On this page
Kedro is a popular open-source framework for structuring data science code into modular pipelines, but it isn’t a one-stop solution for MLOps.
The platform is great at enforcing software engineering practices like standardized project layouts and a data catalog. But leaves critical production needs like workflow orchestration, experiment tracking, and scalable deployment to other tools.
This gap has many ML engineers and data scientists exploring Kedro alternatives that can take their pipelines from prototype to production with less friction.
In this article, we dive into 9 of the best Kedro alternatives, examining how each handles orchestration, artifact and metadata tracking, and scalability, as well as who should use them.
TL;DR
- Why look for Kedro alternatives: Kedro’s lack of built-in scheduling, experiment tracking, and model deployment features means teams often need additional tools. Alternatives address these gaps by providing native workflow orchestration, reproducibility safeguards, and experiment management.
- Who should care: ML and AI engineers and data scientists working on projects that need to scale beyond local runs and into production should evaluate Kedro alternatives.
- What to expect: A detailed comparison of 9 leading tools, categorized by their primary strengths - artifact versioning, pipeline visualization, and orchestration, to help choose the best fit for MLOps needs.
Why Do You Need a Kedro Alternative?

Even though Kedro helps structure pipelines nicely, several pain points push teams to seek an alternative:
Reason 1. Not Actually Made For MLOps
Kedro was not designed as a full-fledged MLOps tool. Its focus is on pipeline authoring (writing clean, maintainable code) rather than pipeline running in production.
Kedro doesn’t include a scheduler or distributed execution engine – it turns your pipeline into a plain Python function, which you then have to deploy on another system to run at scale. This means extra overhead gluing Kedro to ZenML, Prefect, or Kubernetes for any real orchestration.
✅ How ZenML solves it: ZenML provides native orchestration capabilities with built-in scheduling and distributed execution. ZenML includes features like scheduling pipeline runs, adjusting the execution order of steps, and allowing you to automate tasks like training and evaluating ML models, deploying models to production, or running periodic checks. Unlike Kedro, ZenML treats pipelines as first-class citizens, with built-in orchestration that eliminates the need for external tools.
Reason 2. Immature Deployment and Scalability
Because Kedro lacks its own execution engine, deploying Kedro pipelines in a production environment can be clunky. There are plugins to interface with Airflow, Kubeflow, AWS Step Functions, etc., but each integration requires setup and maintenance.
With Kedro, you have to pack your project and manually containerize it for deployment – a process that’s not as smooth as ‘one-click’ deployments offered by some MLOps platforms.
✅ How ZenML solves it: ZenML’s orchestration capabilities work seamlessly with Kubernetes’ advanced GPU scheduling, providing you with the flexibility and power of modern infrastructure while maintaining the simplicity and accessibility that ML teams need. ZenML’s modular stack approach allows you to start locally and scale to production environments without changing your pipeline code.
Reason 3. No Native Artifact Tracking & Data Versioning
Kedro’s Data Catalog tells you where each dataset lives, yet it is not an artifact registry. Versioning is optional; teams must set versioned: true for every dataset, there is no single store that records every output, its checksum, and its lineage across runs. Most projects patch this gap with kedro-mlflow or tools such as DVC.
This gap causes trouble:
- Pipeline outputs can be overwritten
- You cannot prove which inputs produced a given model
- Re-runs on new data create drift that is hard to audit
✅ How ZenML solves it: ZenML writes every dataset, model, and report to an Artifact Store and logs rich metadata in its control plane. The framework versions each artifact by default, records full lineage, and shows it in the dashboard, so you gain reproducibility, caching, diffs, and model promotion without extra plugins.
Evaluation Criteria
When weighing Kedro alternatives, we focused on three key areas aligned with Kedro’s gaps. We tested these alternatives based on real-world scenarios and came up with these three evaluation criteria.
1. Orchestration, Scheduling, and Scalability
Does the tool provide a built-in workflow orchestrator or scheduler so you don’t need an external system like Airflow? Native orchestration means fewer moving parts and unified logging of pipeline runs.
Look for features like:
- DAG engines (directed acyclic graphs of tasks with dependencies)
- Ability to run on a cluster or serverless backends
- Support for parallel execution of tasks
The best alternatives can scale from your laptop to a Kubernetes cluster without much hassle. We also looked for alternatives with reliability features: retry policies, failure notifications, and the ability to queue jobs to avoid overload.
Essentially, the alternative should let you define, schedule, and monitor complex pipelines without needing Kedro + Airflow hacks.
2. Reproducibility and Version Control
Production ML pipelines demand the reproducibility of code, data, and models. Kedro projects rely on Git for code, but Kedro doesn’t version data or artifacts; you have to incorporate tools like DVC or use their own versioning in S3, which is manual.
A strong alternative will automatically version artifacts and datasets, capture run lineage, and possibly offer pipeline lock files or environment snapshots to recreate any result.
For instance, ZenML attaches unique artifact IDs and stores lineage graphs for each pipeline run automatically.
3. Experiment Tracking and Metadata
Since Kedro no longer includes experiment tracking, a valuable alternative will have first-class support for logging metrics, parameters, artifacts, and metadata for each run. This includes providing a UI or API to query past runs, compare results, and perhaps a model registry.
To compile a list of the best Kedro alternatives, we looked for zero-config or easy logging of experiments that come with functionalities like automatically capturing metrics and artifacts without much boilerplate.
What are the 9 Best Kedro Alternatives You Must Try?
With the above criteria in mind, let’s explore the best Kedro alternatives.
