

On this page
Which application framework should you use for building advanced AI applications – LlamaIndex or LangGraph? Both are powerful in their own right, but they take different approaches.
LlamaIndex originated as an open-source ‘data framework’ (formerly GPT Index) focused on connecting LLMs with your custom data, and it has since grown to include an agent orchestration module.
LangGraph, on the other hand, is a newer framework from the LangChain ecosystem designed to let you explicitly orchestrate complex LLM workflows as graphs and is commonly used in industry for building agents.
In this LlamaIndex vs LangGraph article, we break down the key differences in features, integrations, and use cases for LlamaIndex and LangGraph. We also show how you can potentially use both together (with a tool like ZenML) to get the best of both worlds. Let’s dive in.
LlamaIndex vs LangGraph: Key Takeaways
🧑💻 LlamaIndex: LlamaIndex helps you build agentic workflows to extract information, synthesize insights, and take actions over the most complex enterprise documents. Its fundamental strength lies in connecting LLMs with diverse private or proprietary data sources, enabling these models to effectively reason over and retrieve information. The framework offers tools for data ingestion, indexing, and querying, making it particularly powerful for Retrieval-Augmented Generation (RAG) pipelines.
🧑💻 LangGraph: A framework from the LangChain team for building stateful, multi-agent systems as directed graphs. LangGraph gives developers fine-grained control over agent workflows by representing each step as a node in a graph and connecting them with edges. This allows for complex branching logic, parallel tool calls, looping (cyclical workflows), and shared state across steps.
Framework Maturity and Lineage
The table below compares the framework maturity of LlamaIndex and LangGraph:
| Metric | LlamaIndex | LangGraph |
|---|---|---|
| First public release | v0.0.1 — 9 Nov 2022 | v0.0.9 — 22 Jan 2024 |
| GitHub stars | 43.1 k | 15.8 k |
| Forks | 6.2 k | 2.7 k |
| Commits | 6 800 + | 5 900 + |
| PyPI downloads (last 30 days) | ~ 3.8 M | ~ 7.07 M |
| LangChain dependency | None; built from scratch, independent of LangChain | Built on top of LangChain / uses langchain-core |
| Notable proof points | Used in production by Salesforce, KPMG, Carlyle, Databricks, and more | Adopted by Klarna, Replit, Elastic, LinkedIn, Uber, and more |
👀 Note:* The data in the table above is written as of 18th July 2025 (might vary with time).*
LlamaIndex hit the scene more than a year before LangGraph (Nov 2022 vs Jan 2024), so it naturally enjoys a larger GitHub following : 43k stars vs 15.8k.
Even with fewer stars, LangGraph keeps pace on raw development effort: ~5.9k commits compared to LlamaIndex’s ~6.8k, showing a comparable engineering velocity.
When it comes to real‑world use, LangGraph currently leads in package pulls. It logged ~7.1 million PyPI downloads in the past month, while LlamaIndex landed ~4.0 million. This gap signals heavier deployment traffic flowing through LangGraph‑powered agents right now.
📚 Relevant blogs to read:
LlamaIndex vs LangGraph: Features Comparison
To better understand how LlamaIndex and LangGraph stack up, let’s compare their capabilities across several core features:
| Feature | LlamaIndex | LangGraph |
|---|---|---|
| Agent Orchestration | AgentWorkflow lets a central LLM dispatch tasks to sub-agents or micro-services – great for straightforward, linear flows. | Workflows are explicit graphs; you connect nodes and edges to run steps in parallel, loop, or branch with full developer control. |
| Retrieval-Augmented Generation | Turnkey RAG: hundreds of loaders via LlamaHub, plus built-in indices and retrievers for instant document-aware apps. | Leverages LangChain retrievers; “Agentic RAG” graphs let an agent decide when to fetch, retry, or fall back for richer answers. |
| Observability and Tracing | One-line integrations push traces to GraphSignal/Langfuse, logging every retrieval and LLM call with latency and token stats. | Built-in LangSmith tracing captures each node’s inputs/outputs and supports pause-and-replay for deep debugging. |
| State and Memory Management | The memory module stores recent chat in SQLite and long-term facts in vector or static blocks; minimal setup required. | Checkpointed state after every node, plus semantic, episodic, and procedural memory stores that persist across sessions. |
As you see, LlamaIndex and LangGraph both cover the fundamentals of LLM applications, but they emphasize different strengths. Next, we’ll dive deeper into each of these features for both platforms.
