

On this page
Today, LLM applications demand high-level observability. When an AI agent misfires, you need to quickly find the root cause of the issue, whether it’s a flawed prompt, a slow tool call, or a model hallucination.
Langfuse and Phoenix (developed by Arize AI) are two leading open-source platforms designed for LLM observability.
Both cover the fundamentals well. That is, the basics of tracing multi-step prompts and logging model interactions. However, they differ in philosophy and approach.
In this article, we compare Langfuse vs Phoenix head-to-head across features, integrations, and pricing to determine which fits best in your LLM stack.
Langfuse vs Phoenix: Key Takeaways
🧑💻 Langfuse: An open-source, framework-agnostic observability with deep tracing, evaluations, and prompt management. Captures prompts, tool calls, tokens, latency, and cost with SDKs for Python/JS. It’s ideal for teams that want tight control and a production-ready, community-backed option.
🧑💻 Phoenix: An open-source observability from Arize focused on fast, local debugging. Built on OpenTelemetry and runs in notebooks or Docker with free prompt playgrounds and LLM-as-judge evals. It’s best for RAG troubleshooting with retrieval/relevance views and an easy path to Arize Cloud.
Langfuse vs Phoenix: Maturity and Lineage
An understanding of each platform’s corporate lineage explains its core feature focus and open-source strategy.
The table below compares the maturity and ecosystem growth of Langfuse and Phoenix:
| Metric | Langfuse | Phoenix |
|---|---|---|
| First Release | May 2023 | April 2023 |
| GitHub Stars | 7.7k | 18.2k |
| Forks | 619 | 1.8k |
| PyPI Downloads | ~7.8 million | ~3 million |
| Commits | 5594 | 6733 |
Langfuse launched in May 2023 as a community-driven, open-core observability tool and has since become one of the most popular open-source choices for LLM monitoring.
Phoenix, introduced a month later, grew quickly on the strength of Arize’s existing ML observability reputation. Its tight integration with Arize’s platform gives teams a smooth path from local debugging to enterprise-grade monitoring.
Both are maturing fast. However, Phoenix shows better community adoption with higher commits and GitHub stars than LangFuse.
Langfuse vs Phoenix: Features Comparison
Both platforms share similar features, but they differ in implementation and depth. Here’s a quick comparison table:
| Parameter | Langfuse | Phoenix |
|---|---|---|
| Core Philosophy | Open-source platform focusing on production observability, analytics, cost tracking, and prompt management. | Open-source platform prioritizing evaluation, RAG tracing, and developer experimentation. |
| Tracing and spans | Full hierarchical trace timelines with nested spans, grouping by session or user. Captures each LLM call, tool use, latency, and cost with OpenTelemetry SDKs. | Automatically captures traces using built-in OTel instrumentation. Focuses on local debugging with clear span timelines and visual heatmaps for performance. |
| OpenTelemetry | Native OTel backbone with SDKs and ingestion API for Python, JS, and others. Works with any existing OTel collector or APM (Jaeger, Datadog). | Natively OTel-compliant with OpenInference, enabling one-line auto-instrumentation (phoenix.otel.register()).Optimized defaults for Python workflows. |
| Multi-agent functionality | Purpose-built for multi-agent tracing. Features an Agent Graph view showing how agents and tools interact in DAG form. Integrates with LangGraph, CrewAI, AutoGen, and BeeAI. | Logs multi-agent workflows through OTel spans. However, it is limited to timeline views without graph visualization. |
| Prompt management | Built-in versioning, tagging, and GitHub sync. Includes a Prompt Playground for A/B testing and caching across model versions. | Open-source Prompt Playground for designing, comparing, and replaying prompts. Enables span replay and dataset-based evaluation within notebooks. |
Feature 1. Tracing and Spans
Observability in LLM applications begins with detailed tracing, which captures the execution path of a single request. Both Langfuse and Phoenix use hierarchical data models inspired by OpenTelemetry (OTel).
Langfuse
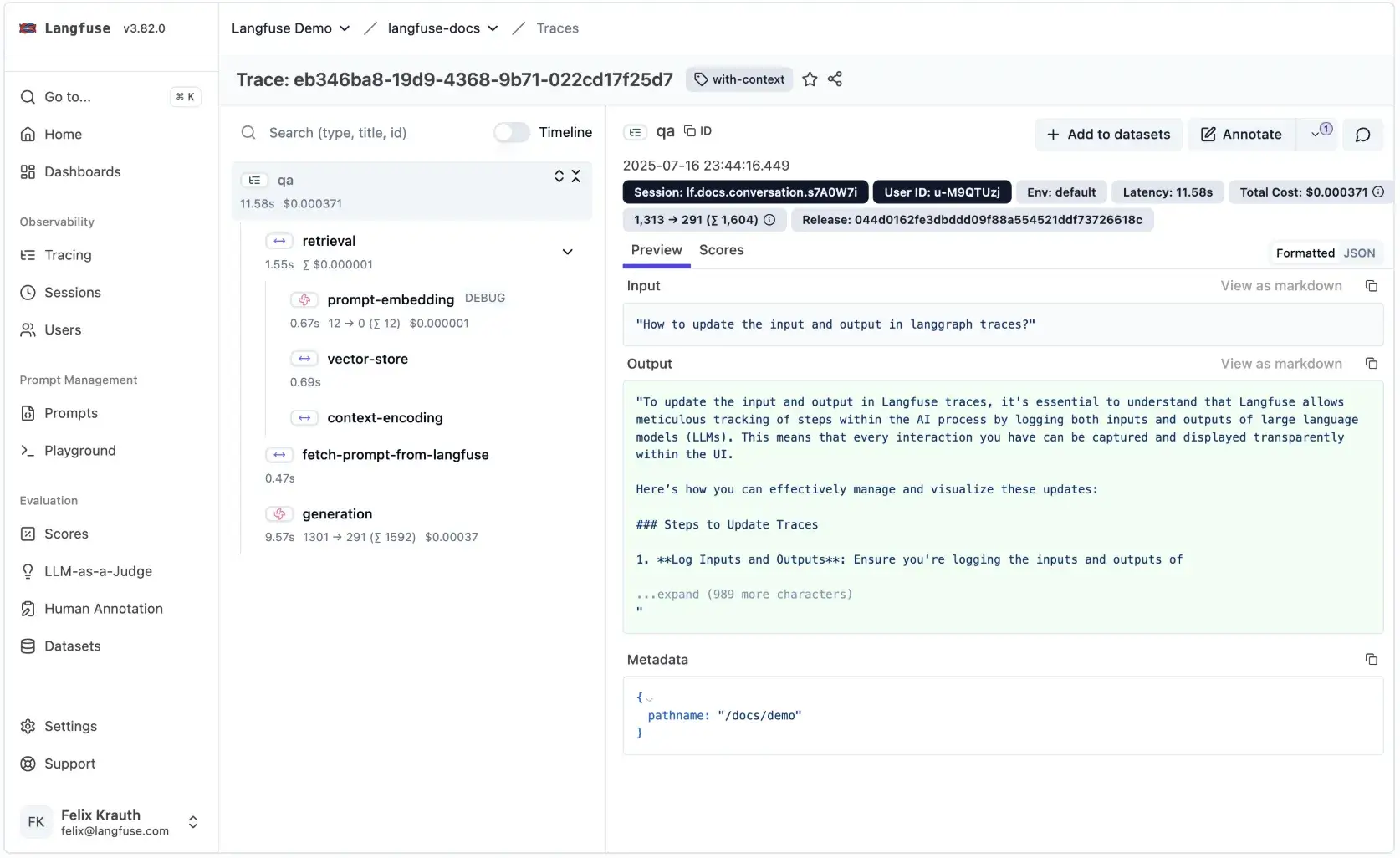
Langfuse captures traces as a collection of ‘observations’. Observations are categorized into specific types:
- A
Spanrepresents a unit of work (like a function call) - A
Generationis a specialized span for an LLM call with metadata such as token usage, cost, and model parameters. - An
Eventcaptures a single point-in-time log.