| Alternative | Key Features | Best For | Deployment |
|---|---|---|---|
| ZenML | Pipeline-based orchestration, automatic artifact versioning, modular stack architecture, built-in experiment tracking | Teams wanting unified MLOps workflows with minimal glue code | Self-hosted, SaaS |
| MLflow | Comprehensive experiment tracking, model registry, autologging, reproducible MLflow Projects | Experiment tracking and model management alongside existing pipelines | Self-hosted, managed options |
| Weights & Biases | Advanced experiment tracking, interactive dashboards, artifact versioning system, team collaboration | Teams needing superior visualization and collaborative experiment tracking | SaaS, on-premise |
| Prefect | Python-native workflows, real-time execution monitoring, modern web UI, work pools for dynamic infrastructure | Developer-friendly orchestration with minimal DevOps knowledge required | Self-hosted, Prefect Cloud |
| Dagster | Asset-centric pipeline development, software-defined assets, rich metadata tracking, Dagit UI | Teams wanting structured, maintainable pipelines with explicit data dependencies | Self-hosted, Dagster Cloud |
| Vertex AI Pipelines | Fully managed infrastructure, Google Cloud integration, Kubeflow Pipelines UI, automatic scaling | Google Cloud users wanting enterprise-grade managed orchestration | Google Cloud Platform |
| Kubeflow | Kubernetes-native ML workflows, distributed training operators, hyperparameter tuning (Katib), end-to-end ML lifecycle | Complex ML pipelines requiring distributed computing and full ML lifecycle management | Kubernetes clusters |
| Apache Airflow | Battle-tested scheduling, extensive integrations, scalable executor architecture, enterprise-grade reliability | Data engineering teams extending to ML workflows, complex scheduling requirements | Self-hosted, managed services |
| Argo Workflows | Kubernetes-native, lightweight orchestration, artifact passing, DAG and sequential execution modes | Cloud-native teams comfortable with Kubernetes and YAML configurations | Kubernetes clusters |
1. ZenML
ZenML takes a fundamentally different approach than Kedro by treating pipelines as first-class citizens with built-in orchestration, versioning, and deployment capabilities. While Kedro focuses on code organization, ZenML provides a complete MLOps platform that bridges development and production.
ZenML’s Artifact Versioning and Metadata Storage Features
ZenML has comprehensive artifact and metadata tracking baked in. Every time a ZenML pipeline runs, the inputs and outputs of each step are automatically cataloged in ZenML’s metadata store. This means models, data splits, metrics, etc., each get a unique ID and are versioned without extra effort.
Key capabilities include:
- Automatic artifact versioning: Each dataset, model, or file produced by a pipeline step is hashed and stored with a version tag, so you can always retrieve the exact artifact from any prior run.
- Rich metadata capture: ZenML logs metadata like shapes of datasets, model parameters, performance metrics, and more, automatically for each step.
- Run lineage and naming: ZenML maintains lineage graphs linking every artifact to the run, step, and data that produced it.
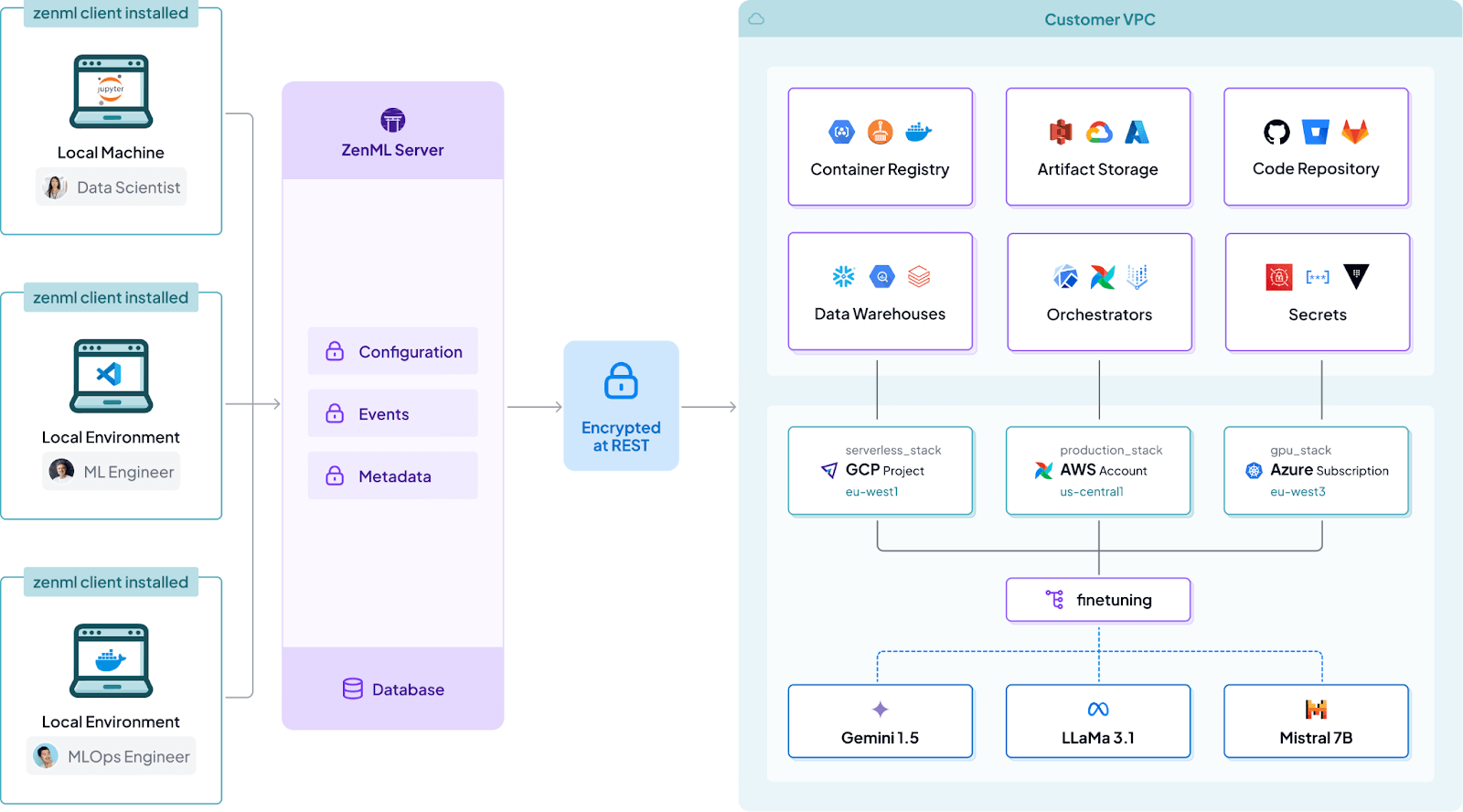
Other Prominent Features
- In ZenML, a stack is a set of components - orchestrator, artifact store, experiment tracker, etc. This modular design is vendor-agnostic and avoids lock-in. You could use an S3 artifact store today and switch to Google Cloud Storage tomorrow by swapping that component, for example.
- ZenML pipelines are just Python, so you can use your normal debugging tools and unit tests on steps. It encourages a test-driven approach to pipeline development.
- ZenML provides a CLI and Python API to run pipelines; it will take care of scheduling task execution and caching results as needed. There’s no need for an external DAG scheduler for basic use cases – it runs locally or on a chosen backend.
Pros and Cons
ZenML can manage pipelines, tracking, and deployment in a single framework. It removes the need to stitch together Kedro + Airflow + MLflow, etc., which simplifies the stack for a team. The platform also lets you develop locally and then run at scale by just changing the orchestrator backend.