Feature 1. Agent Orchestration
Agent orchestration governs how tasks, tools, and decisions flow, transforming a basic chatbot into a reliable multi-agent system that can achieve complex goals.
LlamaIndex

LlamaIndex’s agent orchestration is provided by the AgentWorkflow system (recently introduced in 2024 as part of the ‘llama-agents’ framework).
This allows you to define multiple agents and how they interact, although the style is quite different from LangGraph’s explicit graphs.
In LlamaIndex, you typically have a central orchestrator agent (often an LLM itself) that can route tasks to other sub-agents or tools based on your instructions or the query.
Essentially, LlamaIndex gives you two approaches:
- Agentic Orchestration: Let an LLM decide the sequence of steps. For example, you can have a high-level agent analyze a user request and decide which tool or sub-agent should handle it next.
- Explicit Orchestration: Define a fixed workflow in code. You can manually sequence agent calls (e.g., first call Agent A, then pass its result to Agent B) using the AgentWorkflow API.
Under the hood, llama-agents adopt a distributed microservice architecture: each agent can run as an independent service with its own process, and they communicate via a message queue and a central controller.
Here’s a simple example of how to set up a basic multi-agent system using llama-agents:
import dotenv
dotenv.load_dotenv() # our .env file defines OPENAI_API_KEY
from llama_agents import (
AgentService,
ControlPlaneServer,
SimpleMessageQueue,
AgentOrchestrator,
)
from llama_index.core.agent import FunctionCallingAgentWorker
from llama_index.core.tools import FunctionTool
from llama_index.llms.openai import OpenAI
import logging
# turn on logging so we can see the system working
logging.getLogger("llama_agents").setLevel(logging.INFO)
# Set up the message queue and control plane
message_queue = SimpleMessageQueue()
control_plane = ControlPlaneServer(
message_queue=message_queue,
orchestrator=AgentOrchestrator(llm=OpenAI()),
)All in all, LlamaIndex’s orchestration is powerful for building multi-agent AI systems with minimal glue code. However, it currently lacks a visual or declarative graph interface – you’re mostly writing Python code to set up agents and their interactions.
LangGraph
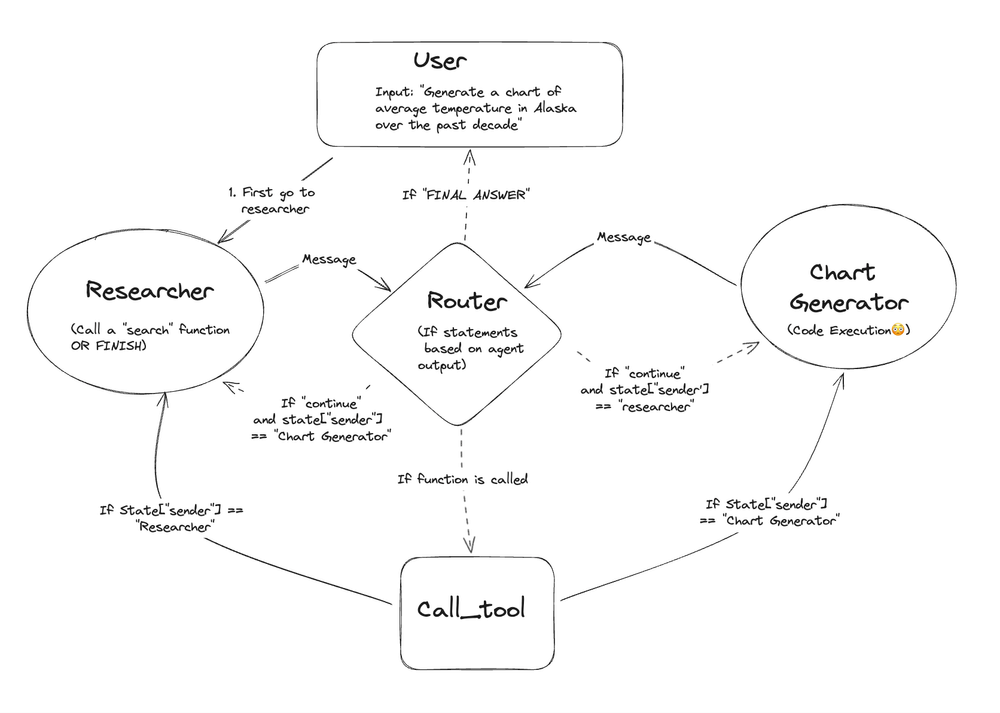
LangGraph is built from the ground up for explicit agent orchestration via graphs. Instead of relying on an LLM to decide the next step implicitly (as in a typical LangChain agent), LangGraph encourages you to lay out the possible steps and transitions an agent can take.
You define a set of nodes – each node could be an LLM call, a tool execution, a conditional check, etc. – and you connect them with edges that determine the flow of execution.
This gives you full control. Let’s understand this with an example.
