

On this page
PromptLayer has gained traction as a prompt management and evaluation tool for LLM applications, but it isn’t the perfect fit for every team.
It relies on a cloud control plane and has data storage policies that can pose challenges for organizations with strict requirements.
Fortunately, there’s a growing ecosystem of PromptLayer alternatives that offer prompt versioning, testing, and monitoring, often with better flexibility in deployment and deeper integration with MLOps workflows.
In this article, we review 10 of the best PromptLayer alternatives, explaining why you might need one and what to consider when evaluating these frameworks.
PromptLayer Alternatives: Quick Overview
- Why look for alternatives? PromptLayer typically sits in your runtime path via an SDK ‘wrapper’ around your LLM client. If you use its Prompt Registry, your app may fetch prompt templates from PromptLayer at request time and then log prompts/outputs back to PromptLayer, which can add a control-plane dependency and some latency.
- Who should care? ML engineers and Python developers deploying LLM-driven applications in production – especially those at enterprises, in regulated industries, or with existing MLOps stacks.
- What to expect? A breakdown of 10 alternatives to PromptLayer evaluated on deployment flexibility (self-hosted vs. SaaS), evaluation depth (LLM-as-a-judge, unit tests), and integration with the broader ML lifecycle.
The Need for a PromptLayer Alternative?
Here are three reasons why you might consider switching from PromptLayer to a different ML workflow tool:
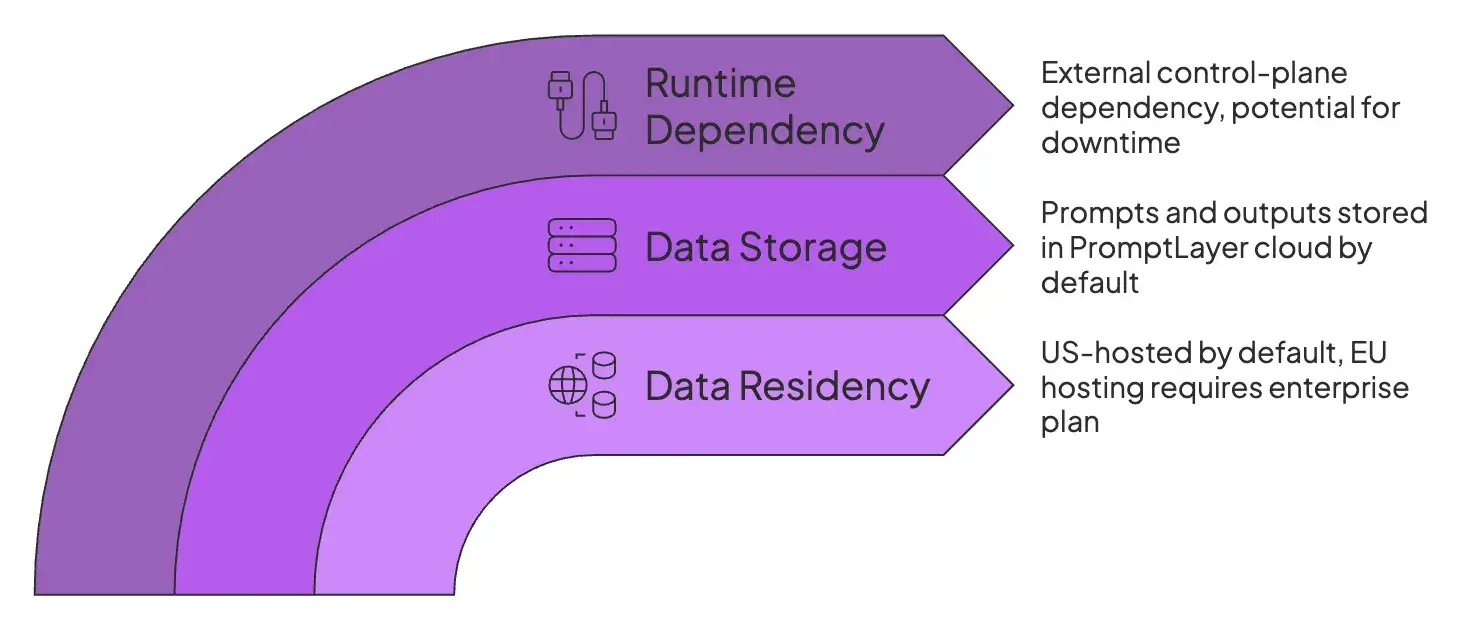
1. Data Residency is US-hosted Unless You Pay for the Enterprise Plan
For teams with strict data residency or procurement rules (for example, some public-sector tenders or regulated enterprises), a US-only hosted SaaS can be a non-starter unless the vendor offers an EU region or a self-hosted option.
Under GDPR, transferring personal data outside the EU/EEA can be lawful with the right safeguards (for example, adequacy decisions or Standard Contractual Clauses), but many organizations still prefer to keep prompts and outputs inside the EU or inside their own infrastructure to reduce compliance overhead and legal complexity.