The result is a full trace timeline that clearly visualizes the path from user input to final output.
You can either use automatic callbacks or manually log spans with langfuse.start_span(). The UI then presents these as expandable, hierarchical traces showing parent-child relationships between agents, tools, and LLM calls.
Because Langfuse natively speaks OpenTelemetry, it can group distributed traces across services, making it suitable for production-scale, multi-component AI systems. Sessions in Langfuse are a special way to group these observations across traces together and see a simple session replay of the entire interaction.
Phoenix
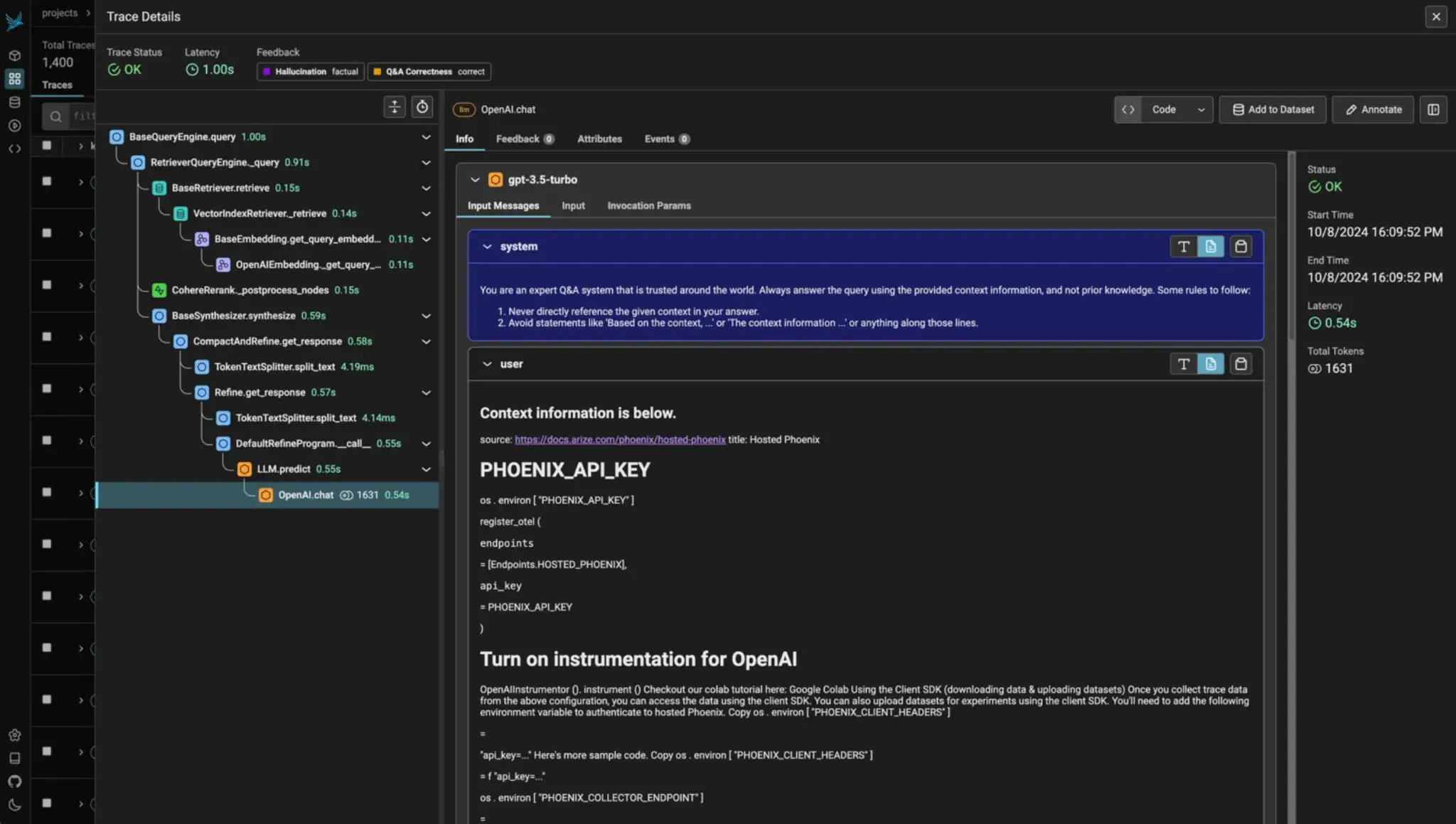
Phoenix also provides hierarchical tracing, but its approach is more turnkey. Once initialized with a single register(auto_instrument=True) call, it automatically captures LangChain, LlamaIndex, or OpenAI API activity as hierarchical spans and events in a trace.
Its lightweight UI and tracing views often include visual representations of agent execution paths and allow you to inspect the hierarchical flow of decisions within a request.
Phoenix also adds advanced analytics: clustering similar traces, detecting anomalies, and displaying retrieval relevancy in RAG pipelines, all powered by Arize’s ML observability backbone.
A notable difference is ease of setup. Phoenix runs locally or in Docker, supports live streaming of trace logs, and integrates natively with OpenInference for auto-instrumentation. It’s ideal for fast debugging, quick experiments, or local observability before moving into full production monitoring.
🏆 Winner: Langfuse. While both Langfuse and Phoenix support rich hierarchical tracing of LLM workflows, Langfuse’s mature, OpenTelemetry-native design and cross-language SDKs give it an edge in flexibility for complex use-cases.
Phoenix’s one-line auto-tracing is fantastic for quick instrumenting, and its visualizations are powerful (especially for RAG).
Feature 2. OpenTelemetry
OpenTelemetry (OTel) defines a standardized, vendor-neutral framework for instrumentation, offering maximum portability for observability data. Both platforms recognize the necessity of OTel compatibility, but they approach its implementation differently.