Suppose you have 4 Nodes - A, B, C, and D. You can run commands like Node A splits into Node B and C (two tasks in parallel), and both must complete before Node D continues.
Some highlights of LangGraph’s orchestration capabilities:
- LangGraph can run multiple nodes concurrently (parallelism), which is great for speeding up workflows.
- You can incorporate decision logic in the graph via conditional branching.
- Unlike many frameworks, LangGraph allows cyclical graphs. Agents can revisit nodes or iterate until a condition is met.
- LangGraph supports multi-agent teams organized hierarchically. For instance, a ‘manager’ agent node could oversee multiple ‘worker’ agent nodes in parallel.
Overall, LangGraph trades some of the ‘fully autonomous’ ease of a purely agentic system (where the LLM just decides everything on the fly) in favor of structure and reliability. You, as the developer, constrain what the agent can do in a graph, which helps avoid unpredictable behaviors and makes debugging easier.
Feature 2. Retrieval‑Augmented Generation (RAG) Pipelines
RAG injects your private data into the model’s context so the agent responds with fresh, factual knowledge instead of hallucinations.
LlamaIndex

One of LlamaIndex’s core strengths is making Retrieval-Augmented Generation easy to implement. In fact, RAG is a primary use case for which LlamaIndex was created. It’s one of the best LLMOps frameworks if you need to integrate your private data securely into LLM prompts.
Key features supporting RAG include:
- Provides data connectors (LlamaHub) to ingest data from numerous sources into its data structures. Whether your knowledge base is in PDFs, Notion docs, web pages, databases, or APIs, chances are there’s a pre-built loader for it in LlamaHub.
- Once data is loaded, LlamaIndex helps you index it for efficient retrieval. Typically, this involves splitting documents into nodes (chunks) and creating embeddings for them. LlamaIndex supports multiple index types, including vector indices for semantic search, keyword tables, and knowledge graphs.
- Offers high-level query engines and retrievers that handle the process of finding the most relevant pieces of your data. You can configure retriever strategies and even chain or route between them.
LangGraph

LangGraph approaches RAG from an agent orchestration perspective. It doesn’t provide data ingestion or indexing utilities itself – instead, it relies on LangChain’s existing capabilities for those. With LangGraph, you would typically:
- Use LangChain integrations to load your data into a vector store using a
FAISSor Pinecone integration outside of LangGraph. - Configure a retriever in LangChain that knows how to query the vector store for relevant docs.
- In your LangGraph workflow, include nodes that call the retriever and then pass documents to the LLM for synthesis.