PromptLayer’s Free, Pro, and Team tiers are cloud-hosted in the US, while EU hosting and self-hosted deployments are positioned as Enterprise options. Without an Enterprise agreement, you have limited control over where this data is processed and stored.
2. Your Prompts and Outputs are Stored in PromptLayer Cloud by Default
PromptLayer acts as middleware that logs each LLM request and response (plus metadata) to its cloud dashboard. By design, any prompt you run through it, along with the model’s output, is saved on PromptLayer’s servers.
For highly sensitive or regulated workloads, this default behavior is problematic unless you invest in the self-hosted Enterprise edition. Always consider your data privacy requirements: if you have a lot of red tape around your data and don’t want it to leave your infrastructure, PromptLayer isn’t for you.
3. Runtime Dependency: Prompts are Fetched at Request Time Unless You Build Caching
PromptLayer’s standard integration path, promptlayer_client.run, creates an external control-plane dependency in your application’s hot path.
If PromptLayer goes down or lags, your application suffers. While they offer webhook-based caching to mitigate this, it still requires you to own and maintain additional infrastructure.
Many teams prefer alternatives where prompts live in the repo and deploy with the code to avoid this network risk.
Evaluation Criteria
When vetting PromptLayer alternatives, we focused on the following criteria:
- Deployment model and control-plane risk: Can you run the tool fully self-hosted, in your VPC, or on-prem , and does it introduce a runtime control-plane dependency for fetching prompts or logging data? We prioritized tools with first-class support for caching or offline prompt use that eliminate hot-path dependencies.
- Data security, privacy, and compliance: We looked for granular data retention controls, specifically the ability to store only hashes or metadata while redacting raw PII. We also checked for audit logs, SSO/SAML integration, role-based access control, and the availability of EU storage or self-hosting outside the highest-tier plans.
- Evaluation depth: Beyond just logging prompts and responses, we assessed whether the tool supports rigorous testing methods like deterministic assertions, LLM-as-a-judge, and regression tests. We also looked for CI/CD integration to gate releases based on evaluation scores.
With these criteria in mind, let’s examine the best PromptLayer alternatives available today.
What are the Top Alternatives to PromptLayer
Before we dive into the details, here’s a detailed comparison table for the best PromptLayer alternatives:
| PromptLayer Alternatives | Best For | Key Features | Pricing |
|---|---|---|---|
| ZenML | Teams building reproducible LLM workflows with pipelines and metadata tracking | - Prompt pipeline orchestration - Prompt versioning via artifact tracking and pipeline caching - Tracing, evaluation, and CI support via plugins | - Free (Open Source) - Custom (Pro) |
| Langfuse | Teams needing full-stack prompt observability and version control | - Full tracing + metrics - Prompt versioning and evals - Works with LangChain, OpenTelemetry | - Free (Open Source) - Paid plans start at $20/mo |
| LangSmith | LangChain users focused on evals, tracing, and versioned debugging | - Side-by-side prompt evals - LangChain-native tracing - Hash-based prompt versioning | - Free (Limited) - Paid plans start at $39/user/mo |
| Helicone | Quick, proxy-based prompt logging and monitoring | - Easy integration via proxy - Caching and cost tracking - Real-time metrics dashboard | - Free (Open Source) - Paid plans start at $79/mo |
| Arize Phoenix | Evaluation-heavy teams needing open-source trace + RAG analysis | - Built-in eval templates - Embedding-based error grouping - OpenTelemetry tracing | - Free (Open Source) |
| Comet Opik | Users combining LLM experimentation with traditional ML tracking | - Safety filters + prompt scoring - CI support with tests - Built-in optimization loop | - Free (Open Source) - Paid plans start at $19/mo |
| Braintrust | Human-in-the-loop feedback and visual prompt testing | - Visual test playground - Human feedback collection - CI regression tests | - Free (Individual) - Pro: $249/month (+ usage-based charges) - Enterprise: Custom |
| W&B Weave | LLM prompt experiments with rich UI and metrics | - Token + latency logging - Eval comparison in UI - Agent behavior tracking | - Free (Personal) - Paid plans start at $60/user/mo |
| DeepEval | Python-first teams writing prompt tests with built-in metrics | - Pytest-style prompt testing - 30+ built-in eval metrics - Dashboard via Confident AI | - Free (Open Source) - Paid plans via Confident AI |
| Vellum | Workflow designers building multi-step agent systems | - Visual workflow editor - Prompt A/B testing + evals - Built-in RAG components | - Paid plans start at $25/mo |
1. ZenML
ZenML is an open-source MLOps + LLMOps framework designed to build reproducible ML and LLM workflows using code-first pipelines.
Instead of treating prompts as runtime configuration fetched from a SaaS control plane, ZenML treats prompts as first-class, versioned artifacts that live alongside your code. This makes it a strong PromptLayer alternative for teams that care about reproducibility, data privacy, and production-grade workflows.