Langfuse
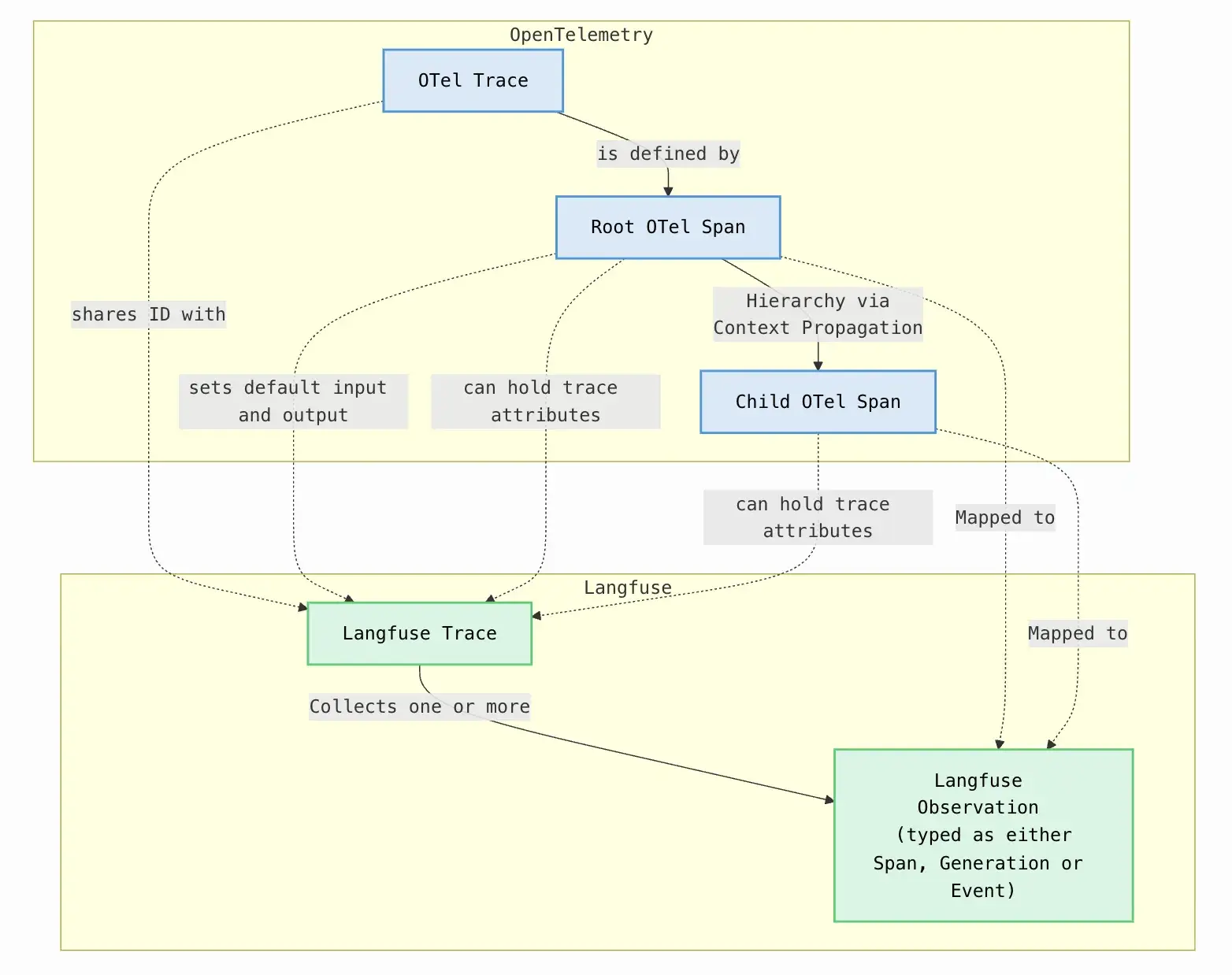
Langfuse is fundamentally built upon OTel principles. Its SDKs for Python, TypeScript, and Java automatically capture spans and send them to the Langfuse backend through an OTLP endpoint. If you already use OpenTelemetry, you can connect existing traces to Langfuse with minimal configuration.
This architecture makes Langfuse easy to plug into existing observability stacks and unify tracing across LLM, API, and backend systems.
Because OTel is the backbone, developers can instrument workflows however they prefer via Langfuse’s built-in SDK, LangChain callbacks, or custom OTel tracers. It’s flexible, transparent, and scales cleanly as your LLM pipelines grow in complexity.
In short, Langfuse treats observability as part of your engineering stack. Ideal for teams that need deep control, cross-language integration, and enterprise-grade tracing alignment.
Phoenix
Phoenix also runs on OpenTelemetry, but its approach emphasizes automation. With one line of setup, it auto-instruments LangChain, LlamaIndex, Hugging Face, and other supported frameworks.
from phoenix.otel import register
tracer_provider = register(
project_name="default", # sets a project name for spans
batch=True, # uses a batch span processor
auto_instrument=True, # uses all installed OpenInference instrumentors
)Although it’s primarily Python-centric, Phoenix simplifies complex OTel setups with smart defaults and decorators for custom code paths. It runs a built-in collector by default but can also export spans to any OTLP-compatible endpoint, keeping it interoperable with existing observability stacks.
This approach makes Phoenix especially appealing for teams seeking rapid tracing adoption without needing to master OpenTelemetry internals.
🏆 Winner: Both tools are deeply OTel-compliant, but Phoenix wins on ease of use. Its OpenInference layer and auto-instrumentation drastically reduce setup time while preserving full OTel interoperability. Langfuse offers broader flexibility and multi-language reach, yet Phoenix’s frictionless developer experience makes it the faster choice for most LLM pipelines.
Feature 3. Multi-agent Functionality
Agentic systems introduce complex, non-linear execution paths that require specialized tracing visualization. Let’s see how Langfuse and Phoenix work around this.