What LangGraph adds is the ability to make this retrieval process more intelligent and conditional.
For example, LangGraph introduced the concept of Agentic RAG. In a traditional RAG pipeline, every query might unconditionally do ‘retrieve top 5 docs, then answer.’
Agentic RAG means the agent can decide things like: Do I actually need to retrieve anything for this question? If I did retrieve info, was it sufficient, or should I retrieve more? Should I use a different tool (e.g., a web search) if the internal knowledge base fails?
The result is a more adaptive RAG system. Rather than a fixed chain, you have a graph that can respond to the needs of each query.
Bottom line: If your goal is to build a Q&A bot or assistant that knows about your custom data, LlamaIndex might be the perfect solution. It essentially hand-holds you through all stages of RAG: Loading data, Indexing it, Storing the index, Querying it with LLMs, and Evaluating the results.
LangGraph is ideal when you want fine-grained control over the RAG process or need to incorporate RAG as part of a larger agent workflow. If you just need basic document retrieval, then answer functionality, LangChain, or LlamaIndex alone might suffice.
Feature 3. Observability and Tracing
Observability and Tracing capabilities reveal every prompt, tool call, and latency spike and let you debug, track cost, and improve quality before users complain.
LlamaIndex

LlamaIndex offers observability and tracing capabilities, which are crucial for understanding and optimizing LLM applications in production.
The platform lets developers perform basic Python logging for simple inspection of application activity. For more detailed tracking and tracing of internal operations, the framework provides Callback Handlers.
The CallbackManager allows for adding custom callbacks to monitor event duration, frequency, and record trace maps, with LlamaDebugHandler providing default event trace printing.
LlamaIndex also offers a ‘one-click observability’ feature designed for production environments. This enables seamless integration with partner observability and evaluation tools, which allows you to view LLM and prompt inputs/outputs, monitor component performance, and trace calls for both indexing and querying processes.
LangGraph

LangGraph provides robust observability and tracing capabilities primarily through its deep integration with LangSmith, LangChain’s unified observability and evaluation platform.
LangGraph applications can be easily instrumented to send detailed traces to LangSmith. This allows you to visualize the step-by-step execution of agentic workflows, debug non-deterministic LLM behaviors, and understand the agent’s reasoning process.
LangSmith enables comprehensive monitoring of business-critical metrics like costs, latency, and response quality through live dashboards.
What’s more, it also supports evaluating agent performance by saving production traces to datasets and using LLM-as-Judge evaluators or human feedback.
Tracing can be enabled for both LangChain modules used within LangGraph and custom functions or other SDKs by using decorators or wrappers, providing full visibility into the agent’s actions and tool calls.
Bottom line: LlamaIndex acknowledges the need for visibility into agent behavior. It doesn’t just hand off a query to an LLM in a black box; it gives you ways to instrument and inspect the process.
LangGraph assumes you will want to monitor and debug your multi-step agent workflows closely. By integrating with LangSmith, it provides a first-class way to do so. If you’re already in the LangChain world, using LangSmith with LangGraph will feel natural.
Feature 4. State and Memory Management
Solid state and memory preserve past interactions and learned facts, keeping the agent coherent and personalised across long sessions or restarts.
LlamaIndex
LlamaIndex approaches agent memory with a pragmatic, application-driven mindset. The new Memory component introduced in mid-2024 gives a simple API to add conversational memory to any agent. At a high level, it works like this:
You can set the memory for an agent by passing it into the run() method:
from llama_index.core.agent.workflow import FunctionAgent
from llama_index.core.memory import Memory
memory = Memory.from_defaults(session_id="my_session", token_limit=40000)
agent = FunctionAgent(llm=llm, tools=tools)
response = await agent.run("<question that="" invokes="" tool="">", memory=memory)
</question>Short-term Memory
This is essentially the chat history or recent interactions. LlamaIndex will store the messages up to a certain token limit.
By default, it uses an in-memory SQLite database to keep these messages, so you don’t lose them between turns (even if the agent is stateful).