However, being a newer framework, ZenML’s community is growing but is currently smaller.
2. MLflow
MLflow provides comprehensive experiment tracking and model management capabilities that many Kedro users adopt to fill the gap left by Kedro-Viz’s deprecated features. While it lacks orchestration, MLflow excels at capturing and organizing ML metadata.
MLflow’s Artifact Versioning and Metadata Storage Features
MLflow’s Tracking component provides comprehensive experiment tracking and artifact management capabilities.
Through simple API calls (mlflow.start_run(), mlflow.log_param/metric/artifact), you can capture parameters, metrics, and artifacts for each training run. The system uses configurable backend storage (blob storage or local) to centrally store all logged artifacts, versioned by run ID.
While MLflow doesn’t provide immutable dataset versioning like DVC or W&B, it records crucial metadata, including Git commit, and supports custom tags.
The Model Registry extends versioning capabilities, which allows you to register models with semantic versions (v1, v2) and promote them through stages.
Other Prominent Features
- MLflow has a concept of MLflow Models and provides tools to deploy those models. For example,
mlflow models servecan deploy a model as a REST API locally, and there are built-in flavors for deploying to SageMaker or Azure ML. - Has the ability to automatically log training parameters and metrics for certain libraries (TensorFlow, Keras, PyTorch Lightning, XGBoost, etc.) using autologging.
- MLflow Projects lets you wrap your code in a reproducible format with an environment specification like a conda YAML or Docker image and an MLproject file.
Pros and Cons
When we ran social checks, we observed that many users praise MLflow for being a go-to solution to track experiments and store models. It’s stable and well-understood. If you’re frustrated that Kedro doesn’t remember your experiment results, MLflow fixes that. Its UI lets you compare runs, and the API is straightforward.
A glaring limitation is that MLflow by itself doesn’t replace Kedro’s pipeline engine. If Kedro’s pipeline DAG is important to you, MLflow alone won’t satisfy that – you’d need to bring in another orchestrator or be okay with more ad-hoc scripts.
<a href="https://www.zenml.io/integrations/mlflow" class="zenml-link" target="_blank">Integrate the power of MLflow's experiment tracking</a> capabilities directly into your ZenML pipelines. Effortlessly log and visualize models, parameters, metrics, and artifacts produced by your pipeline steps, enhancing reproducibility and collaboration across your ML workflows.📚 Related reading:
3. Weights & Biases
Weights & Biases offers advanced experiment tracking with superior visualization capabilities and team collaboration features. The platform goes beyond basic logging to provide interactive dashboards and reports.
Weights & Biases’ Artifact Versioning and Metadata Storage Features
W&B provides experiment tracking similar to MLflow but with a stronger emphasis on dataset and model versioning via its Artifacts system.
In W&B, an ‘artifact’ is a versioned data item – for example, a dataset, a model checkpoint, or any file you want to track.
You can log an artifact to W&B, and it will hash the contents and keep every version (with lineage: which run produced which artifact, etc.). This is extremely useful for data science pipelines: you can have a raw data artifact, a preprocessed data artifact derived from it, a model artifact from training on that data, and W&B will record these relationships.
The platform effectively acts as a version control system for datasets and models.

Other Prominent Features
- W&B provides a powerful UI where you can visualize training curves, compare runs side by side, use custom plots, etc. It’s like getting a live Kedro-Viz + experiment dashboard combined.
- You can create Reports in W&B, which are like interactive documents (markdown plus live results) that showcase findings.
- W&B has integrations with most machine learning libraries and even other pipeline tools.
Pros and Cons
Adding W&B to a project is straightforward – just a few lines, and you get rich logging. Compared to Kedro + MLflow, W&B can feel more seamless, as Kedro’s MLflow integration still requires config, and it doesn’t have as slick a UI as W&B.
A common downside to W&B is that its free tier and even paid tiers have quotas, like the amount of data that can be stored or the duration for which artifacts are kept. Teams that generate numerous large artifacts may quickly reach these limits.
<a href="https://www.zenml.io/integrations/wandb" target="_blank">Integrate Weights & Biases with ZenML</a> to track, log, and visualize your pipeline experiments effortlessly. This powerful combination enables you to leverage Weights & Biases' interactive UI and collaborative features while managing your end-to-end ML workflows with ZenML's pipelines.📚 Related reading:
4. Prefect
Prefect combines Python-native workflow definition with sophisticated visualization and monitoring capabilities. Unlike Kedro’s static pipeline visualization, Prefect provides real-time execution monitoring and debugging tools.
Prefect’s Pipeline Visualization Feature
Prefect offers an excellent web UI (Prefect UI) to monitor and manage your workflows. When you run a flow, Prefect’s UI shows a real-time visualization of the execution: each task in your flow is represented as a node, and you can see which have succeeded, failed, etc., and drill into logs for each task.
The interface is modern and developer-friendly. From a visualization perspective, Prefect has a few key features: It automatically infers the DAG of your @flow from the structure of your code. It then renders this DAG in the UI so you can see the pipeline structure and status at a glance.