How Does ZenML Compare to PromptLayer
PromptLayer focuses on prompt management through a cloud-hosted dashboard that sits in your application’s runtime path. ZenML takes a fundamentally different approach by embedding prompt versioning and evaluation directly into ML and LLM pipelines.
Instead of logging prompts via a proxy, ZenML treats prompts as code artifacts that are tracked, cached, and reproduced like datasets or models.
This design removes runtime dependencies and gives teams full control over data residency, something that’s critical for regulated or enterprise environments.
What’s more, ZenML integrates prompts into the broader ML lifecycle: training, evaluation, deployment, and CI, rather than isolating prompt ops as a standalone layer.
For teams already running Python-based workflows, this results in fewer moving parts, stronger guarantees around reproducibility, and easier long-term maintenance.
Features
- Prompt versioning via artifacts: Prompts are stored as immutable artifacts inside pipelines, giving you deterministic versioning without relying on an external prompt registry.
- Pipeline-based prompt eval: You can run prompts through offline datasets, batch evaluations, or CI pipelines instead of evaluating them only on live traffic.
- No runtime control-plane dependency: Prompts ship with your code and artifacts, eliminating the latency and availability risks of fetching prompts at request time.
- Rich metadata and lineage tracking: Every prompt run is linked to inputs, outputs, models, parameters, and datasets, making audits and debugging straightforward.
- Extensible evaluation with Python: Use deterministic assertions, LLM-as-a-judge, or custom Python logic for prompt testing without being locked into a UI-driven workflow.
Pricing
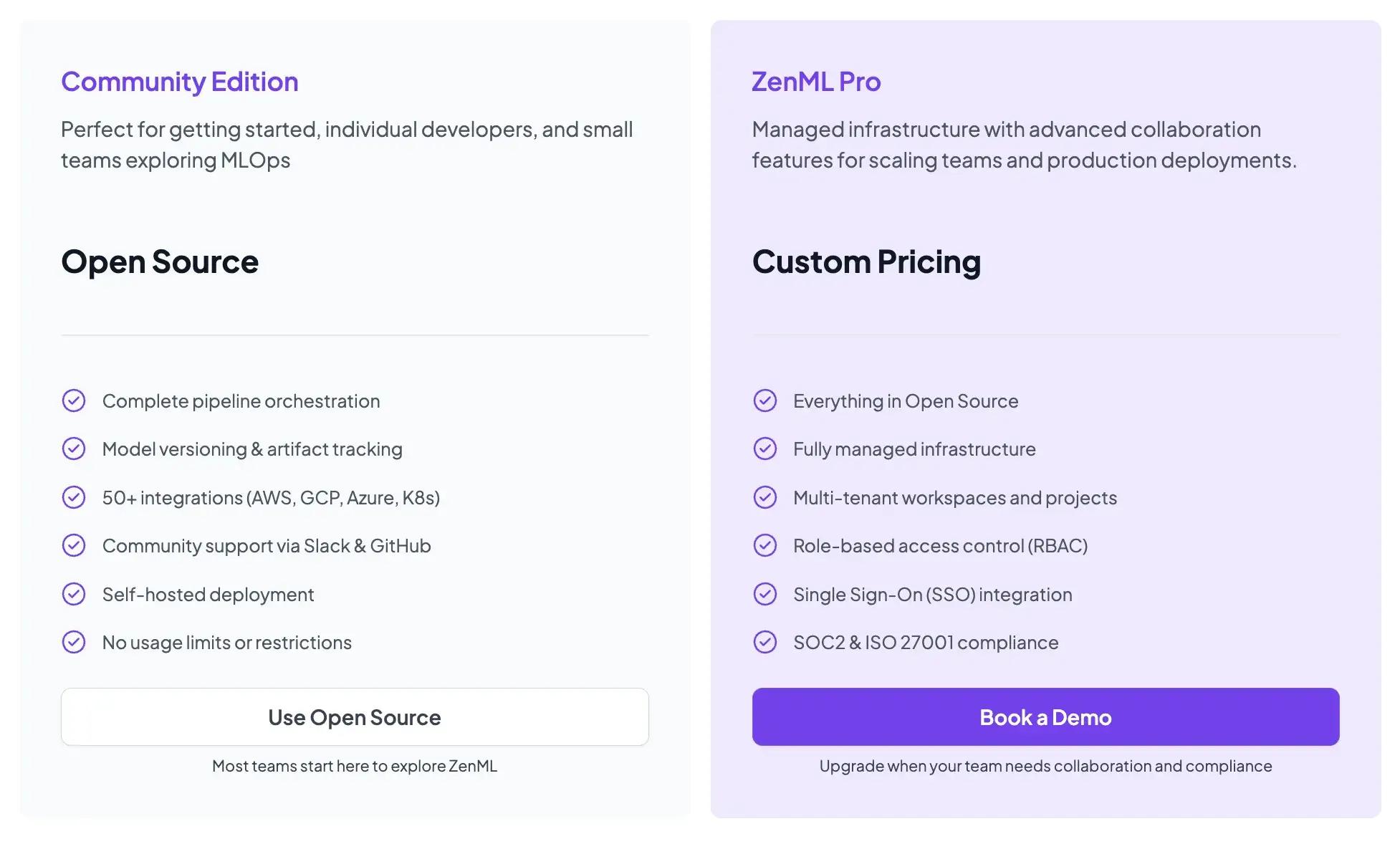
ZenML is open-source and free to start.
