline/DAG‑oriented orchestration where “agents” are just steps with clear inputs/outputs, scheduling, and guardrails. Long‑running autonomous services do exist, but they’re a minority and skew toward earlier‑stage experimentation; pipeline preference is strongest among teams already shipping to prod.
When asked to prioritize capabilities, one item stood out: a unified LLM Provider component that standardizes calls across providers, captures per‑call cost, and supports automatic fallbacks. Close behind were evaluation (LLM‑as‑judge with simple rubrics and comparison views) and experiment/trace tracking for observability; prompt management (versioning/templating) was just a hair behind those. In short: provider unification, evaluation, and debugging are the top asks.
What that translates to in practical features that you said you wanted:
- Unified provider interface with cost capture, budget guards/alerts, and automatic fallbacks.
- Evaluation that plugs into pipelines: dataset‑backed runs, rubric/LLM‑as‑judge, and before/after comparisons in the UI.
- Observability for debugging: session/trace capture (inputs/outputs, tool calls, latency, tokens/cost) linked to pipeline steps, with import/export to tools like Langfuse/LangSmith.
- Promotion workflow from dev → staging → prod: treat pipeline revisions as promotable artifacts with gated promotion (eval thresholds, cost checks, approvals).
- Prompt management integrated with pipelines: versioned templates, diff/rollback, environment pinning, and approvals.
You all signalled that you were essentially looking for these features yesterday and had timelines clustering around the 1-6 month window. It seems ZenML users are looking to ship!
✍️ Recent work: practical reads and runnable templates
We published a set of pieces focused on closing the gap between “works locally” and “runs reliably in production.”
ZenML’s MCP server now supports DXT, a packaging format that reduces MCP setup from about 15 minutes to roughly 30 seconds via a single archive. It works in Cursor, Claude Code and/or anywhere you can plug in an MCP server, lowering the overhead to ask operational questions about experiments, runs, and costs.
Two essays examine what it takes to deploy agents responsibly. The Agent Deployment Gap outlines where simple loops break — state, long‑running async, authentication, and provider constraints. Production‑Ready AI Agents: Why Your MLOps Stack is the Missing Piece shows how pipelines, versioning, lineage, and evaluation turn agent workloads into auditable, promotable units, with a Postscript case study and how we use Run Templates to expose stable HTTP endpoints. (More on that front coming in the product soon!)
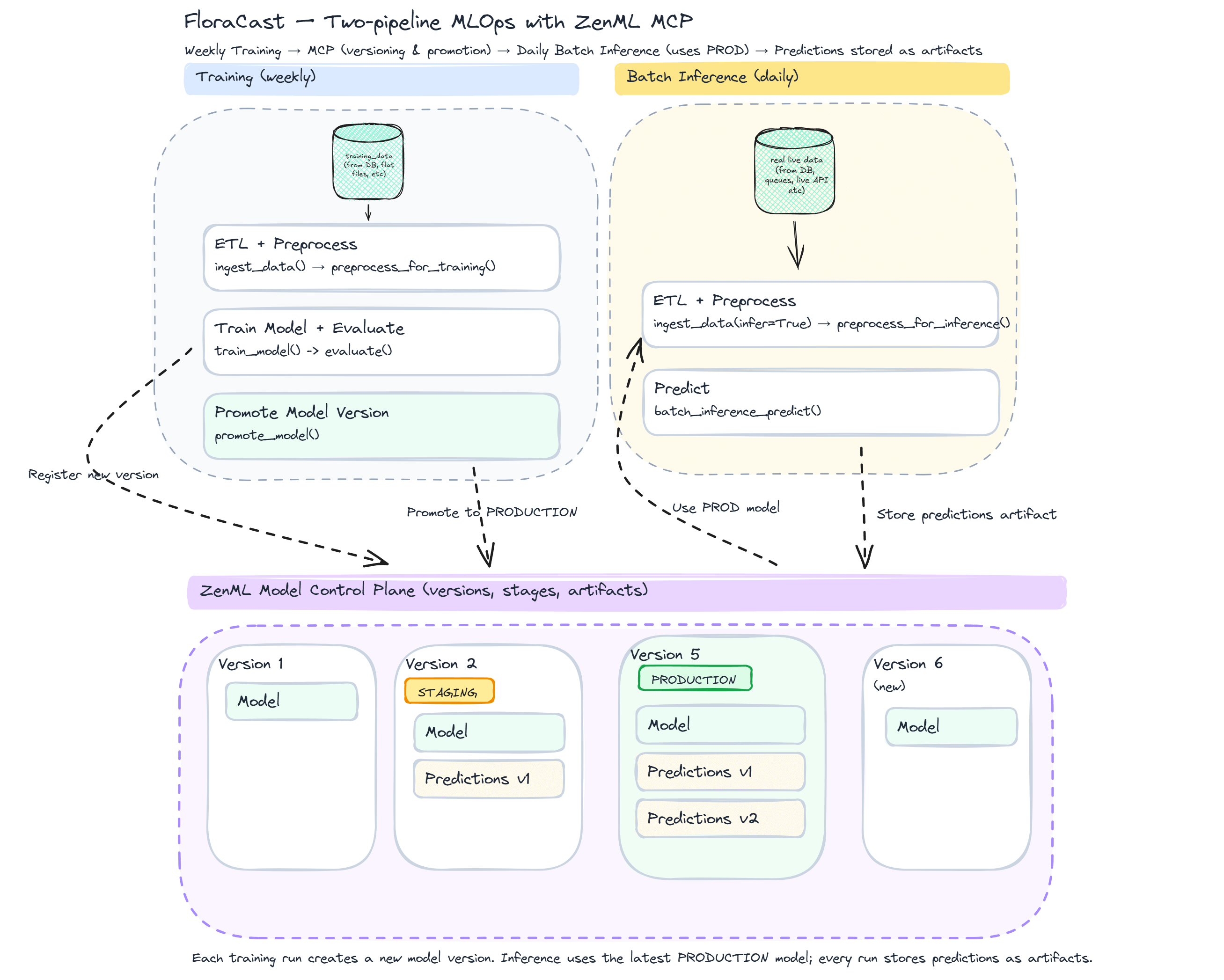
For forecasting operations, Building a Forecasting Platform, Not Just Models documents a two‑pipeline architecture (training and batch inference), automatic promotion based on metrics, and scheduled jobs to keep forecasts current. The emphasis is operational clarity: knowing what’s in production, why it’s there, and how to roll back.