Langfuse
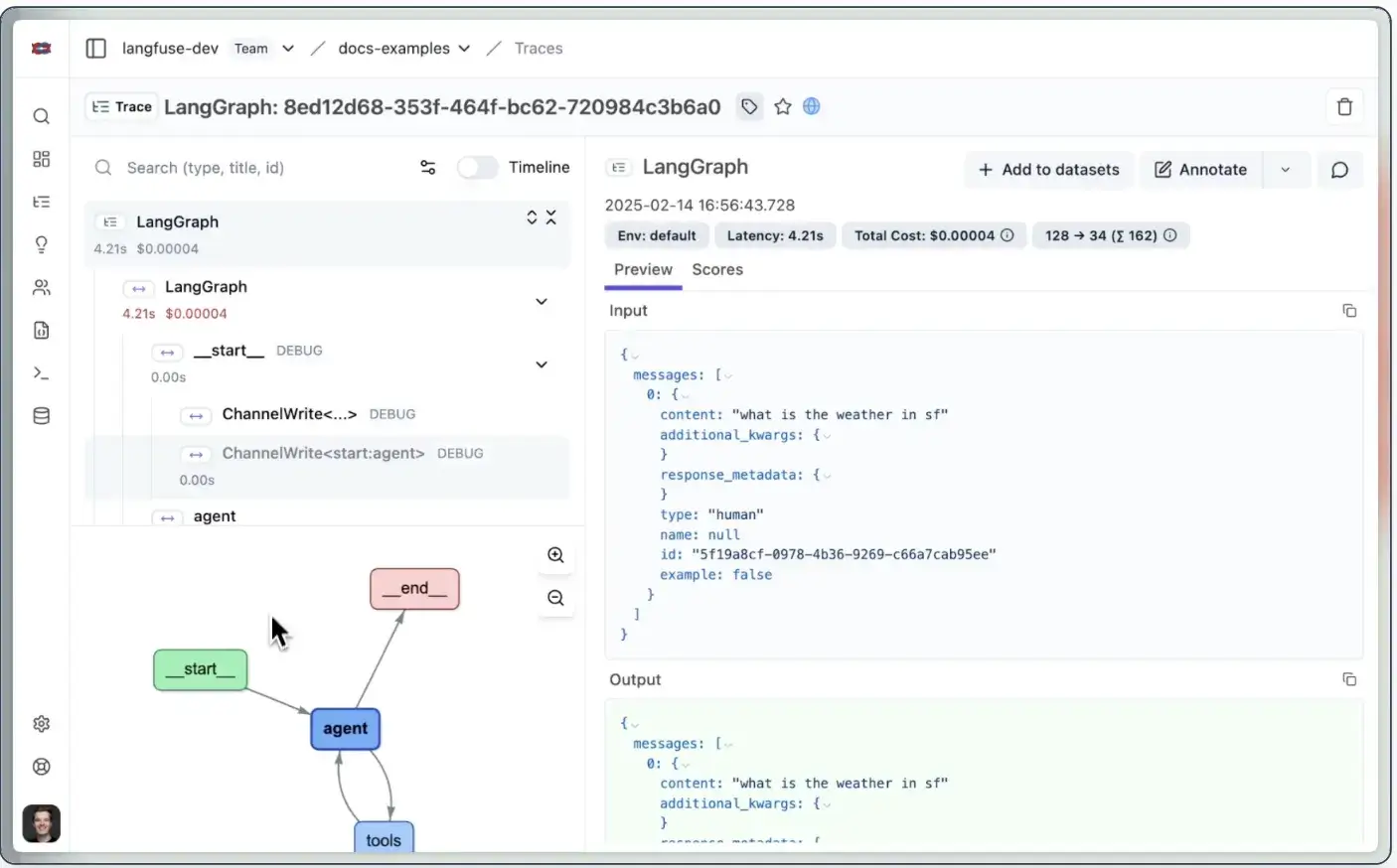
Langfuse is designed for multi-agent observability. Each agent, tool, or sub-chain is captured as a nested span.
Its Agent Graph view turns these nests into a visual DAG, showing how supervisor and worker agents interact, loop, or pass context.
Langfuse integrates with popular agent frameworks such as LangGraph, CrewAI, AutoGen, and BeeAI. You can explore agent interactions, latency, and dependencies directly in Langfuse’s UI.
This way, you can easily diagnose and debug coordination issues in complex systems. Instead of reading flat logs, you see exactly how decisions flow, how sub-agents contribute, and where reasoning breaks down in long-running or concurrent workflows.
Phoenix
Phoenix supports multi-agent tracing through OpenTelemetry and OpenInference, automatically logging each agent and tool interaction as a span.
It recognizes frameworks like LangChain, DSPy, and SmolAgents, letting teams monitor nested or sequential agent actions out of the box.
While Phoenix lacks a dedicated graph interface, its chronological trace view still provides clear visibility into multi-agent conversations.
You can expand spans to inspect prompts, responses, or tool invocations for each agent. For most linear or tree-structured workflows, this timeline-based debugging is more than sufficient.
Its simplicity makes it ideal for local or small-team use, where developers need to quickly visualize reasoning sequences without complex setup or dashboards.
🏆 Winner: Langfuse takes the lead with its agent graph visualization and extensive framework coverage. Phoenix handles agentic traces well, but Langfuse’s hierarchical model and visual DAG make it better suited for debugging branching, cyclical, or concurrent agent systems in production environments.
Feature 4. Prompt Management
Prompt management moves prompt engineering out of brittle string literals within application code and into a centralized, versioned asset repository.
Langfuse
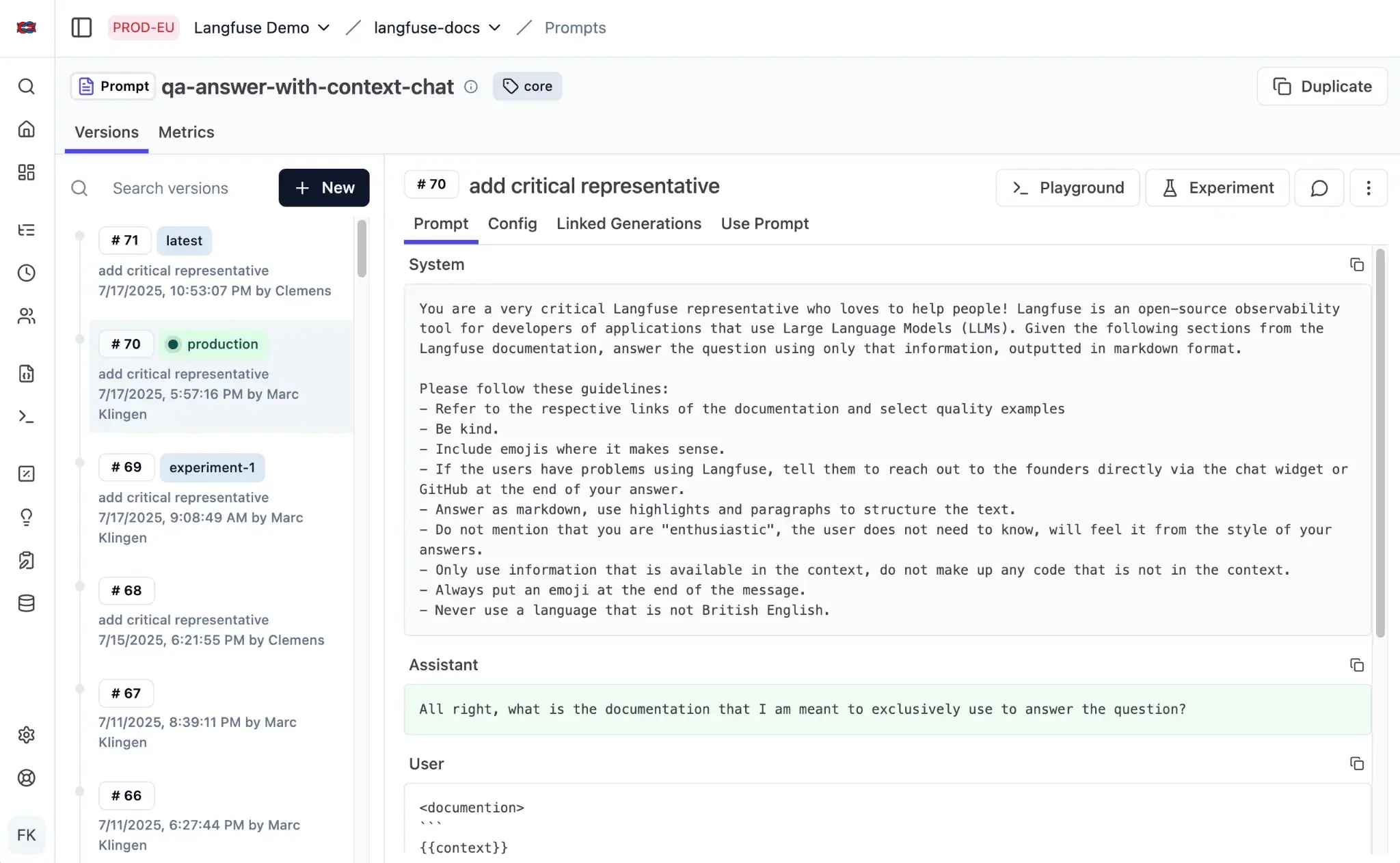
Langfuse treats prompts as versioned assets with built-in tracking and experimentation tools.