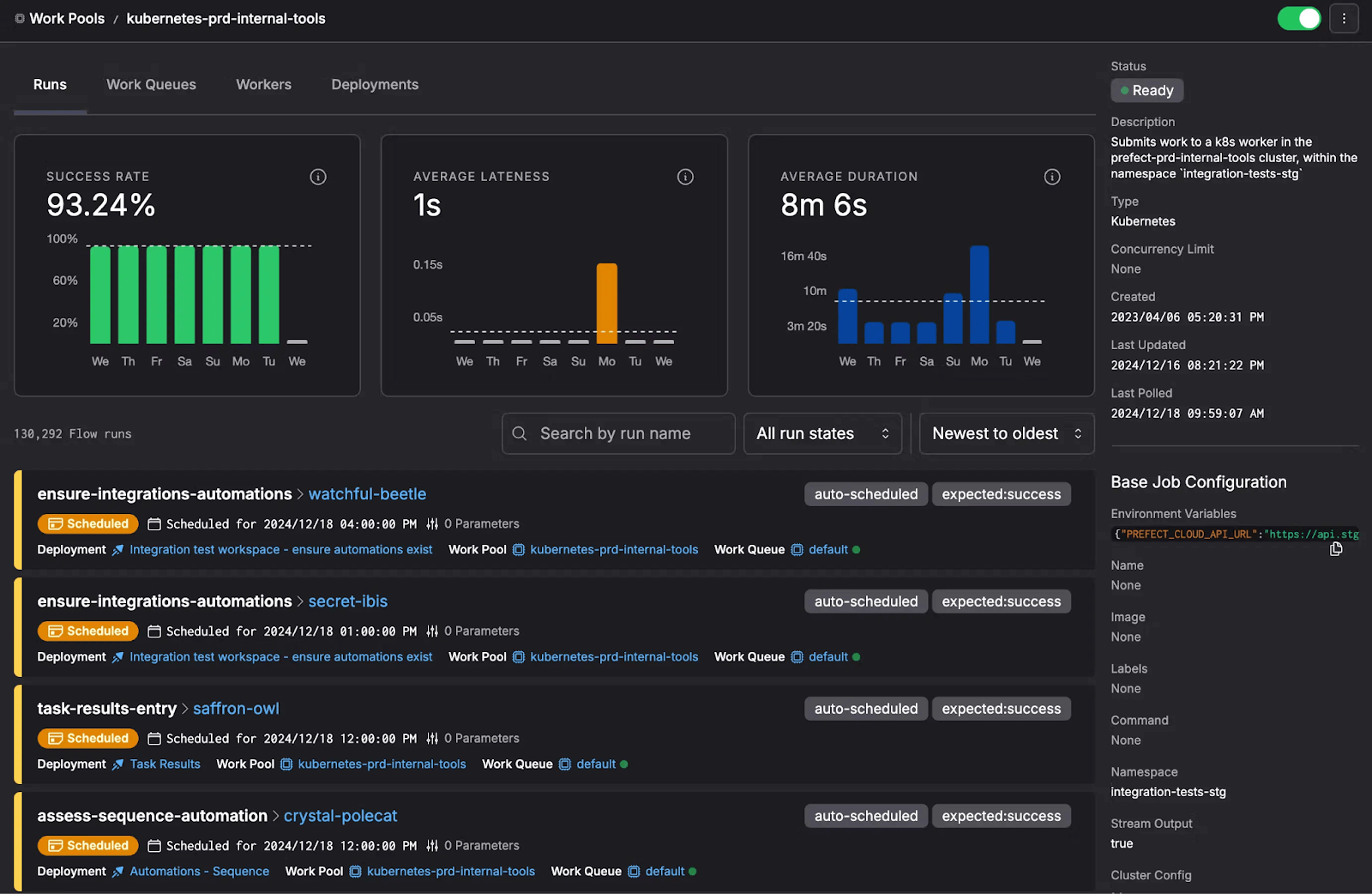
Other Prominent Features
- Separates the control plane - the Orion server, which you can run yourself or use Prefect Cloud - from execution agents. You run a lightweight agent in your environment, and the control plane schedules tasks on those agents.
- Lets you attach schedules (cron-like) to flows with one line of code. It also has built-in retry policies and failure notifications – tasks can automatically retry on failure according to the rules you define.
- Prefect 3.0 introduces ‘work pools’ for dynamic infrastructure provisioning across different environments without changing your pipeline code.
Pros and Cons
Prefect is highly Pythonic and developer-friendly – data scientists can write Prefect flows without deep DevOps knowledge. Prefect Cloud (hosted) provides an easy on-ramp to production orchestration with minimal setup.
But remember, Prefect does not include built-in experiment tracking or model management; you have to go through the hassle of integrating and managing tools like MLflow or W&B to log run metrics and artifacts.
📚 Related reading:
5. Dagster
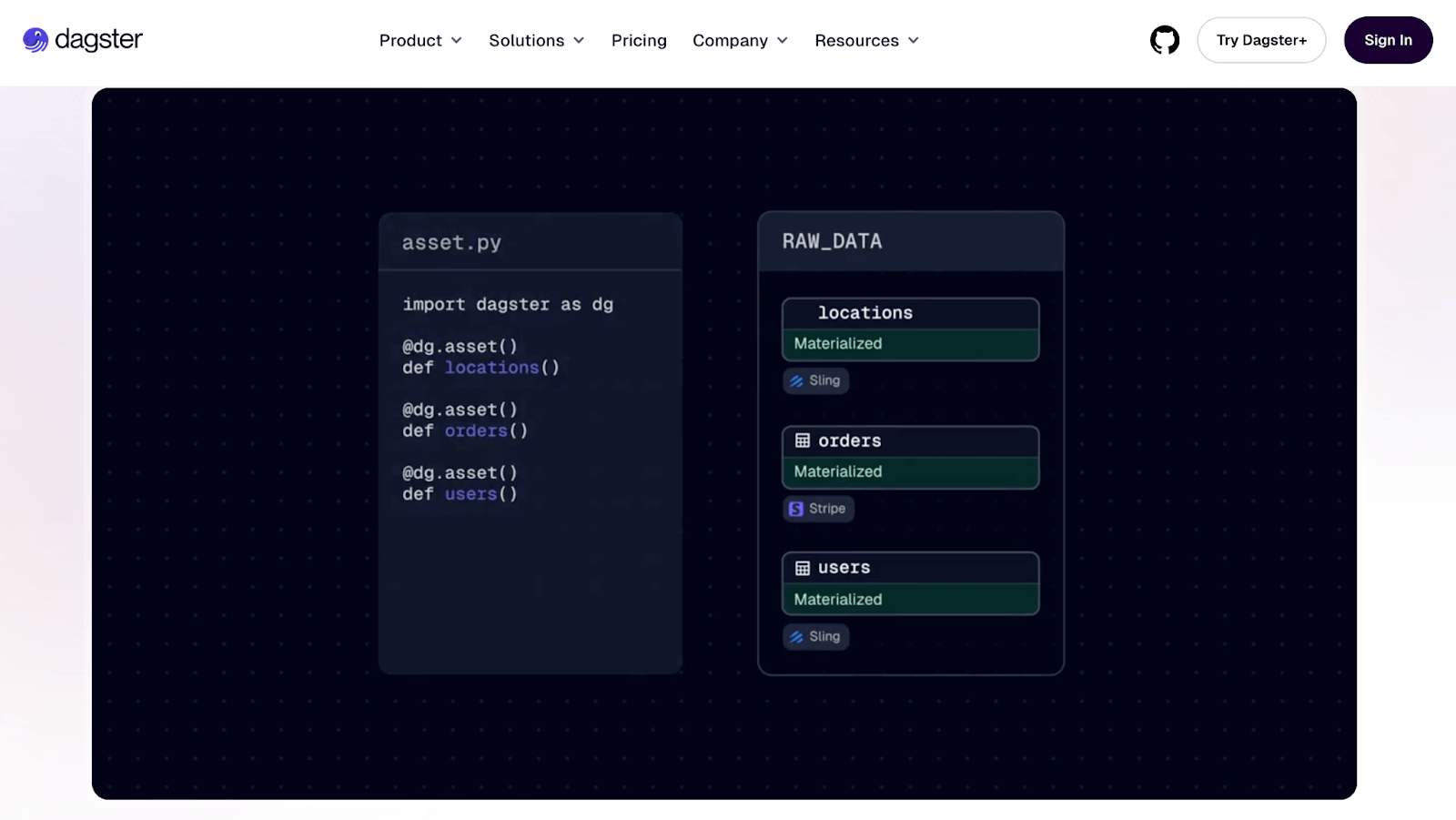
Dagster introduces a unique asset-centric approach to pipeline development that provides a richer context than Kedro’s task-based model. The platform treats data assets as first-class citizens with built-in lineage and quality tracking.