Runnable templates:
- QualityFlow: LLM‑based test generation with multi‑provider support, coverage reporting, and cost metadata.
- FloraCast: time‑series forecasting with versioning, stage promotion, and scheduled batch inference.
🤖 AI in the wild: July–August highlights
This summer split cleanly into two tracks: a sprint toward more releases of reasoning‑centric models and a wave of tooling to actually ship them. On the model front, “reasoning‑only” releases took centre stage with Grok 4 (and 4 Heavy) and a new drop of DeepSeek R1, which community reports pegged as both faster and stronger on benchmarks. NVIDIA entered with OpenReasoning‑Nemotron (1.5B–32B) tuned for math, science, and code, while Kimi’s K2 showed that non‑reasoning models can still excel in structured loops when paired with “sequential thinking.” Outside pure text, Mistral touted best‑in‑class open speech recognition models. Europe also moved: ETH Zurich and EPFL announced a publicly funded LLM trained on the “Alps” supercomputer — an important counterweight for sovereignty and research access.
Tooling and practices evolved just as quickly. Reinforcement Learning re‑entered the mainstream: OpenPipe (acquired by CoreWeave just last week!) publicly pivoted from SFT to RL, arguing it generalizes better from small datasets. The consensus from practitioners is more measured — RL is unlocking wins, but it’s not the whole story, and it amplifies the need for strong evals. That showed up everywhere: eval maturity got attention (from quick Weave demos to purpose‑built libraries like mcpvals for MCP servers), “context engineering” is now table stakes, and posts on AI orchestration laid out how agentic systems stay reliable when wrapped in real pipelines. Meanwhile, developer tools kept racing: Amazon launched Kiro (an agentic IDE), Docker shipped a Model Runner beta for local workflows, and AWS introduced an Agents & Tools marketplace — signs that the dev loop around LLMs is getting more opinionated and integrated.
Industry maneuvering delivered its own drama. Two Claude Code engineers briefly jumped to Cursor before returning to Anthropic, highlighting how hot the coding‑assistant space has become. Anthropic also tightened Claude Code usage limits for heavy users on the Max plan; the community responded with trackers like claudecount.com. Gartner poured cold water on hype with a forecast that more than 40% of agentic AI projects will be canceled by 2027 — less a doomsday prediction than a reminder to ship value, not demos. And OpenAI’s “deep research” API landed with eye‑opening per‑call costs (reports up to $30), reinforcing that teams need budget guardrails alongside capability, and hinting at a strategy that unifies browsing, computer use, and a sandboxed terminal into one agent.
What this means for teams right now:
- Treat evaluation as a first‑class pipeline: dataset‑backed runs, simple rubrics/LLM‑as‑judge, before/after comparisons, and trace capture for latency/tokens/cost. Expensive "deep research"‑style calls need thresholds and alerts.