In its Prompt Management dashboard, you can store, edit, and tag prompt templates, view change history, and link specific versions to traces.
Each prompt run is recorded with its model parameters, latency, and evaluation metrics, creating a full audit trail.
You can test prompts and compare outputs directly within the Prompt Playground. These experiments feed automatically into Langfuse’s tracing layer and help you quantify improvements in quality, cost, or latency.
Besides, prompt templates can also sync with GitHub, ensuring that production and version-controlled prompts remain aligned.
Phoenix
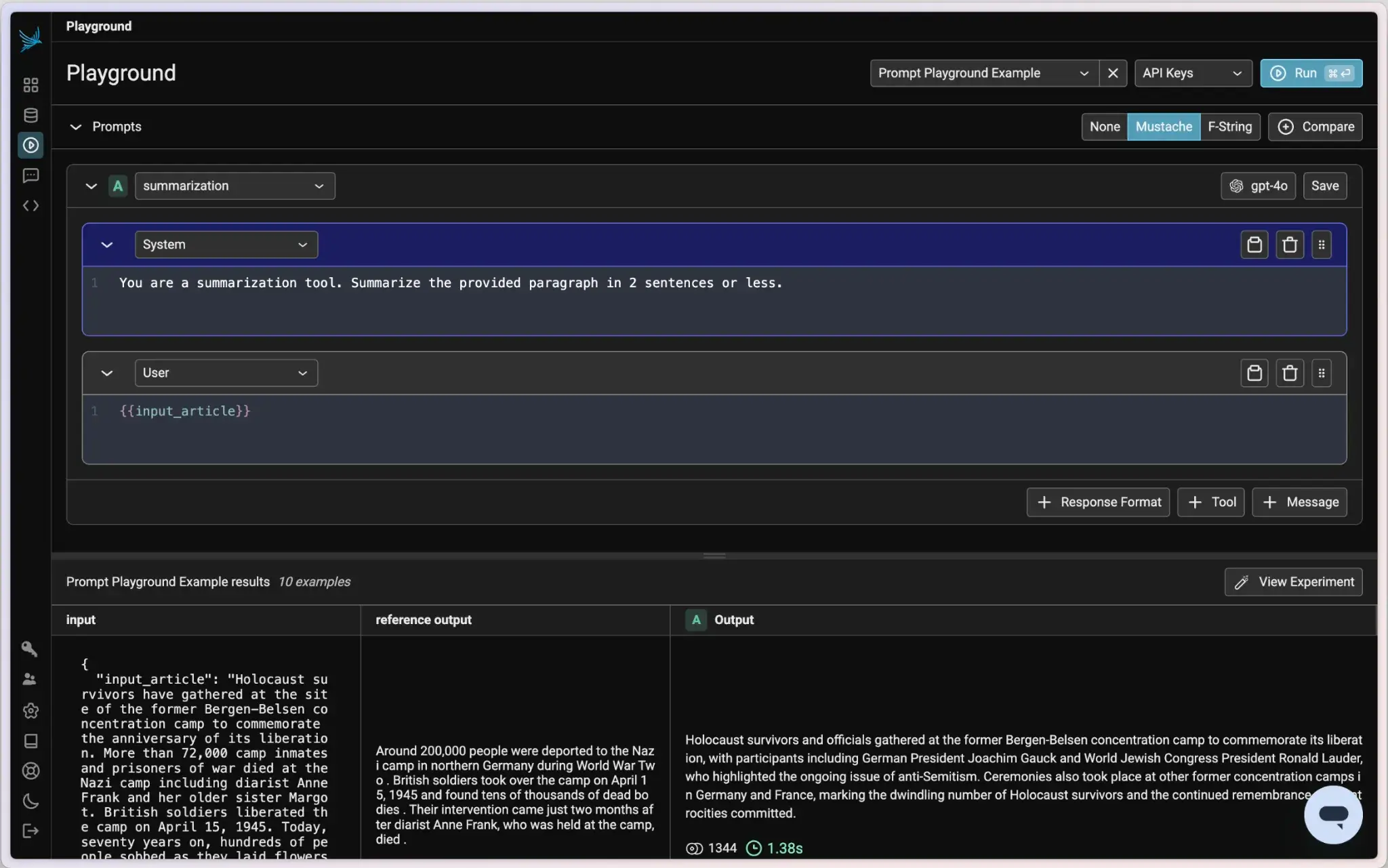
Phoenix offers an equally accessible Prompt Playground, where users can design, test, and store prompt templates. The playground supports version control, side-by-side model comparisons, and batch evaluations over datasets. You can replay past traces to refine prompts directly from observed failures.
A key difference lies in the accessibility of advanced tools within the open-source tiers. Phoenix makes its core evaluation and iteration tools available in its open-source distribution. In contrast, Langfuse restricts access to its Prompt Playground and LLM-as-a-Judge evaluation features in its self-hosted or free cloud tier.
🏆 Winner: Both tools handle prompt versioning and evaluation well, but Langfuse edges ahead with its structured version control, GitHub sync, and built-in prompt analytics. Phoenix’s playground excels for rapid prototyping, while Langfuse offers a more robust, enterprise-ready workflow for managing evolving prompt libraries at scale.
Langfuse vs Phoenix: Integration Capabilities
Modern LLM observability requires flexibility to integrate with diverse models, vector stores, and agent frameworks. The question of integration is often one of breadth versus depth within a specific ecosystem.
Langfuse
Langfuse offers one of the broadest integration ecosystems in LLM observability. Because it’s framework-agnostic and OTel-compliant, you can connect Langfuse to nearly any component in your workflow with minimal setup.
Key integrations include:
- LLM frameworks: LangChain, LlamaIndex, Haystack, LangGraph, AutoGen, DSPy, CrewAI, BeeAI
- Model APIs: OpenAI, Anthropic, Hugging Face, Vertex AI
- Analytics & feedback: Mixpanel, PostHog, or custom Metrics API
- Deployment options: Python, TypeScript, and community SDKs (Java, Go)
- Observability tools: OpenTelemetry, Jaeger, Datadog
Phoenix
Phoenix, built by Arize AI, focuses on seamless Python-first integration. Its integrations prioritize simplicity and developer speed, ideal for teams who iterate quickly in notebooks or microservices.
