
Trigger.dev Pricing Guide: How Much Do You Actually Pay?
In this article, we learn about all the different pricing plans Trigger.dev offers.

Jul 2, 202610 mins
85 posts with this tag
In this article, we learn about all the different pricing plans Trigger.dev offers.

We tested 11 Camunda alternatives for agentic orchestration, from agent runtimes like Kitaru to durable execution tools like Temporal, Restate, DBOS, and Inngest.

Claude Agent SDK runs the agent loop. Kitaru adds the durable runtime around a completed invocation — checkpointed results, artifacts, replay boundaries, and waits.

LangGraph keeps graph state, threads, and interrupts. Kitaru adds the durable workflow around the graph call — replay boundaries, durable waits, and inspectable runs.

The OpenAI Agents SDK stays the harness; Kitaru adds the runtime around it — durable workflow waits, replay boundaries, and inspectable execution history.

In this Temporal pricing guide, we'll break down the platform's pricing plans and tell you whether the investment makes sense for your team.

Armin Ronacher's Absurd and Kitaru arrived at the same answers on replay semantics, ephemeral compute, and an agent-legible runtime. Here's why that matters.

What people call the agent stack is really four layers: model, harness, runtime, platform. Conflating them costs durability. The runtime layer, and one split inside it, gets the least attention.
Meet Kitaru — open source durable execution for Python agents, built by the ZenML team. Crash recovery, human-in-the-loop, and replay from any checkpoint.

Kitaru is live: open-source infrastructure platform for running Python agents in production.
A production coding agent isn't a prompt and a while loop. It's eight stages, each with different failure modes, costs, and human touchpoints. Here's the full pattern.

ML pipelines were DAGs. Agents are loops. The orchestration layer that worked for training jobs doesn't work for autonomous systems, and the industry is scrambling to catch up.

We spent five years building ML pipeline infrastructure. Then agents showed up and we realized the next problem needed a new tool — not an extension of the old one.

Tracing shows you what went wrong. But what if you could go back, fix the input, and resume from where it failed — without re-running everything?

Every durable execution engine today forces your code to be deterministic. Kitaru takes a different approach — and it matters more than you think.

In this E2B vs Daytona guide, you will learn about how these two compare across sandbox lifecycle management, output handling, pricing, and more.

AI agents fail — they timeout, hit rate limits, crash on bad API responses. Without durable execution, every failure means starting over from scratch.

In this article, you learn about the best E2B alternatives to deploy AI sandboxes. We break down 10 options covering isolation, execution, pricing, and real-world agent workloads.

Durable execution engines were built for payment flows and order processing. AI agents need something different. Here's why.


Explore the 12 best MLOps tools for building and scaling your agentic AI systems.

Compare LangSmith, MLflow, and ZenML across pipeline orchestration, reproducibility, deployment, and pricing to choose the right production AI tool.

In this article, you learn about the best PromptLayer alternatives to version, test, and monitor prompts in ML workflows.

ZenML's new Quick Wins skill for Claude Code automatically audits your ML pipelines and implements 15 best-practice improvements (from metadata logging to Model Control Plane setup) based on what's actually missing in your codebase.

In this article, we compare n8n vs Make and understand if no-code workflow automations are as efficient as code-based frameworks or not.

Discover the 11 best LLMOps platforms to build AI agents and workflows.

In this article, you learn about the best n8n alternatives for workflow automation.

Analysis of 1,200 production LLM deployments reveals six key patterns separating successful teams from those stuck in demo mode: context engineering over prompt engineering, infrastructure-based guardrails, rigorous evaluation practices, and the recognition that software engineering fundamentals—not frontier models—remain the primary predictor of success.


Explore 419 new real-world LLMOps case studies from the ZenML database, now totaling 1,182 production implementations—from multi-agent systems to RAG.

Neptune AI is terminating its standalone SaaS solution. Switch to ZenML to track ML experiments and do much more.

In this article, you learn about the best Promptfoo alternatives that help you ship better AI agents.