- Community (Free): Full open-source framework. You can run it on your own infrastructure for free.
- ZenML Pro (Custom pricing): A managed control plane that handles the dashboard, user management, and stack configurations. This removes the burden of hosting the ZenML server yourself.
Pros and Cons
ZenML’s biggest strength is its reproducibility-first design. By managing prompts through pipelines and artifacts, teams gain full lineage, auditability, and privacy without introducing a SaaS dependency in production. It fits naturally into existing ML stacks and scales well as prompt experimentation grows more complex.
Another advantage is flexibility. ZenML doesn’t dictate how you evaluate prompts; you can use simple assertions, LLM-based scoring, or complex multi-step evaluation logic, all in Python and CI-friendly workflows.
The main downside is that ZenML is less UI-driven than PromptLayer. Teams looking for a visual playground for non-technical stakeholders may find the code-first approach requires a mindset shift, especially early on.
2. Langfuse
Langfuse is an open-source observability and analytics platform designed specifically for LLM applications. It provides a detailed view of your application’s traces, allowing you to debug complex chains and agents while managing prompt versions in a centralized registry.
Features
- Run Langfuse fully on-prem using the open-source MIT-licensed version, including tracing, evaluations, and prompt management.
- Capture hierarchical traces and costs across all LLM and tool calls with built-in span tracking, token usage, and request-level billing data.
- Manage and version prompts with a registry that supports SHA-hash tracking, tagging, and side-by-side comparison in an interactive UI.
- Evaluate prompts both live and offline through batch runs, online traffic hooks, and support for LLM-as-judge, custom scripts, and human review.
- Integrate via OpenTelemetry using SDKs, ingestion APIs, or out-of-the-box support for LangChain, LlamaIndex, and other popular frameworks.
Pricing
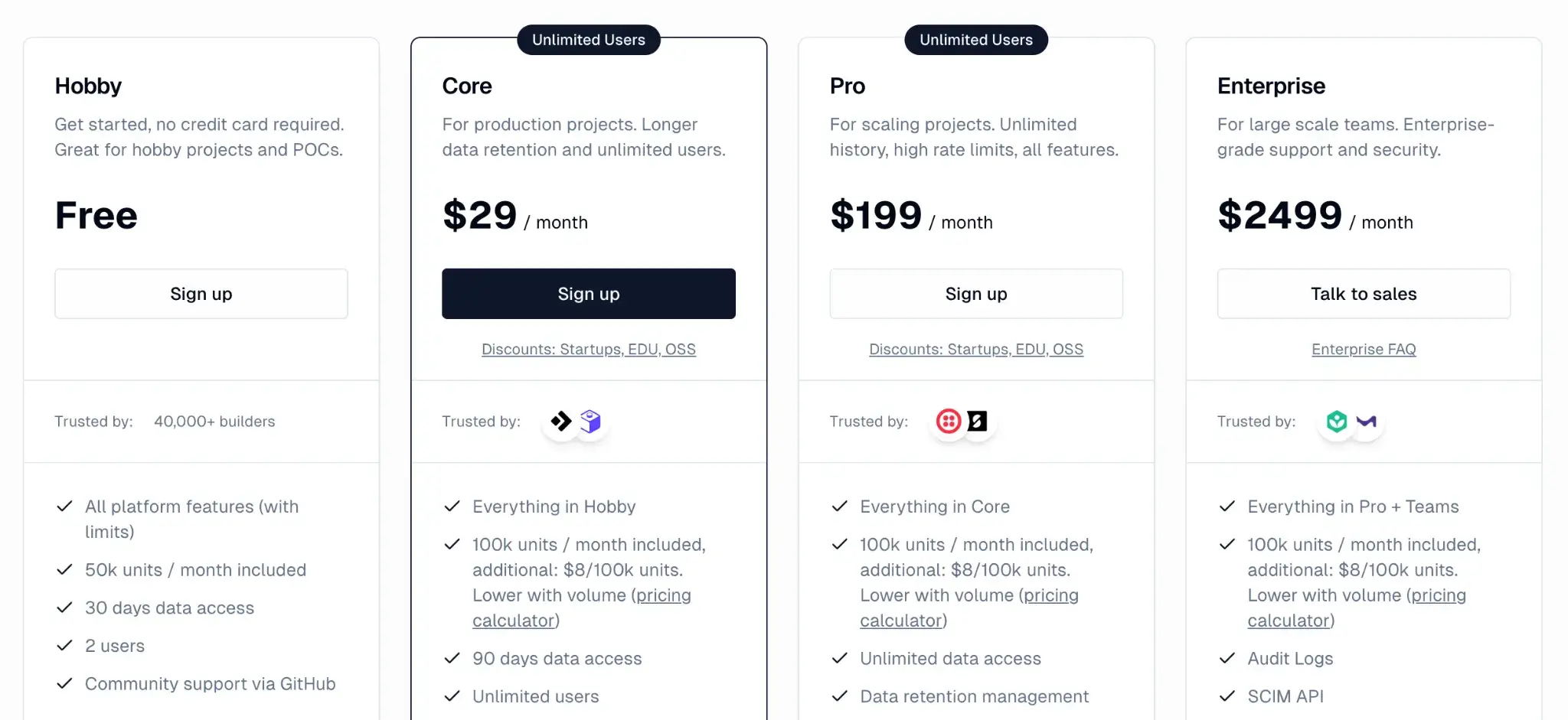
Langfuse’s open-source core is free to use, with no usage limits. It also offers managed cloud service, starting with a generous free tier for hobbyists and three paid plans:
- Core: $29 per month
- Pro: $199 per month
- Enterprise: $2499 per month
Pros and Cons
Langfuse is a favorite among developers for its clean UI and open-source nature. You can self-host it easily using Docker, which solves data privacy concerns immediately. The tracing visualization is excellent for debugging slow or expensive agent steps.
The prompt management features, while useful, still introduce a runtime dependency if you fetch prompts dynamically. Additionally, the analytics focus means it’s less of a collaboration hub for non-technical stakeholders compared to PromptLayer’s visual playground.