Dagster’s Pipeline Visualization Feature
Dagster’s Dagit UI is one of its strengths for pipeline visualization and interactivity. In Dagit, you can browse your repository of pipelines (or ‘jobs’ in Dagster terms) and see a graph view of each pipeline’s structure, similar to Prefect’s or Airflow’s DAG views.
Dagster’s UI is particularly good at showing the asset graph: if you use Dagster’s software-defined assets API, you get a graph of data asset dependencies, which can sometimes be more insightful than just tasks because it shows how data flows through transformations.
You can click on any asset to see its provenance (what upstream assets it depends on) and its metadata.
In terms of running pipelines, Dagit allows you to launch pipeline runs from the UI easily, with configurable parameters.
Other Prominent Features
- Dagster’s asset abstraction means you can declare assets that get updated by pipelines. Dagster will ensure that if upstream assets change, downstream assets are flagged as outdated.
- You can optionally add types to inputs/outputs, and Dagster can check them at runtime, catching issues early. Its IO managers let you specify how outputs are materialized
- Dagster provides utilities to test pipelines and a CLI to scaffold new projects. The ability to rehydrate or recompute assets for backfills is also built-in, which, combined with the asset catalog, is useful for managing historical recomputation.
Pros and Cons
Dagster provides a structured and robust framework for pipeline development. The focus on data assets and explicit dependencies can lead to more maintainable pipelines in the long run.
But all this functionality of Dagster comes with a steep learning curve. The concepts of assets, ops, jobs, resources, IO managers, etc., mean there is a bit more upfront to learn compared to a simpler tool like Prefect.
6. Google Vertex AI Pipelines
Vertex AI Pipelines provides enterprise-grade pipeline orchestration with deep Google Cloud integration. The platform offers managed infrastructure and automatic scaling that removes operational overhead.
Vertex AI Pipelines’ Visualization Feature
Since Vertex AI Pipelines uses the Kubeflow Pipelines UI, you get a rich pipeline visualization in the cloud console.
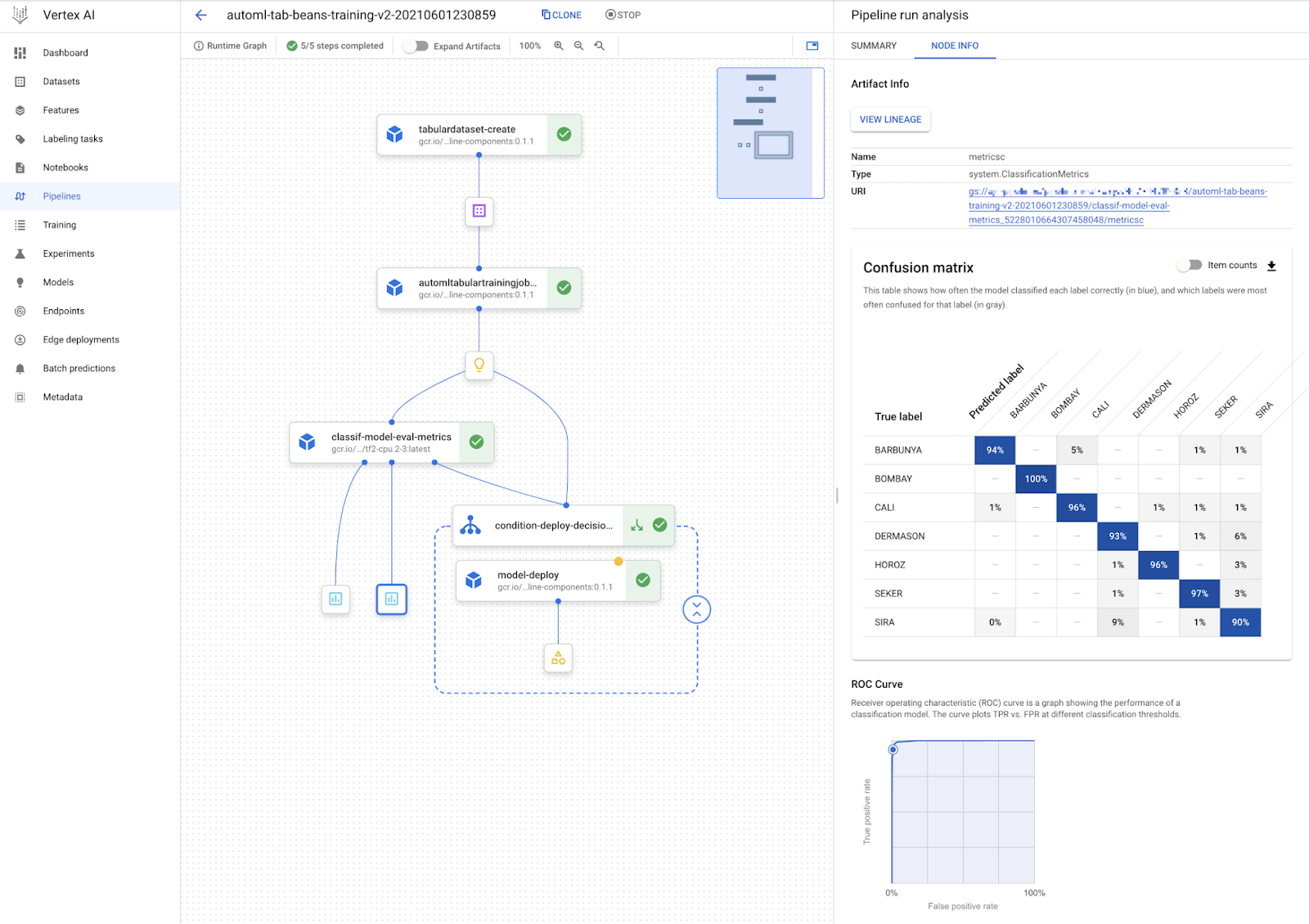
When you open a pipeline run in the UI, you’ll see the DAG of your pipeline, with each step as a node. You can click on any step to see logs, input/output artifacts, and other details.