Discover the 9 best prompt monitoring tools for ML and AI engineering teams.

Discover the 10 best LLM monitoring tools you can use this year.

In this article, you learn about the best LangSmith alternatives you can use for full-stack observability.

In this Langfuse vs LangSmith, we conclude which observability platforms fit your LLMs stack by comparing features, integration, and pricing.

In this article, you learn about the best Datadog alternatives you can use for full-stack observability.

ZenML's new pipeline deployments feature lets you use the same pipeline syntax to run both batch ML training jobs and deploy real-time AI agents or inference APIs, with seamless local-to-cloud deployment via a unified deployer stack component.
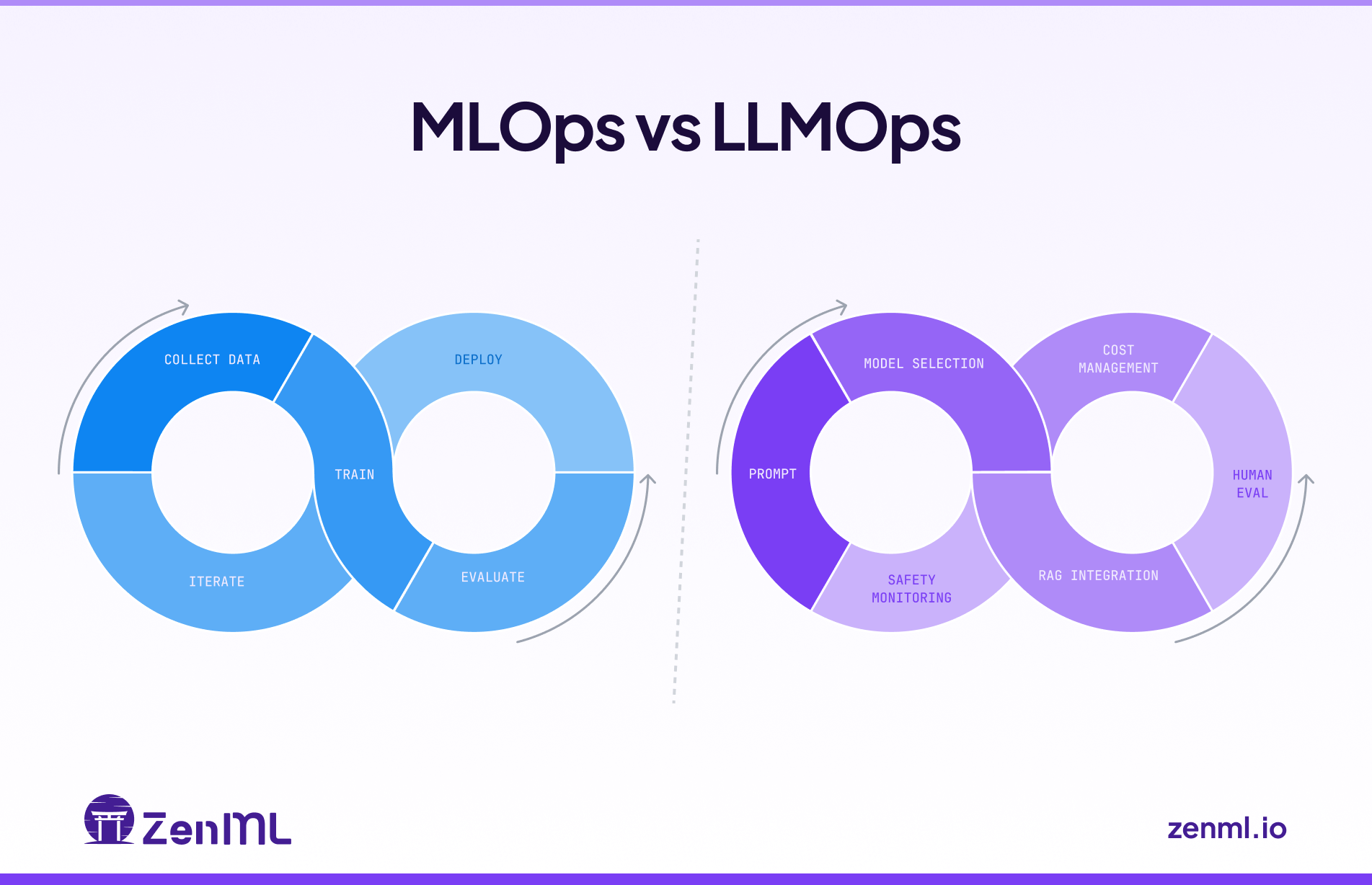
In this guide, we showcase the differences between MLOps and LLMOps and explain how to use them in tandem.