If the conversation exceeds the token limit, LlamaIndex will either drop the oldest messages or move them to long-term memory, depending on your configuration.
Long-Term Memory
For information that needs to persist beyond the context window, LlamaIndex offers memory blocks. There are three types built-in:
- StaticMemoryBlock for immutable facts about the user or environment.
- FactExtractionMemoryBlock automatically extracts key facts from the conversation and stores them in a running list.
- VectorMemoryBlock that uses an embeddings-based store to keep older dialogue chunks and retrieve them when relevant.
You can attach any or all of these blocks to an agent’s Memory. LlamaIndex will then manage what goes into the prompt each turn: it will take the recent short-term messages and, if needed, fetch some relevant long-term memories (like relevant vector hits or static info) to include as context. This hybrid approach gives a nice balance between not exceeding token limits and not forgetting important info.
LangGraph
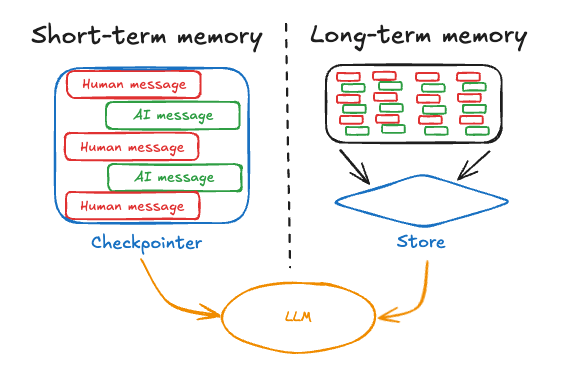
LangGraph treats ‘memory’ and ‘state’ as essentially the same thing: the state of the agent is the container for any memory. This state is automatically persisted through something called a checkpointer.
If an agent is in the middle of a workflow and the process restarts or you want to continue later, LangGraph can reload the last saved state and resume from there – something that’s not trivial to do in other frameworks.
Key aspects of LangGraph’s state/memory management:
Short-Term (Thread-Scoped) Memory
LangGraph defines a concept of a ‘thread,’ which is analogous to a conversation or session. Within a thread, as the agent runs through the graph, its messages and any other variables are stored in the state.
So if you’re building a chat application, the conversation history automatically lives in the state. By default, LangGraph will checkpoint after each node or at defined intervals, so the state is saved to a database. This means if you have a long-running agent or one that you might pause, the full context is not lost.
Long-Term Memory Stores
LangGraph goes a step further by formalizing different types of long-term memory:
- Semantic Memory: Facts or knowledge about the world or user (akin to LlamaIndex’s static block, but can be dynamic as well).
- Episodic Memory: A record of experiences or past episodes.
- Procedural Memory: Rules or how-to knowledge the agent has learned, possibly from feedback or instructions.
LangGraph doesn’t automatically create these memories; it provides an API for you to write and retrieve them as needed.
Bottom line: LangGraph’s approach to memory is holistic and explicit. It treats memory as just part of the workflow state that you can checkpoint, inspect, and modify. This results in great capabilities like truly persistent conversations and the ability to build agents that learn over time, but it also puts more onus on the developer to design how memory is used.
LlamaIndex’s memory module is easy to plug in – you instantiate a Memory with a session ID and maybe some long-term blocks, and just pass it into your agent’s .run() method. The result is that your agent can now handle multi-turn conversations without losing context.
LlamaIndex vs LangGraph: Integration Capabilities
Modern LLM applications rarely live in isolation – they need to integrate with various models, data sources, and other tools. Both LlamaIndex and LangGraph are extensible frameworks that offer a lot of integrations, though again, their focus differs slightly.
| Category | LlamaIndex | LangGraph |
|---|---|---|
| LLMs and Embedding Models |
|
|
| Data Sources |
|
|
| Vector Stores and Storage |
|
|
| Observability and Evals |
|
|
| Deployment and Orchestration |
|
|
| Agent Components/Tooling |
|
|
LlamaIndex

One of LlamaIndex’s biggest selling points is its rich set of integrations for data sources, vector databases, and LLM providers.
