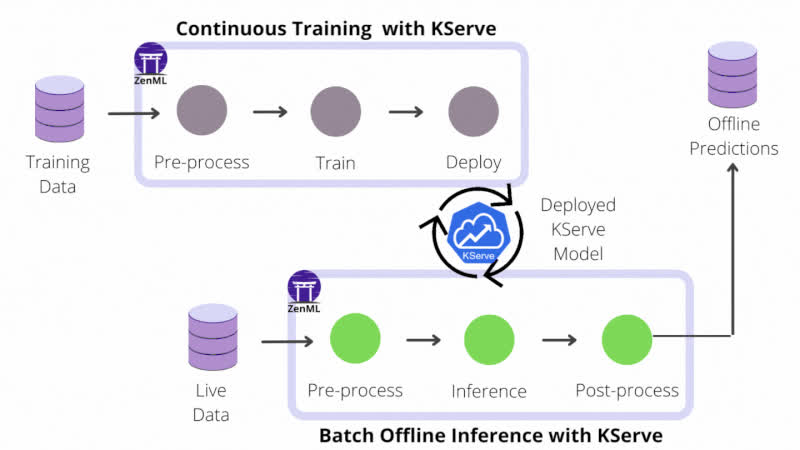
This blog post discusses the integration of ZenML and BentoML in machine learning workflows, highlighting their synergy that simplifies and streamlines model deployment. ZenML is an open-source MLOps framework designed to create portable, production-ready pipelines, while BentoML is an open-source framework for machine learning model serving. When combined, these tools allow data scientists and ML engineers to streamline their workflows, focusing on building better models rather than managing deployment infrastructure. The combination offers several advantages, including simplified model packaging, local and container-based deployment, automatic versioning and tracking, cloud readiness, standardized deployment workflow, and framework-agnostic serving.