Key integrations include:
- LLM frameworks: LangChain, LlamaIndex, DSPy, SmolAgents, Haystack
- Libraries: Hugging Face, OpenAI SDK, Transformers
- Hosting options: Local notebook, Docker, or Arize AX Cloud
- Evaluation stack: Phoenix Evals SDK for LLM-as-a-judge and dataset testing
- Telemetry layer: Native OpenTelemetry/OTLP collector for external data export

Langfuse vs Phoenix: Pricing
From a price perspective, both platforms offer open-source cores, but the practicality of paid tiers differs by margins.
Langfuse
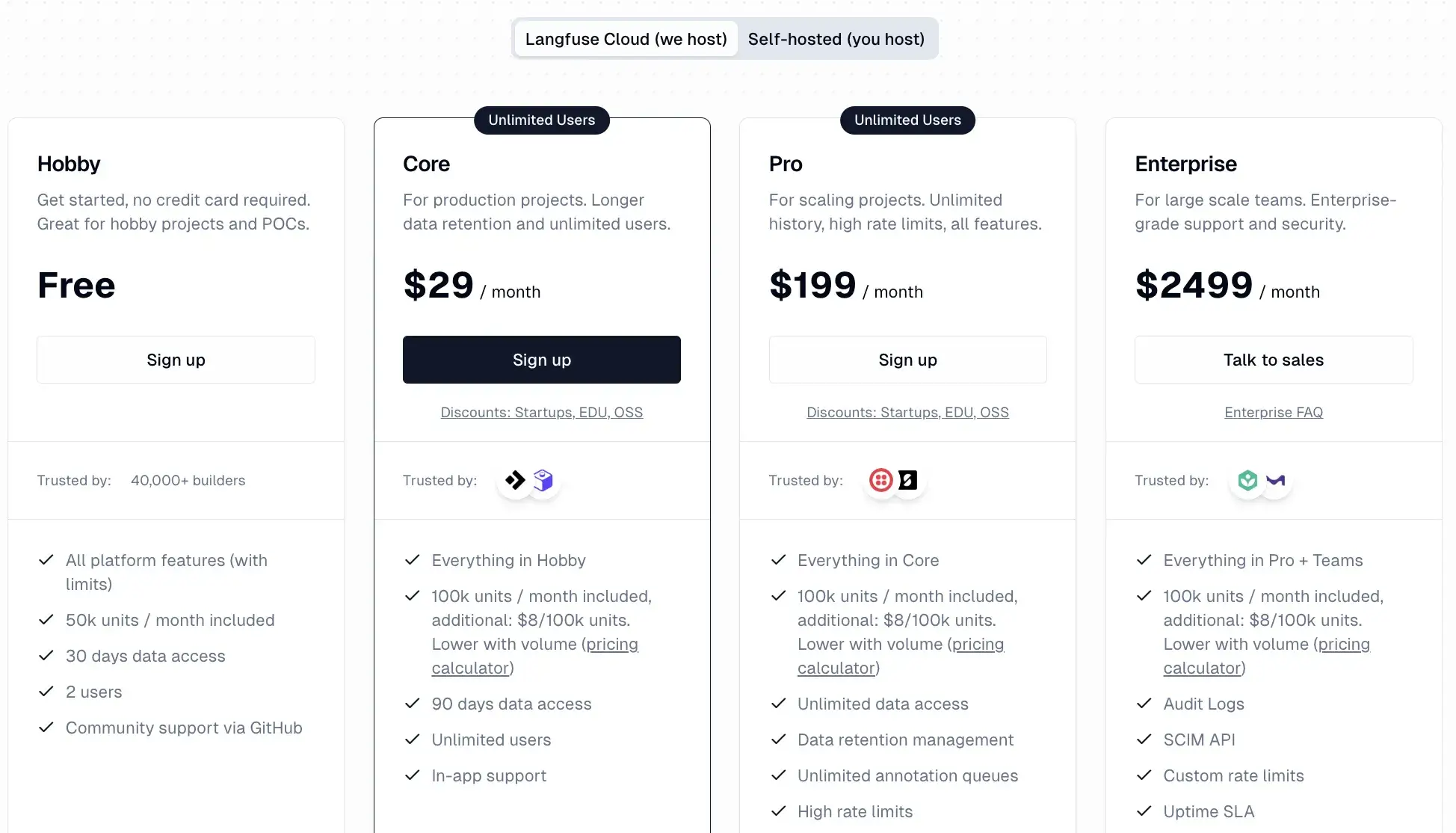
Langfuse is fully open-source, licensed under the Apache 2.0 license, and is free to self-host. For teams that prefer a managed setup, Langfuse Cloud offers tiered pricing:
- Core: $29 per month
- Pro: $199 per month
- Enterprise: $2499 per month
Phoenix
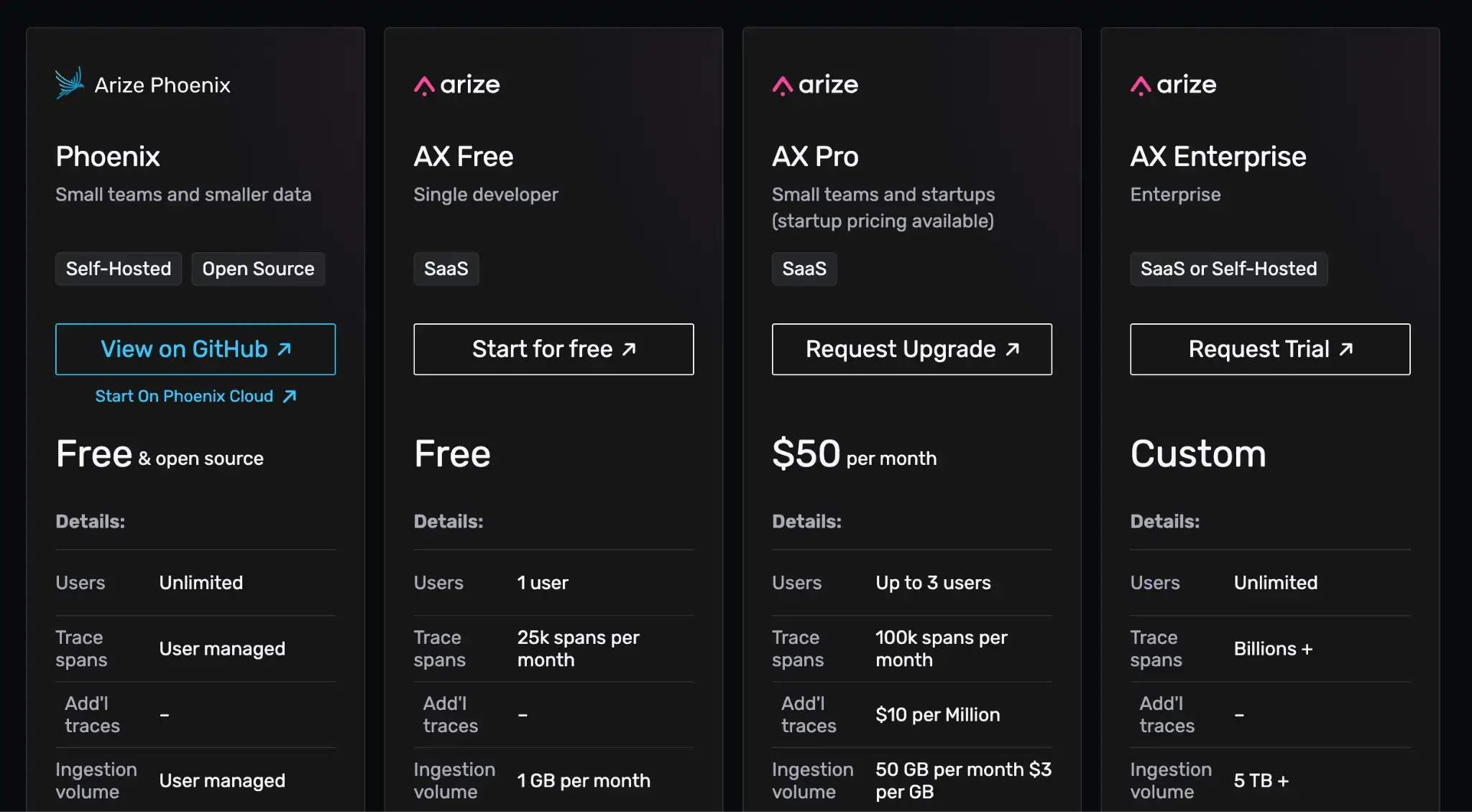
Phoenix is completely open-source and free to use with all features included. No paid version or feature gating. If you’re seeking managed hosting, ArizeAX offers three plans:
- AX Free: Free up to 1 user
- AX Pro: $50 per month
- AX Enterprise: Custom pricing
How ZenML Manages the Outer Loop when Deploying Agentic AI Workflows
An agent debugged in Langfuse or Phoenix still lacks critical production attributes. Think of version control, automated evals, and lineage tracking of RAG data. For these, you eventually need a tool that connects your observability insights back into your model lifecycle. This is where ZenML comes in.