3. LangSmith
LangSmith is the observability and evaluation platform from the LangChain team. If you already use LangChain heavily, LangSmith can feel like an extension with one-click instrumentation and in-depth dashboards.
Features
- Visualizes complex agent execution paths with tree-based tracing that highlights inputs, outputs, and errors for every nested step.
- Monitor prompt behavior with live dashboards that track latency, errors, token usage, and cost, plus real-time alerts.
- Run structured evaluations using exact match, regex, LLM-as-a-judge, and pairwise methods on both offline datasets and live traffic.
- Experiment with prompt variations in a live playground and track versions with commit-style hashes for reproducibility.
- Integrate with LangChain directly using built-in callbacks or environment variables, with optional REST and SDK support for other apps.
Pricing
LangSmith has a free tier for individual developers and two paid plans:
- Plus: $39/seat per month
- Enterprise: Custom pricing

Pros and Cons
For LangChain users, LangSmith is the path of least resistance. It feels native and captures details specific to LangChain’s abstractions. The UI is intuitive, and having everything in one place adds to team productivity. Also, if you sign up for their enterprise deal, you get on-prem hosting if needed, which mitigates data privacy concerns.
On the downside, it is heavily optimized for the LangChain ecosystem. While you can use it without LangChain, you’ll need to manually instrument via their API, which might not capture as rich a trace structure as LangChain integrations. Compared to open-source PromptLayer alternatives, you have less customization flexibility. Plus, it introduces another layer of abstraction that can be complex for simple use cases
4. Helicone

Helicone positions itself as a specialized proxy and gateway for LLMs. You route your OpenAI/Anthropic API calls through Helicone’s proxy, and it logs all requests, responses, and usage metrics automatically.
Features
- Log prompt traffic instantly by swapping the API base URL; no need to modify application code.
- Cache repeated requests to reduce token costs and apply rate limits to prevent abuse.
- Inspect request metrics live using a real-time dashboard with filters, latency graphs, and cost breakdowns.
- Deploy on your own stack using Helicone’s open-source deployment. The proxy layer runs as a Cloudflare Worker, and the full self-host setup includes additional services (web app, databases, and storage) that you deploy and control.
- Trigger alerts on usage spikes and integrate with LangChain or third-party gateways for extended tracing.