For ML workflows, Vertex provides specialized visualization capabilities. For example, if you log metrics as part of your pipeline (using Vertex’s metadata SDK or via TensorBoard summaries), the UI can display ROC curves or confusion matrices inline for certain steps.
Additionally, because Vertex AI integrates with Vertex ML Metadata, you can track lineage – the UI displays which datasets and models were consumed or produced by each step.
Other Prominent Features
- Google fully manages the underlying infrastructure. You don’t need to maintain a Kubernetes cluster – Vertex AI Pipelines scales automatically, and you pay per pipeline execution.
- You can upload a pipeline and version it. The platform lets your team reuse pipeline definitions across projects. Additionally, since it’s based on KFP, you can encapsulate steps as reusable components (with inputs and outputs) and share them.
Pros and Cons
Vertex AI Pipelines provides a fully managed, scalable orchestrator with minimal DevOps effort. If you’re on Google Cloud, it integrates seamlessly with your data and compute resources and likely with your security model.
The main con is lock-in to Google Cloud. Vertex AI Pipelines only runs on GCP. If your infrastructure strategy is multi-cloud or on-prem, this won’t help.
Enhance your machine learning operations by leveraging the <a href="https://www.zenml.io/integrations/gcp-vertexai" class="zenml-vertex-link" target="_blank">power of Vertex AI Pipelines orchestration through ZenML</a>. This integration enables you to run production-ready, scalable ML pipelines on Google Cloud Platform, taking advantage of the fully managed serverless infrastructure and intuitive UI for tracking pipeline runs.7. Kubeflow

Kubeflow provides comprehensive ML workflow orchestration on Kubernetes, offering the distributed computing capabilities that Kedro cannot provide natively. The platform includes specialized operators for ML workloads.
Kubeflow’s Pipeline Orchestration Features
At the heart of Kubeflow is Kubeflow Pipelines, a platform for building and deploying portable, containerized ML workflows on Kubernetes.
With Kubeflow Pipelines, you author pipelines in Python using the KFP SDK (or via TFX pipelines). Each step in the pipeline is a containerized task, and KFP handles executing them with the correct sequencing and passing of data.
The Kubeflow Pipelines UI gives a clear view of the pipeline’s DAG and statuses, similar to what we described for Vertex. In terms of orchestration capabilities: Kubeflow Pipelines supports parallel steps, conditional logic, loops, and more, allowing quite complex DAGs for ML.
It also supports caching: if enabled, it can skip executing steps whose inputs haven’t changed from a previous run.
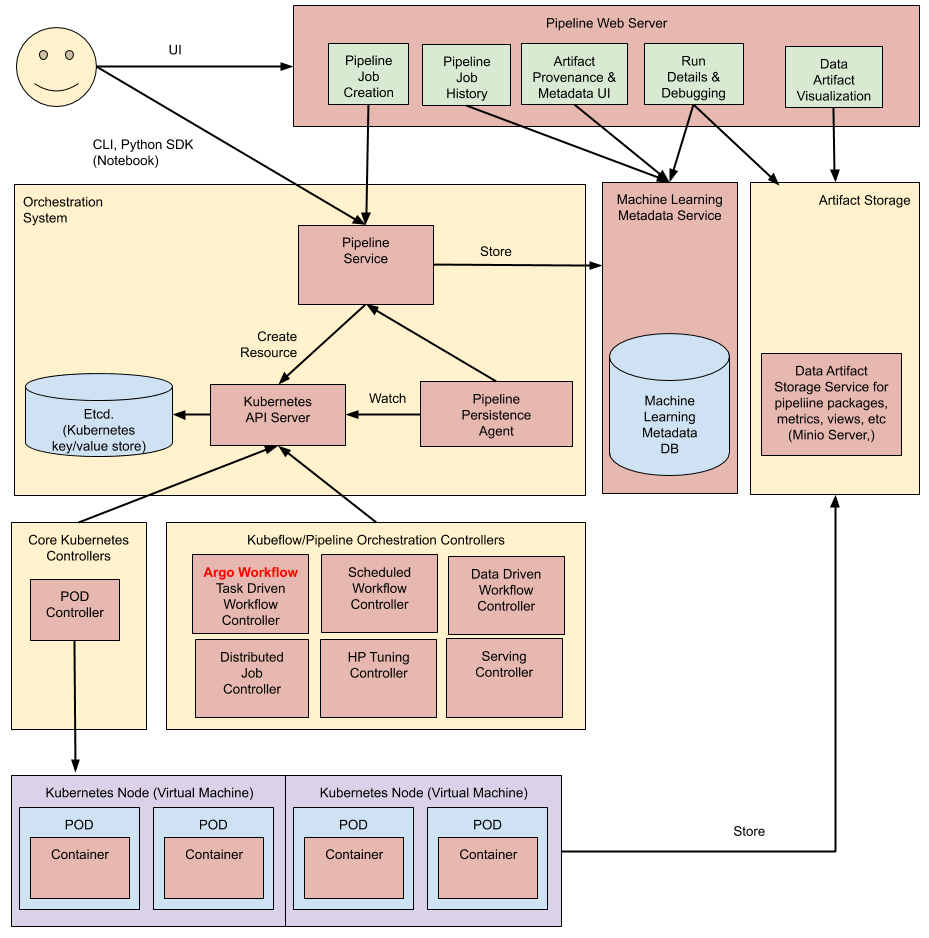
Other Prominent Features
- Kubeflow makes scaling out model training easier through its operators, including TFJob, PyTorchJob, and MXNetJob. Instead of manually handling cluster setup for distributed training, you define a job, and Kubeflow’s operator will launch the appropriate pods on the K8s cluster.
- Kubeflow includes hyperparameter tuning (Katib), which supports various HPO algorithms. This functionality allows you to incorporate Katib experiments into pipelines or run them standalone.
- Kubeflow allows the deployment of Jupyter notebooks in the cluster. Data scientists can use these for development and then, one-click deploy their code to a pipeline.