ZenML is an MLOps + LLMOps framework that comes into play as the ‘outer loop’ around these tools. Langfuse and Phoenix focus on tracing and evaluating the behavior of your LLM agents – the inner loop of prompt → response iterations and debugging.
ZenML helps you with the outer loop: the end-to-end pipeline of developing, deploying, monitoring, and improving those agents over time.
Here’s how ZenML complements Langfuse/Phoenix and elevates your agent deployments:
1. Unified Orchestration
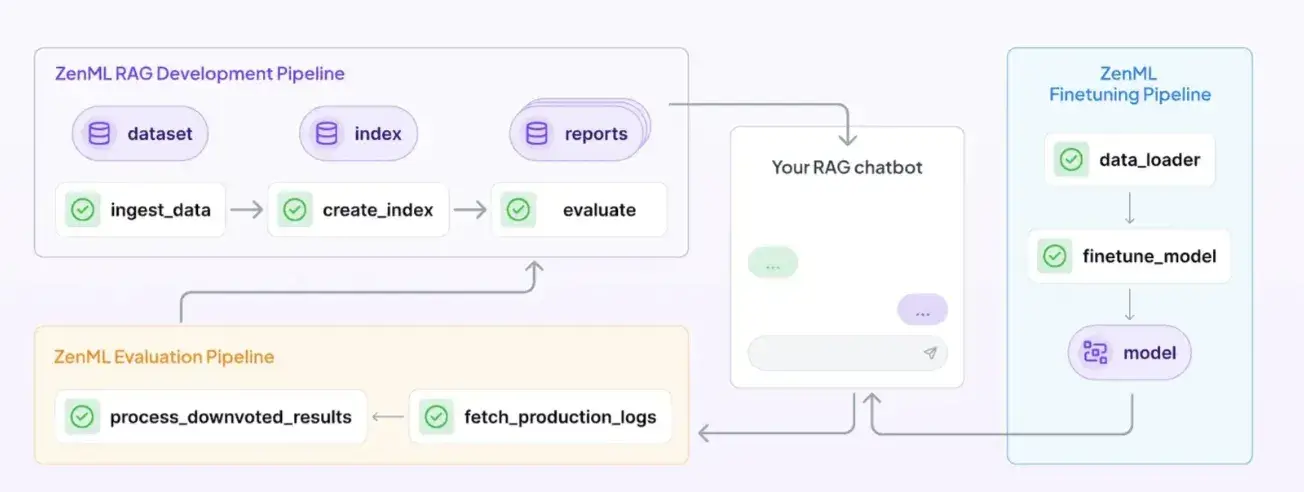
ZenML wraps your entire agent lifecycle into a single, reproducible pipeline of versioned steps.
For example, you can have a single ZenML pipeline that: prepares a prompt or context → runs the LLM agent (with Langfuse/Phoenix capturing details) → evaluates the outcome → and triggers any retraining or alerts if needed.
Every run of this pipeline is tracked by ZenML, which means you get a full lineage of what data, prompt version, and model version went into each outcome.
2. End-to-End Visibility and Lineage
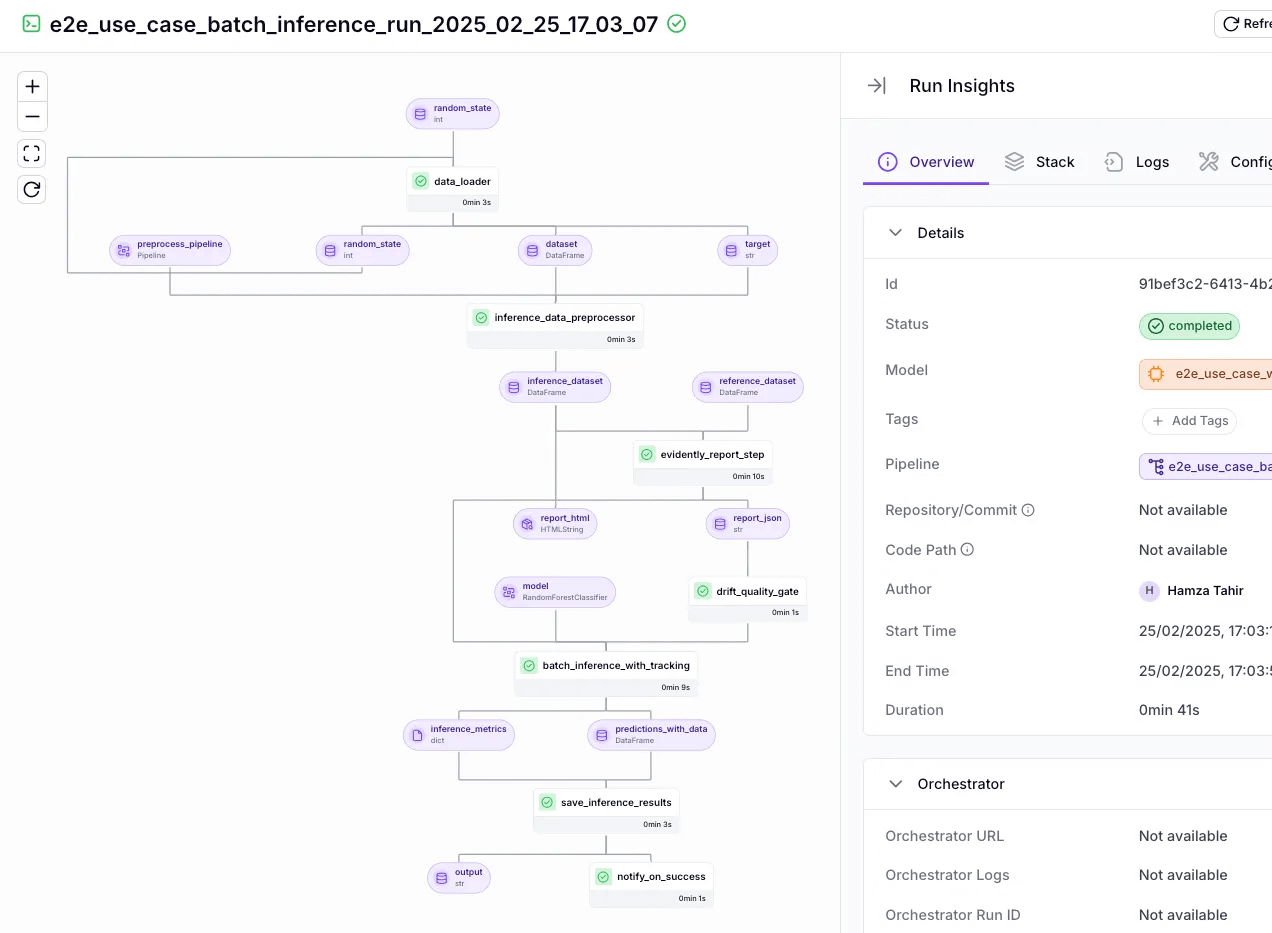
ZenML provides complete lineage tracking. It automatically tracks and versions every artifact involved in a pipeline run: prompt versions, RAG data sources, LLMs used, and the agent code.