Pricing
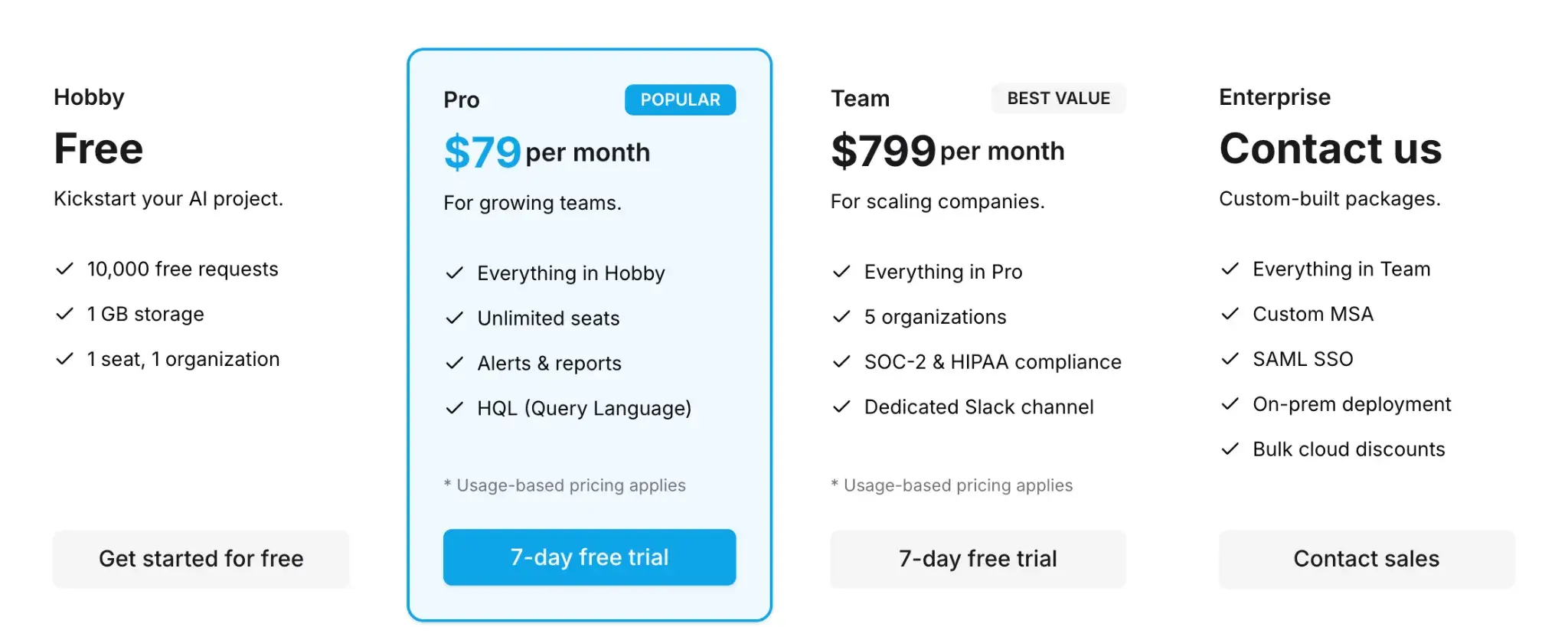
Helicone offers an open-source version and a free Hobby tier that includes 10,000 requests per month. Other than that, it offers three paid plans:
- Pro: $79 per month
- Team: $799 per month
- Enterprise: Custom pricing
Pros and Cons
Helicone is easy to integrate: just swap your API base URL to start logging, no SDK changes needed. It’s open-source and self-hostable, which helps with privacy requirements. Real-time logging, response caching, and threat detection offer clear savings and reliability benefits. Its cost transparency and lower pricing for pure logging make it appealing for teams focused on observability.
Helicone lacks built-in prompt versioning and deep evaluation workflows, so it’s not ideal for prompt experimentation or testing. The UI focuses on metrics, not prompt comparisons or dataset-driven tests. As a proxy-based tool, it introduces minor latency, which may be inconvenient for production-level workflows.
5. Arize Phoenix
Arize Phoenix is a source-available (Elastic License 2.0) LLM tracing and evaluation platform from Arize AI. It’s free to self-host and is commonly used for LLM observability, evaluation workflows, and RAG debugging. Unlike PromptLayer, Phoenix is more of a toolkit and app for evaluating and understanding LLM performance. It focuses heavily on ‘LLM Evals’ and visualizing embedding spaces.
Features
- Run Phoenix locally or self-hosted with full tracing and evaluation built on OpenTelemetry.
- Test and compare prompts live using an interactive UI for running and inspecting prompt experiments.
- Score outputs automatically with LLM-based eval templates for relevance, toxicity, and accuracy.
- Group model outputs by embeddings to identify failure clusters and recurring prompt issues.
- Connect with Arize or standalone via built-in integrations with frameworks like LlamaIndex.