ZenML launches Pipeline Deployments, a new feature that transforms any ML pipeline or AI agent into a persistent, high-performance HTTP service with no cold starts and full observability.

In this Pydantic AI vs CrewAI, we discuss which one is better at building production-grade workflows with generative AI.

ZenML's Pipeline Deployments transform pipelines into persistent HTTP services with warm state, instant rollbacks, and full observability—unifying real-time AI agents and classical ML models under one production-ready abstraction.

In this article, you will learn about the best AutoGPT alternatives to run your AI assistants flawlessly.
In this article, you learn about the best AutoGen alternatives to build AI agents and applications.

Discover the 9 best LLM evaluation tools to test your AI models before going live.

In this Langflow vs n8n, we compare both platforms’ features, pricing, and integrations.

In this Haystack vs LlamaIndex, we explain the difference between the two and conclude which one is the best to build AI agents.

In this Google ADK vs LangGraph, we explain the difference between the two and conclude which one is the best to develop and deploy AI agents.

How to build a production-ready financial report analysis pipeline using multiple specialized AI agents with ZenML for orchestration, SmolAgents for lightweight agent implementation, and LangFuse for observability and debugging.

In this Agno vs LangGraph, we explain the difference between the two and conclude which one is the best to build multi-agent systems.

In this Pydantic AI vs LangGraph, we explain the difference between the two and conclude which one is the best to build AI agents.

Discover the best LLM observability tools currently on the market to build agentic AI workflows.

In this LlamaIndex vs LangChain, we explain the difference between the two and conclude which one is the best to build AI agents.

We're expanding ZenML beyond its original MLOps focus into the LLMOps space, recognizing the same fragmentation patterns that once plagued traditional machine learning operations. We're developing three core capabilities: native LLM components that provide unified APIs and management across providers like OpenAI and Anthropic, along with standardized prompt versioning and evaluation tools; applying established MLOps principles to agent development to bring systematic versioning, evaluation, and observability to what's currently a "build it and pray" approach; and enhancing orchestration to support both LLM framework integration and direct LLM calls within workflows. Central to our philosophy is the principle of starting simple before going autonomous, emphasizing controlled workflows over fully autonomous agents for enterprise production environments, and we're actively seeking community input through a survey to guide our development priorities, recognizing that today's infrastructure decisions will determine which organizations can successfully scale AI deployment versus remaining stuck in pilot phases.

Discover the top 7 Flowise alternatives - code and no-code that you can leverage to build and deploy efficient AI agents.

Discover the top 8 Botpress alternatives - code and no-code that you can leverage as a complete AI agent platform.

In this LlamaIndex vs CrewAI, we explain the difference between the two and conclude which one is the best to build AI agents.

Discover the top 8 Semantic Kernel alternatives that will help you build efficient AI agents.

In this CrewAI vs n8n, we explain the difference between the two and conclude which one is the best to build AI agents.
Discover the top 8 Langflow alternatives you can leverage to build and deploy AI agents.

In this Semantic Kernel vs Autogen article, we explain the differences between the two frameworks and conclude which one is best suited for building AI agents.
Discover the 7 best Agentic AI frameworks to help you build smarter AI workflows this year.