- Control cost and lock‑in: standardize provider calls behind one interface, record per‑call cost/tokens, and test fallbacks so a single vendor policy change doesn’t stall releases.
- Orchestrate agents as workflows: keep autonomy narrow, push determinism into DAGs, and rely on retries, schedules, and guardrails for reliability.
- Pilot RL pragmatically: start with small, well‑defined objectives and strong eval coverage; don’t replace SFT, extend it where RL’s generalization advantage shows up.
The takeaway: the frontier is reasoning, but production success still looks like good engineering — clear orchestration, strong evals, and cost visibility.
✈️ On the road: September–October
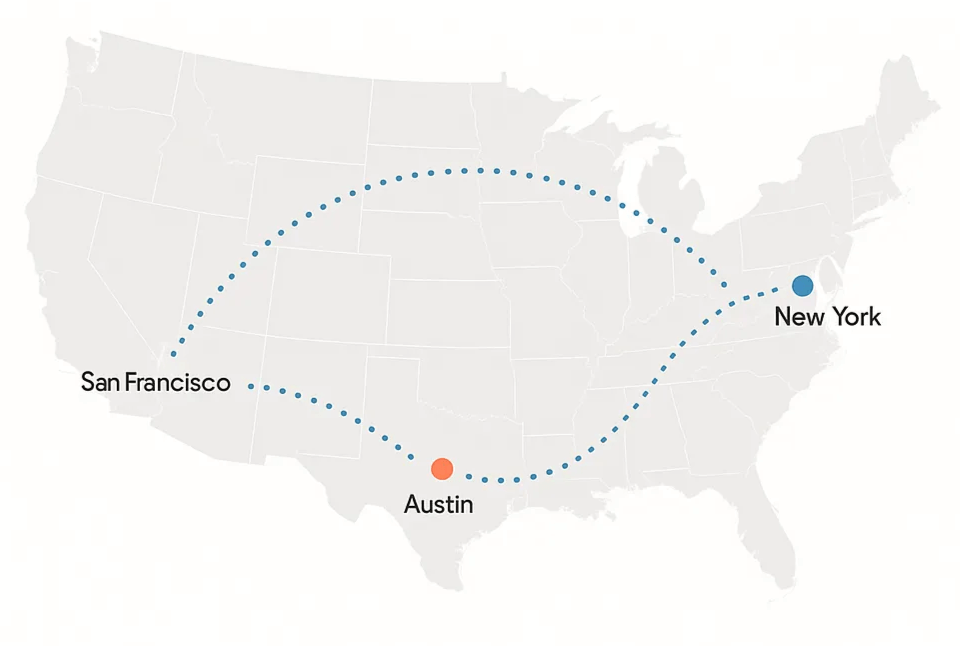
We’re taking ZenML on the road. Adam, Hamza, and the team will be in the Bay Area, New York, Munich, and Austin over the next few weeks. If you’d like a walkthrough of the latest Kubernetes reliability work, evaluation/observability workflows, or if you’re building out agents — or just want to compare notes on your stack — let’s meet.
We kick things off in San Francisco at The AI Conference (September 17–18), hop over to Munich for Bits & Pretzels (September 29–October 1), and then head to Austin for MLOps World (October 8–9). The Bay Area will be our home base through November, so there’s plenty of time for coffees and onsite sessions.
Quick schedule at a glance:
- San Francisco — The AI Conference, September 17–18
- Munich — Bits & Pretzels, September 29–October 1
- Austin — MLOps World, October 8–9
- New York — in town between events; open to team visits and meetups
If you’ll be around any of these, reply to this email and we’ll lock in time. For leaders, we can run a focused session on road‑mapping AI initiatives and the guardrails that keep costs and risk in check. For engineers, we’re happy to dive into pipelines, retries, logging, and deployment patterns — or review your current setup and suggest pragmatic wins.
Closing notes
Thanks for reading. Across the product work, survey insights, and what’s happening in the wild, the throughline is simple: production wins come from clear orchestration, strong evaluation, and costs you can actually see. If you’re building toward that, we’d love to compare notes, sanity-check an architecture, or show you how teams are turning experiments into dependable services.
We’re on the road over the next few weeks and also around the Bay Area through November — reply to this email and we can set up time, or come say hi in our Community Slack.
Until next time,
Alex
P.S. If you made it to the end and want to quietly influence what we build next: we’re exploring a lightweight way to serve and deploy pipelines. If you’re up for sharing a view, this quick survey helps a lot: https://docs.google.com/forms/d/e/1FAIpQLSd6RYUW3LtqHrK5WsVyvjMXex5fnTTGg7nbgfqXHFmuhNID7Q/viewform