Pricing
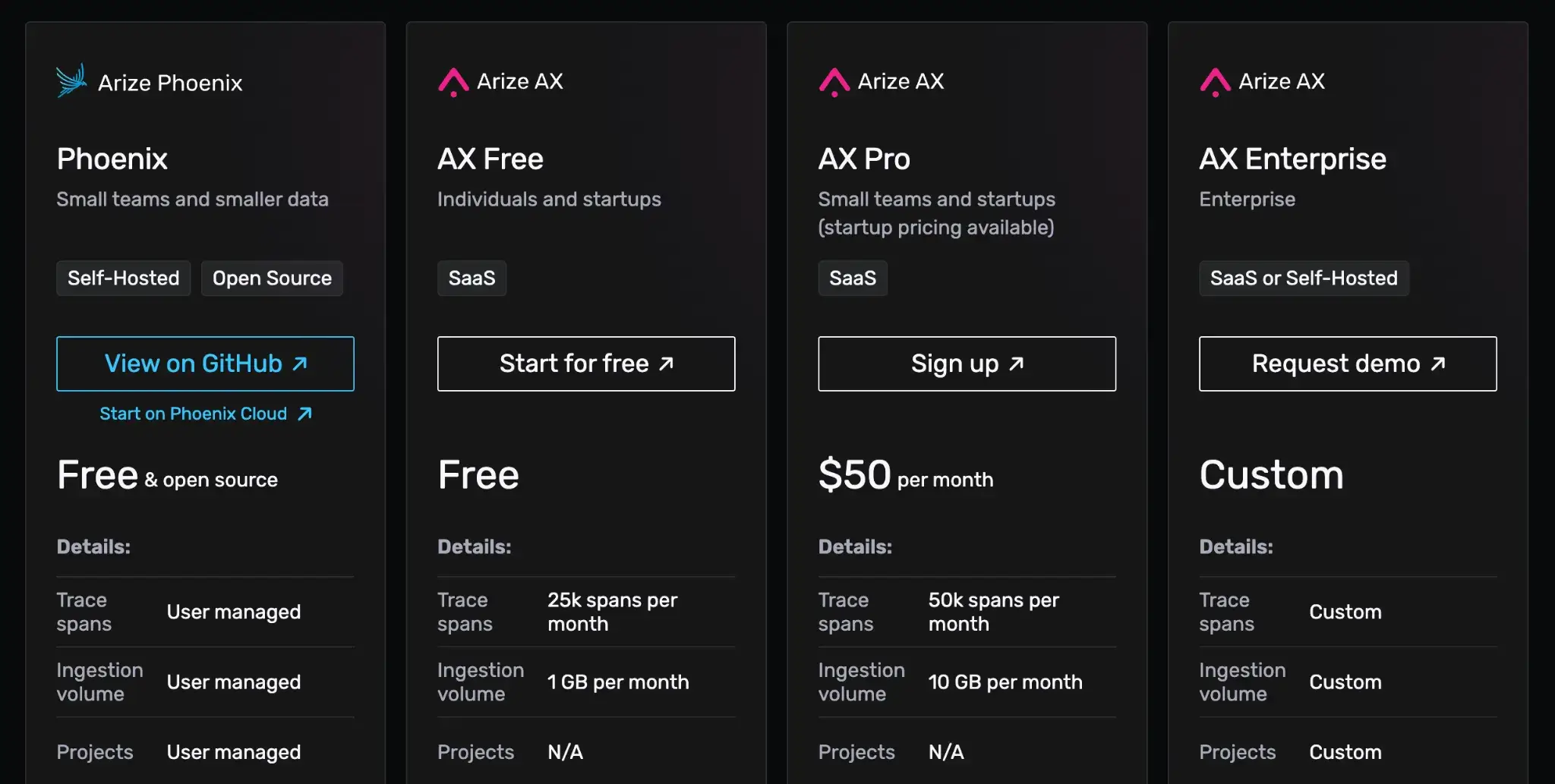
Phoenix is free and open-source for self-hosting. Arize offers a free hosted version for individuals and startups, plus two paid plans:
- AX Pro: $50 per month
- AX Enterprise: Custom pricing
Pros and Cons
Phoenix stands out for its focus on RAG and LLM quality debugging, with built-in evaluation templates and support for custom scoring. Its local-first design gives teams full control over data and deployment. Phoenix’s embedding-based clustering and visualization can help engineers debug retrieval issues that are hard to spot in raw text logs.
The main drawback is that it feels more like a data science tool than a prompt engineering hub. It lacks the collaborative, non-technical polish that PromptLayer offers. Plus, setting it up means investing time in logging and data pipelines. For teams just looking to track prompt versions or outputs, it might feel too heavy.
6. Comet Opik
Comet Opik is an evaluation and observability platform from the team behind Comet ML. Opik is like Comet’s specialized suite for LLM-powered applications. It lets you log prompts and responses, run automated evals, and even optimize prompts using algorithms.
If your emphasis is on systematic testing and optimization, Opik is an alternative to PromptLayer.
Features
- Record prompt traces and evaluations across versions using structured spans and scoring methods like LLM-as-judge or custom Python metrics.
- Iterate on prompts and agent behavior using experiments, evaluation metrics (including LLM judges), and regression tests, then promote improvements through your CI/CD workflow.
- Use built-in moderation tools to detect and block hate, PII, or off-topic outputs.
- Integrates with CI/CD pipelines to run evaluation suites automatically whenever you modify a prompt or chain.