LlamaIndex supports integrations with OpenAI, Anthropic, Hugging Face, PaLM, and more LLMs. This means you can plug in your choice of language model easily – whether it’s GPT-4 via OpenAI’s API, Claude via Anthropic, or a local model on Hugging Face.
On the data side, LlamaIndex’s LlamaHub (community-driven) provides over 300 integration packages (often called plugins). These cover everything from specific data connectors like Slack, Notion, Google Drive, databases, to vector store backends like Pinecone, Weaviate, FAISS, Milvus, etc., to even tools and APIs you can call.
FACT: LlamaIndex can also integrate with LangChain itself if needed (they aren’t mutually exclusive).
LangGraph

LangGraph’s integrations are essentially LangChain’s integrations. Since LangGraph is built on top of LangChain’s core modules, it can use any LLM, tool, or vector store that LangChain supports (which is a long list).
Practically, this means:
- LangGraph can work with OpenAI, Anthropic, Hugging Face models, etc., via LangChain’s
LLMabstractions. - Any tool integration (Google search, Zapier, WolframAlpha, you name it) that exists for LangChain can be incorporated as a node in LangGraph.
- For memory and vector stores, LangGraph can utilize LangChain’s memory classes or directly interact with vector stores through LangChain retrievers.
So if you choose LangGraph, you’re inherently choosing the LangChain ecosystem. This is advantageous if you already use LangChain or want to benefit from its extensive community contributions.
LlamaIndex vs LangGraph: Pricing
Both LlamaIndex and LangGraph are open-source projects that you can use for free. However, each also offers managed services/commercial offerings on top of the open-source core, with different pricing models.
LlamaIndex
The open-source LlamaIndex library is MIT-licensed and free to use. You can pip install llama-index and build with it locally or on your own servers without paying anything (aside from costs of the underlying LLM API calls and infrastructure).
LlamaIndex also provides a hosted platform, which offers more and better features. Their pricing (as of 2025) is credit-based:
- Free tier: $0, includes 10k credits (sufficient to try out with smaller workloads).
- Starter plan: $50 per month, includes 50k credits.
- Pro plan: $500 per month, includes 500k credits.
- Enterprise plan: Custom pricing

LangGraph
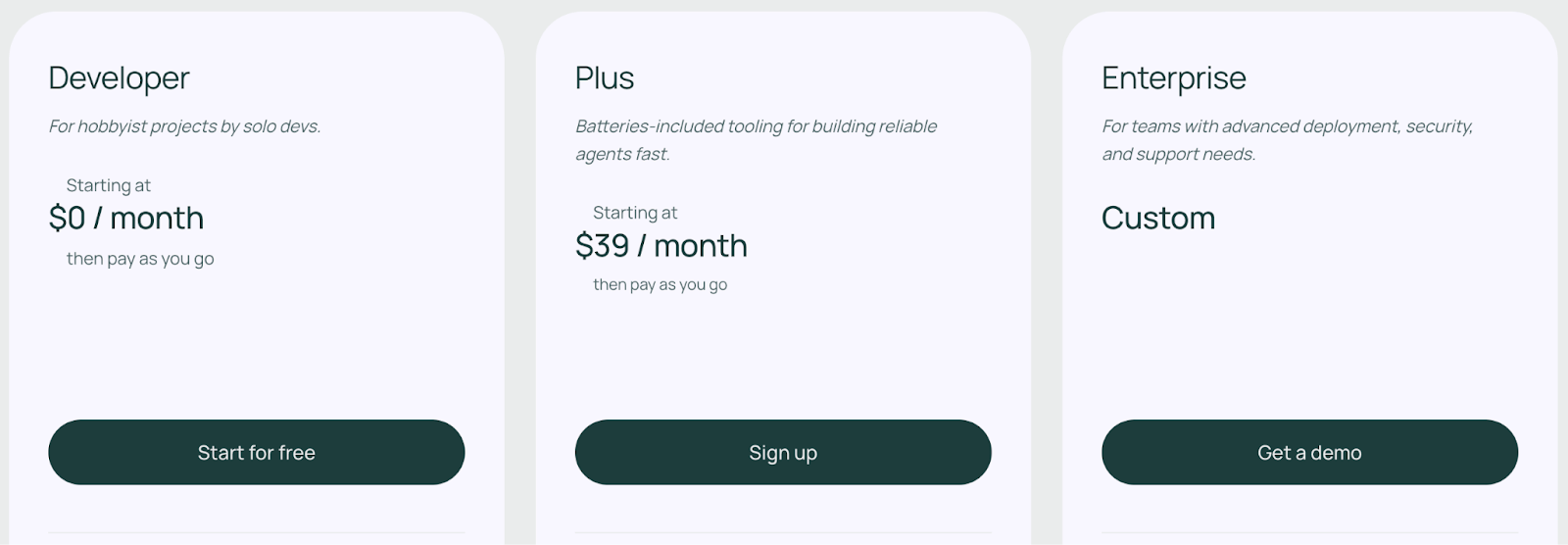
LangGraph comes with an open-source plan that’s free to use. If you install the LangGraph Python or JS package, you get the MIT-licensed code to design agents with no licensing cost or usage fees. This open-source plan has a limit of executing 10,000 nodes per month.