In this LlamaIndex pricing guide, we discuss the costs, features, and value LlamaIndex provides to help you decide if it’s the right investment for your business.
Compare the best CrewAI alternatives for building production AI workflows, including LangGraph, AutoGen, Google ADK, OpenAI Agents SDK, Pydantic AI, Langflow, Flowise, and LlamaIndex.

Discover the top 8 RAG tools for agentic AI you should try this year.

In this Crewai vs Autogen article, we explain the difference between the two and conclude which one is the best to build AI agents and applications.

In this Agentforce pricing guide, we discuss the costs, features, and value Agentforce provides to help you decide if it’s the right investment for your business.

Compare LangGraph vs n8n for building AI agents in 2025. Updated with LangGraph 1.0 stable release and n8n's new unlimited workflow pricing. Discover which framework fits your production AI stack.

Comprehensive analysis of why simple AI agent prototypes fail in production deployment, revealing the hidden complexities teams face when scaling from demos to enterprise-ready systems.

This Langflow vs LangGraph article explains all the differences between these AI agentic systems.

In this LangGraph vs Autogen article, we explain the difference between these platforms and when to use which one for the best results.

In this LlamaIndex vs LangGraph article, we explain the differences between these platforms and when to use each one for optimal results.

287 latest curated summaries of LLMOps use cases in industry, from tech to healthcare to finance and more. This blog also highlights some of the trends observed across the case studies.

ZenML's new DXT-packaged MCP server transforms MLOps workflows by enabling natural language conversations with ML pipelines, experiments, and infrastructure, reducing setup time from 15 minutes to 30 seconds and eliminating the need to hunt across multiple dashboards for answers.

Discover the best Kedro alternatives to build production-grade data science pipelines.

We're expanding ZenML beyond its original MLOps focus into the LLMOps space, recognizing the same fragmentation patterns that once plagued traditional machine learning operations. We're developing three core capabilities: native LLM components that provide unified APIs and management across providers like OpenAI and Anthropic, along with standardized prompt versioning and evaluation tools; applying established MLOps principles to agent development to bring systematic versioning, evaluation, and observability to what's currently a "build it and pray" approach; and enhancing orchestration to support both LLM framework integration and direct LLM calls within workflows. Central to our philosophy is the principle of starting simple before going autonomous, emphasizing controlled workflows over fully autonomous agents for enterprise production environments, and we're actively seeking community input through a survey to guide our development priorities, recognizing that today's infrastructure decisions will determine which organizations can successfully scale AI deployment versus remaining stuck in pilot phases.

Discover the top 7 LlamaIndex alternatives to build AI production agents with ease.

In this LangGraph vs CrewAI article, we explain the difference between the three platforms and educate you about using them efficiently inside ZenML.

In this LangGraph pricing guide, we discuss the costs, features, and value LangGraph provides to help you decide if it’s the right investment for your business.

Discover the top 8 LangGraph alternatives for scalable agent orchestration.

Learn how to build production-ready agentic AI workflows that combine powerful research capabilities with enterprise-grade observability, reproducibility, and cost control using ZenML's structured approach to controlled autonomy.

Discover why production teams are treating agentic workflows as MLOps evolution, not revolution—plus how ZenML achieved 200x performance improvements for enterprise ML operations. Real insights from 130+ MLOps engineers on building reliable AI systems.

A comprehensive overview of lessons learned from the world's largest database of LLMOps case studies (457 entries as of January 2025), examining how companies implement and deploy LLMs in production. Through nine thematic blog posts covering everything from RAG implementations to security concerns, this article synthesizes key patterns and anti-patterns in production GenAI deployments, offering practical insights for technical teams building LLM-powered applications.

An in-depth exploration of LLM agents in production environments, covering key architectures, practical challenges, and best practices. Drawing from real-world case studies in the LLMOps Database, this article examines the current state of AI agent deployment, infrastructure requirements, and critical considerations for organizations looking to implement these systems safely and effectively.

