
Your GPUs Are Everywhere. Your Robot-Learning Loop Shouldn't Be.
Robotics compute is spreading across clouds and clusters. Learn how one portable pipeline layer can keep the robot-learning loop reproducible.
DVC is excellent at versioning datasets and models alongside Git, with strong experiment workflows and reproducible pipelines. ZenML is an open-source MLOps framework that orchestrates the full lifecycle: pipelines, artifact/metadata tracking, and integrations across environments. If you've standardized on DVC for reproducibility but need production orchestration and lifecycle coordination, ZenML is the next layer up.


“ZenML has proven to be a critical asset in our machine learning toolbox, and we are excited to continue leveraging its capabilities to drive ADEO's machine learning initiatives to new heights”

François Serra
ML Engineer / ML Ops / ML Solution architect at ADEO Services
Feature-by-feature comparison
| Workflow Orchestration | ZenML is built to orchestrate multi-step ML pipelines across environments using swappable stack components, not just reproduce local command graphs. | DVC provides lightweight DAG execution via dvc.yaml + dvc repro, but it's primarily local and relies on external schedulers/CI for production orchestration. |
| Integration Flexibility | ZenML's stack architecture is designed to plug in best-of-breed tools (orchestrators, trackers, deployers, registries) without rewriting pipelines. | DVC integrates well with Git and storage backends, but doesn't offer a composable stack of interchangeable orchestration/deployment/monitoring components. |
| Vendor Lock-In | ZenML is cloud-agnostic by design: it can run on multiple clouds or on-prem by swapping stack components. | DVC core is Apache-2.0 OSS and can use many storage systems as remotes; DVC Studio is optional for teams that want a hosted UI. |
| Setup Complexity | ZenML can start locally quickly and scales by adding stack components incrementally as teams grow. | DVC is easy to bootstrap in an existing repo: install the CLI, dvc init, and optionally configure a remote; no server component is required. |
| Learning Curve | ZenML's learning curve pays off for teams building repeatable production pipelines with stacks, artifacts, and metadata concepts. | DVC's mental model maps closely to Git + build tools: version artifacts with pointers, define stages in dvc.yaml, and reproduce with dvc repro. |
| Scalability | ZenML scales by delegating execution to production orchestrators and managed services while keeping pipeline code portable across environments. | DVC scales well for large datasets via remotes and caching, but production workload orchestration typically requires pairing DVC with CI systems or other orchestrators. |
| Cost Model | ZenML's OSS core is free; managed offerings shift cost from infra/time to subscription for teams needing centralized governance and collaboration. | DVC core is free OSS (Apache-2.0); DVC Studio offers a free tier for individuals/small teams with paid options for larger teams. |
| Collaboration | ZenML emphasizes team collaboration through shared stacks, centralized metadata/lineage, and integration points for registries and dashboards. | DVC collaboration is Git-native (branches/PRs) and enhanced by DVC Studio, which adds experiment visualization, sharing, and team features. |
| ML Frameworks | ZenML integrates across many ML libraries and platforms while standardizing how artifacts/metadata flow through pipelines. | DVC is framework-agnostic (stages are commands), and DVCLive provides built-in integrations across many popular ML frameworks. |
| Monitoring | ZenML connects the training pipeline to production concerns including deployment and downstream monitoring integrations as part of an MLOps stack. | DVC focuses on tracking training-time experiments, metrics, and artifacts; it does not provide production inference monitoring out of the box. |