Pros and Cons
There’s no doubt Kubeflow is extremely powerful and flexible for those who need to run anything from simple to very complex ML pipelines on a Kubernetes cluster. It’s one of the few solutions that covers the entire ML lifecycle: pipeline orchestration, training, hyperparameter search, and serving, all in one platform.
Being an end-to-end platform, Kubeflow is notoriously complex to deploy and maintain. Running Kubeflow means you are managing a lot of moving parts on a Kubernetes cluster; the initial setup can be non-trivial, and upgrades sometimes break due to version compatibility across components.
<a href="https://www.zenml.io/integrations/kubeflow" class="zenml-kubeflow-link" target="_blank">ZenML provides a deep Kubeflow integration</a> that makes deploying ML pipelines on Kubernetes simple, portable and scalable. When you want to take a ZenML pipeline from a local setting to production, you can run it on any infrastructure you like and orchestrate it on Kubernetes via Kubeflow - all without changing a single line of code.📚 Related reading:
8. Apache Airflow
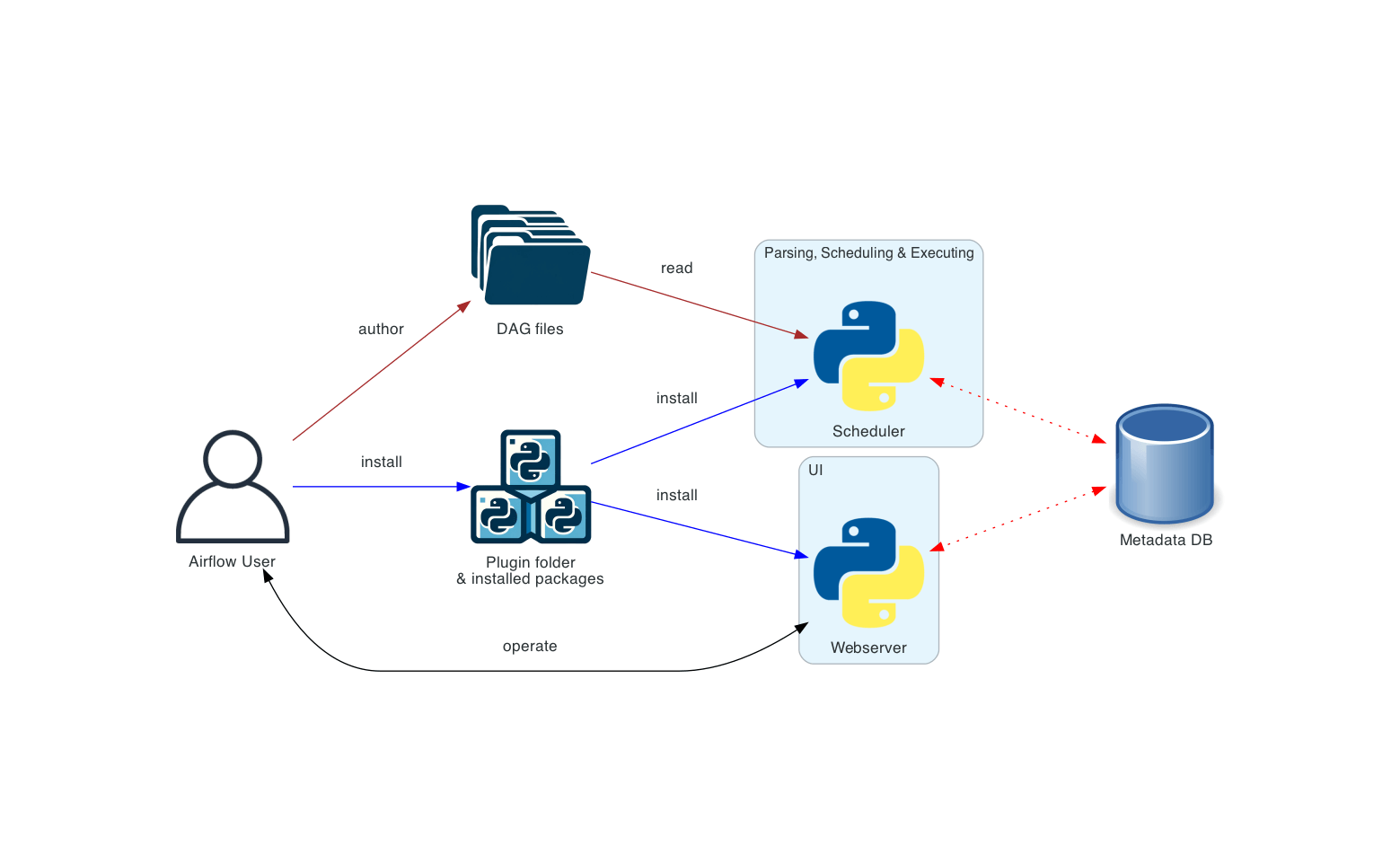
Apache Airflow is one of the most established workflow orchestrators, widely used in data engineering. It’s a platform to programmatically author, schedule, and monitor workflows as DAGs of tasks. While not designed specifically for ML, it’s often used to schedule ML pipelines or data preparation jobs.
Apache Airflow’s Pipeline Orchestration Features
Airflow provides robust scheduling and orchestration for any kind of pipeline, including ML pipelines.
Key features include:
- Time-based scheduling - cron-like or more complex intervals.
- Ability to trigger DAGs manually or via events.
- Dependency management - you define upstream/downstream tasks, and Airflow’s scheduler ensures tasks run in order and handles retries on failure as configured.
Airflow’s executor architecture allows it to scale – you can run it with a LocalExecutor for simple single-machine execution or use the CeleryExecutor or KubernetesExecutor to distribute tasks across many worker nodes or even launch each task in its own Kubernetes pod.
This means Airflow can handle pipelines with hundreds of tasks per day, potentially across a cluster of machines – it’s proven at enterprise scale.
Other Prominent Features
- Airflow’s collection of operators and hooks for external systems is huge. Whatever tools or databases your ML pipeline needs to interact with, Airflow likely has an integration.
- Can handle long-running tasks, set SLA misses, and more. With KubernetesExecutor, each task can fire up its own container, which is great for isolating ML tasks with specific library requirements.
- Airflow allows you to version your DAG definitions via code (usually in Git). If you update a pipeline, Airflow notices and can apply changes.
Pros and Cons
Airflow is a battle-tested orchestrator with a massive user base. It excels at reliably running scheduled workflows and handling complex inter-task dependencies. For teams already doing data engineering, Airflow might already be in use – extending it to ML pipelines is natural.
