
Accelerate NLP and Computer Vision with Hugging Face Models in ZenML Pipelines
Integrate the state-of-the-art pre-trained models from Hugging Face into your ZenML pipelines for powerful NLP and computer vision capabilities. Leverage the extensive Hugging Face model hub directly within your ML workflows, enabling efficient transfer learning and rapid prototyping.
from typing import Tuple
from zenml import pipeline, step
from zenml.integrations.huggingface.steps import run_with_accelerate
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
Trainer,
TrainingArguments,
DistilBertForSequenceClassification,
)
from datasets import load_dataset, Dataset
@step
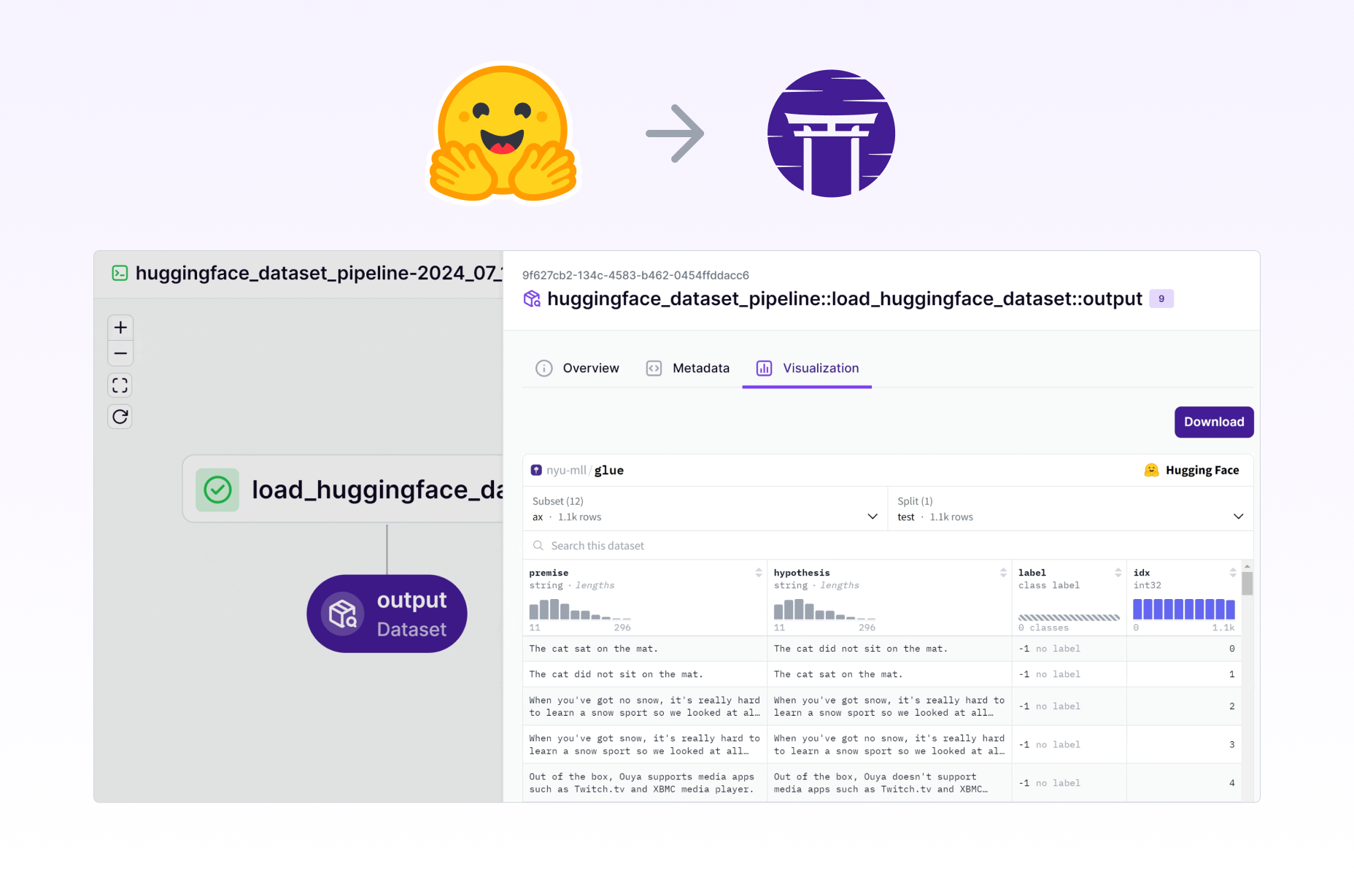
def prepare_data() -> Tuple[Dataset, Dataset]: # Return any Huggingface dataset
dataset = load_dataset("imdb")
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
return (
tokenized_datasets["train"].shuffle(seed=42).select(range(1000)),
tokenized_datasets["test"].shuffle(seed=42).select(range(100)),
)
@run_with_accelerate(num_processes=4, multi_gpu=True) # Distribute workload with accelerate
@step(enable_cache=False)
def train_model(
train_dataset: Dataset, eval_dataset: Dataset
) -> DistilBertForSequenceClassification:
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2
)
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
trainer.train()
return model # Return any HF model to track it
@pipeline
def fine_tuning_pipeline():
train_dataset, eval_dataset = prepare_data()
model = train_model(train_dataset, eval_dataset)
if __name__ == "__main__":
fine_tuning_pipeline()
Expand your ML pipelines with more than 50 ZenML Integrations