If Langfuse or Phoenix flags a sudden performance degradation or bad output in production, ZenML can help you trace back to the exact pipeline run, the code and config used, and even link you to the Langfuse/Phoenix trace of that specific run.
Use the ZenML dashboard to visualize your pipeline changes. The dashboard shows all your past pipeline runs, compares them, and highlights where changes occurred.
3. Continuous Evaluations and Feedback Loop
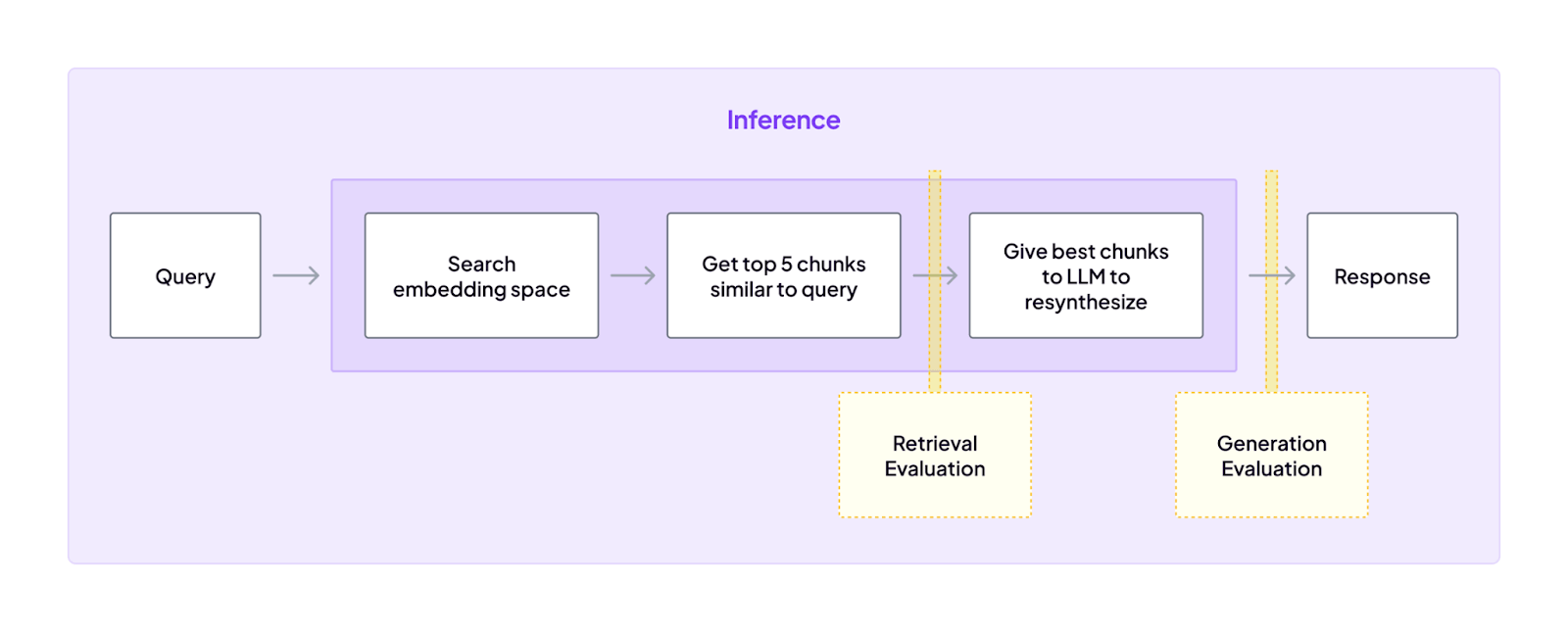
ZenML formalizes the evaluation step in the production workflow. After an agent invocation step (observed by Langfuse or Phoenix), the next step in the ZenML pipeline can automatically run evaluations, such as LLM-as-Judge scores or automated quality checks.
ZenML can then flag any failing scores, optionally branching the pipeline to terminate the run or triggering a feedback loop. This built-in governance ensures continuous quality monitoring and prevents performance degradation from reaching end users.
Langfuse or Phoenix tells the developer what the agent did during a single run. ZenML governs how that agent is built, run, versioned, and continuously improved as part of a robust, production-grade system.
Langfuse vs Phoenix: Which One’s Better for You?
Between Langfuse and Phoenix, your choice depends entirely on where your team sits in the LLMOps lifecycle.
- Choose Phoenix if: Your team uses or plans to use the broader Arize AX platform for comprehensive MLOps monitoring. Requires minimal infrastructure overhead and features like the Prompt Playground and LLM-as-a-Judge evaluators in the open-source distribution.
- Choose Langfuse if: Framework neutrality, production scale, and cost tracking are critical to your setup. You require production-grade monitoring, large-volume cost tracking, and detailed usage analytics.
Take your AI agent projects to the next level with ZenML. We have built first-class support for agentic frameworks (like CrewAI, LangGraph, and more) inside ZenML, for our users who like pushing boundaries of what AI agents can do. With ZenML, you can seamlessly integrate whichever agent framework you choose into robust, production-grade workflows.