| Governance | ZenML's centralized metadata, lineage, and reproducibility primitives are designed to support governance requirements across environments and teams. | DVC provides strong auditability via Git history, but enterprise governance (RBAC, policy enforcement, audit workflows) depends on Git hosting and optional Studio features. |
| Experiment Tracking | ZenML can integrate with dedicated experiment trackers and also tracks pipeline runs and artifacts in a metadata store for end-to-end lineage. | Experiment tracking is a core DVC strength: experiments are stored as custom Git refs, runnable via dvc exp run, and enhanced with DVCLive + DVC Studio. |
| Reproducibility | ZenML provides reproducibility through tracked artifacts, caching, and lineage in a metadata store, even when execution moves across environments. | Reproducibility is foundational: DVC pipelines capture dependencies/outputs and reproduce results with dvc repro, with data/models versioned via cache + remotes. |
| Auto-Retraining | ZenML is designed for scheduled/triggered pipelines using orchestrators and CI/CD integrations, enabling automated retraining patterns. | DVC can participate in auto-retraining when paired with CI schedulers and CML, but does not provide a native always-on retraining orchestrator. |
Code comparison
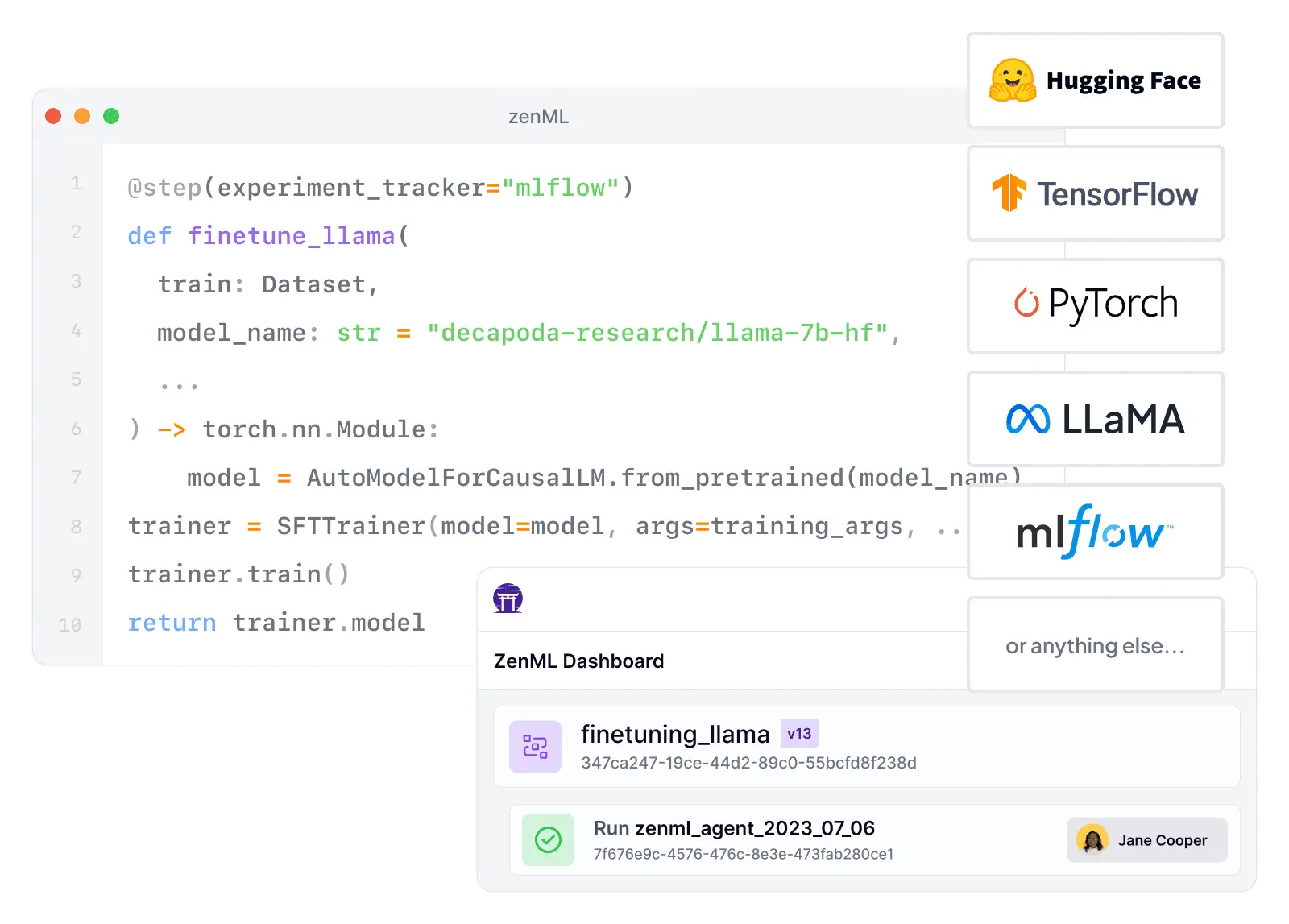
from zenml import pipeline, step
@step
def load_data():
# Load and preprocess your data
...
return train_data, test_data
@step
def train_model(train_data):
# Train using ANY ML framework
...
return model
@step
def evaluate(model, test_data):
# Evaluate and log metrics
...
return metrics
@pipeline
def ml_pipeline():
train, test = load_data()
model = train_model(train)
evaluate(model, test)import csv
import numpy as np
import dvc.api
from dvclive import Live
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import accuracy_score
import joblib
# Stream a versioned dataset snapshot from DVC remote
with dvc.api.open("data/train.csv", rev="v1.1.0") as f:
rows = list(csv.DictReader(f))
X = np.array([[float(r["f1"]), float(r["f2"])] for r in rows])
y = np.array([int(r["label"]) for r in rows])
clf = SGDClassifier(loss="log_loss", random_state=42)
with Live() as live:
for _ in range(5):
clf.partial_fit(X, y, classes=np.unique(y))
live.log_metric("train/accuracy", float(accuracy_score(y, clf.predict(X))))
live.next_step()
joblib.dump(clf, "model.joblib")
ZenML is fully open-source and vendor-neutral, letting you avoid the significant licensing costs and platform lock-in of proprietary enterprise platforms. Your pipelines remain portable across any infrastructure, from local development to multi-cloud production.

ZenML offers a pip-installable, Python-first approach that lets you start locally and scale later. No enterprise deployment, platform operators, or Kubernetes clusters required to begin — build production-grade ML pipelines in minutes, not weeks.

ZenML's composable stack lets you choose your own orchestrator, experiment tracker, artifact store, and deployer. Swap components freely without re-platforming — your pipelines adapt to your toolchain, not the other way around.
Expand Your Knowledge
Robotics compute is spreading across clouds and clusters. Learn how one portable pipeline layer can keep the robot-learning loop reproducible.

Claude Agent SDK runs the agent loop. Kitaru adds the durable runtime around a completed invocation — checkpointed results, artifacts, replay boundaries, and waits.

LangGraph keeps graph state, threads, and interrupts. Kitaru adds the durable workflow around the graph call — replay boundaries, durable waits, and inspectable runs.