Apart from the free plan, LangGraph offers three paid plans to choose from:
- Developer: Includes up to 100K nodes executed per month
- Plus: $0.001 per node executed + standby charges
- Enterprise: Custom-built plan tailored to your business needs
📚 Relevant article: LangGraph pricing guide.
How ZenML Helps In Closing the Outer Loop Around Your Agents

LlamaIndex and LangGraph excel at the inner loop, which is writing and running an agent. ZenML wraps that agent in the outer loop of production, so you can ship, monitor, and improve it without duct‑tape scripts.
Here’s how ZenML lets you use both LangGraph and LlamaIndex to create the best AI agent possible:
- Embed agents in end‑to‑end pipelines. Any LangGraph or LlamaIndex agent becomes just another step in a ZenML pipeline, alongside data preparation, RAG indexing, or model retraining, so the entire lifecycle runs as a single, reproducible process.
- Unified visibility and lineage. ZenML auto‑tracks every run, prompt, and artifact, giving a single dashboard that shows all your agents and how they connect to upstream data and downstream services.
- Continuous quality checks. Built-in evaluators fire after each execution, letting you spot a ‘bad’ agent run and trigger feedback loops or rollback, something the inner‑loop tools don’t cover.
- Glue across stacks. Its components-and-stacks model lets you mix LangGraph, LlamaIndex, classic ML, or any other tool in one coherent workflow, avoiding vendor lock-in while keeping everything version-controlled.
In short, LlamaIndex and LangGraph define what the agent does; ZenML governs how that agent lives, evolves, and scales in production.
📚 Other comparison articles worth reading:
Which LLOps Platform Is Best For You?
Choosing between LlamaIndex and LangGraph really comes down to your specific needs and project context. Here are some guidelines:
✅ Choose LlamaIndex if your primary goal is to build a data-aware LLM application quickly. It’s fantastic for scenarios like chatbots, Q&A systems, or assistants that need to pull information from custom documents.
✅ Choose LangGraph if you need fine-grained control over multi-step reasoning or multi-agent interactions. For building complex agent workflows – say an AI system that plans tasks, calls various tools in parallel, iterates on results, etc. – LangGraph provides the structure and reliability to do it safely.
ZenML brings every ML and LLM workflow - data prep, training, RAG indexing, agent orchestration, and more - into one place for you to run, track, and improve these workflows. You can use LlamaIndex and/or LangGraph within ZenML!
Join the early‑access waitlist today below and be the first to build on a single, unified stack for reliable AI. 👇🏻