Airflow was originally created for ETL-type workflows and can feel heavyweight and verbose for ML tasks. The notion of ‘backfill’ and date-based runs, while useful for batch data jobs, can be confusing or irrelevant for some ML workflows.
CLAUDE
📚 Related reading:
9. Argo Workflows
Argo Workflows provides Kubernetes-native workflow orchestration with a focus on cloud-native practices. The platform excels at complex, distributed workflows with advanced control flow.
Argo Workflows’ Pipeline Orchestration Features
Argo Workflows’ key strength is that it is Kubernetes-native and extremely lightweight. To use it, you submit a Workflow CRD to the cluster, which you can do via kubectl or Argo’s CLI or UI, and the Argo controller orchestrates the pods for each step.
Argo orchestration comes with features like - the ability to specify DAG dependencies between steps or just list steps sequentially, support for parallel execution of tasks, and artifact passing between tasks.
Artifact passing between task functionality lets Argo automatically move output files from one step’s container to the input of another via a built-in artifact repository or using volume mounts.
It also supports parameters so you can template your workflows. For example, you might have a workflow that trains a model given a data path and some hyperparameters as inputs – you can submit that workflow with different parameter values without redefining the whole thing.
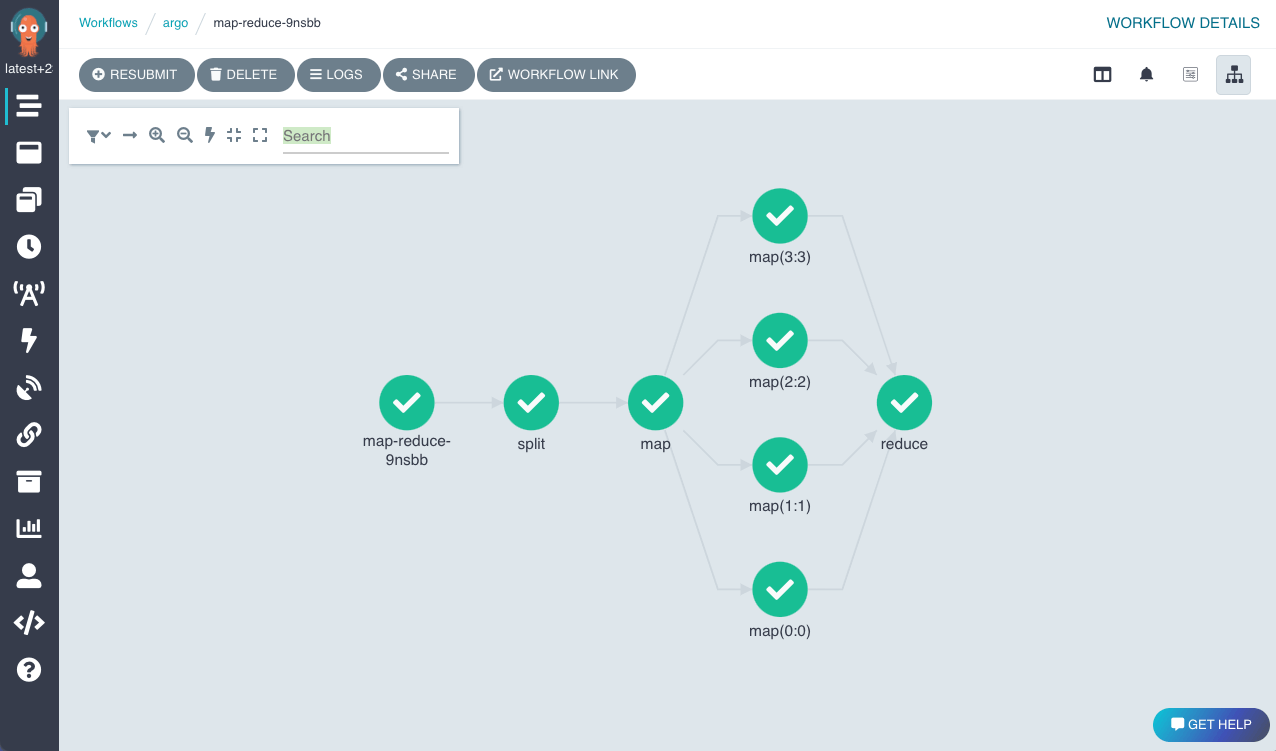
Other Prominent Features
- Argo allows both DAG-style and step-by-step styles. The DAG mode even lets you have a task that depends on multiple previous tasks (join), and Argo will only run it when all dependencies are done.
- Unlike Airflow, Argo doesn’t need an external database or a persistent scheduler service – everything is handled inside Kubernetes.
- Argo can automatically handle moving files. For example, if one step produces a file, you can tell Argo to save it and pass it to downstream steps.
Pros and Cons
Argo Workflows is lightweight, Kubernetes-centric, and developer-friendly for those comfortable with YAML and K8s. It doesn’t bring a lot of baggage – you install it on your cluster, and you’re ready to run pipelines.
However, being low-level, Argo Workflows lacks ML-specific conveniences. For instance, it doesn’t have a built-in experiment tracker or model registry – you’d need to integrate those yourself (e.g., log to MLflow as part of a step).
What’s the Best Kedro Alternative for Building Production-Ready Pipelines?
As we’ve seen, there isn’t a one-size-fits-all answer – each tool has strengths that align with different needs. The good news is these alternatives are not mutually exclusive; you can combine them to tailor an MLOps stack. Here’s a quick recap:
- ZenML (Artifact & Metadata focus, plus orchestration) – Great for teams who want an all-in-one MLOps framework with minimal glue code. It’s especially appealing if you value easy integration of various tools and want to start locally, and then scale up.
- MLflow / Weights & Biases (Experiment Tracking) – If Kedro’s biggest gap for you is experiment tracking and model management, introducing MLflow or W&B will solve that. Use these alongside Kedro to handle the metadata that Kedro doesn’t.
- Prefect / Dagster / Vertex AI Pipelines (Pipeline Visualization & Orchestration) – These are ideal if you want to move beyond Kedro’s local runner and need a pipeline orchestrator with modern dev experience.
ZenML gives you orchestration, artifact versioning, and experiment tracking in one coherent framework, so you move from notebook to cluster without stitching tools together. Spin up a free ZenML open-source workspace today and explore the sample stacks; your first reproducible pipeline will run in minutes, not weeks.
Still confused about where to get started? Book a personalized demo call with our Founder and discover how ZenML can help you build production-ready pipelines with true multi-cloud flexibility.