Pricing
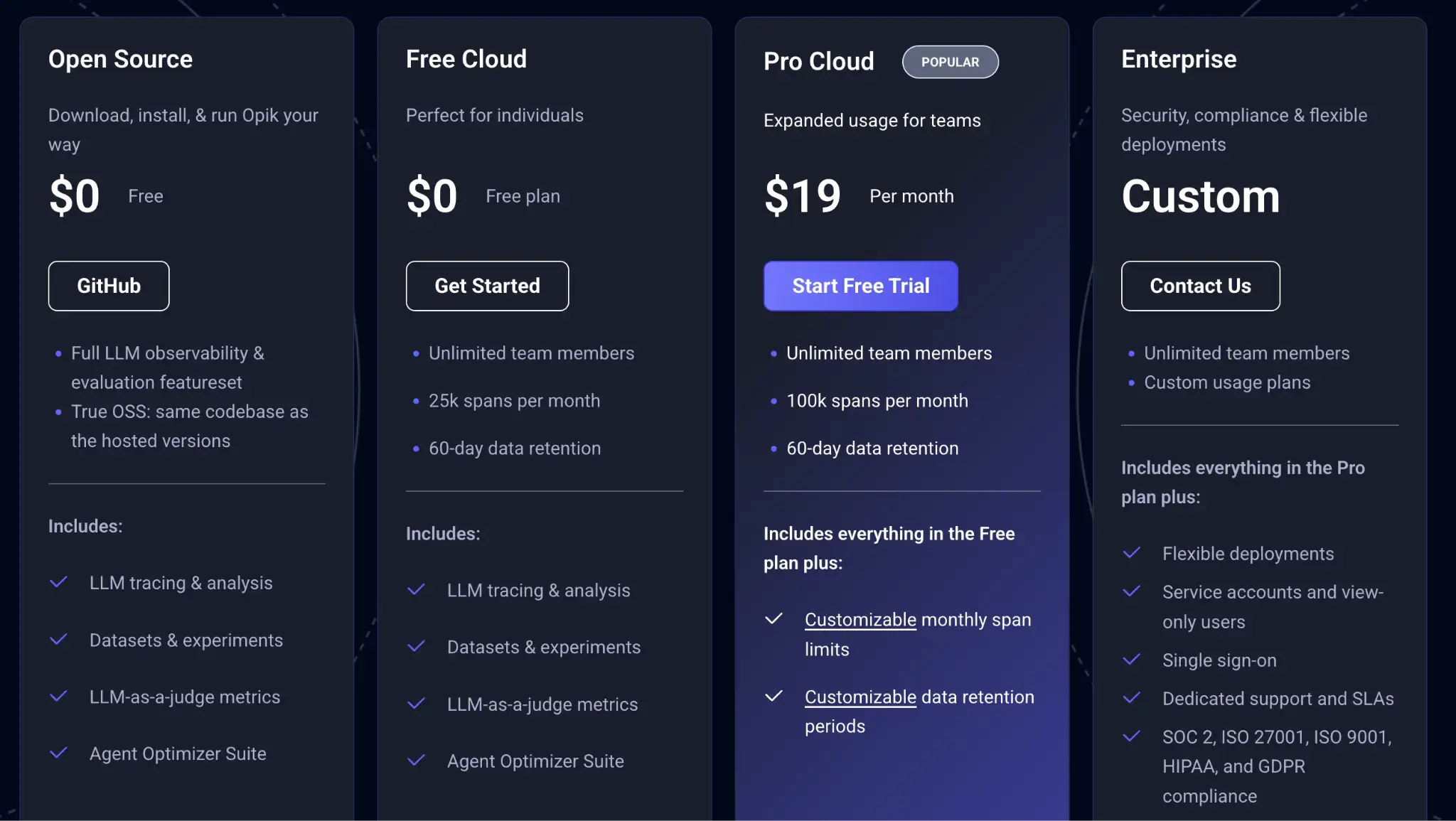
Comet Opik offers free open-source and self-hosted versions. Plus, two paid plans:
- Pro Cloud: $19 per month
- Enterprise: Custom pricing
Pros and Cons
Comet Opik Opik brings the rigor of traditional ML experimentation to LLMs. Built-in safety filters and evals make it easy to ship prompts with fewer surprises in production. It also supports optimization techniques beyond what PromptLayer offers. The pytest-style CI hooks make it easier to gate releases on quality thresholds.
However, Opik’s best features are gated behind the Comet ecosystem, which can feel heavyweight if you only need prompt tracking. The interface assumes familiarity with Comet, and onboarding takes time. While open-source, the full suite of features leans toward the hosted version. It’s not ideal for minimal or standalone setups.
7. Braintrust
Braintrust is a collaborative AI evaluation and observability platform tailored for LLM applications. It can be seen as a direct competitor to PromptLayer and LangSmith, with an emphasis on team collaboration and a polished UI for evaluation workflows.
Features
- Create prompt eval projects by pairing prompts with test inputs and scoring logic to track regressions and improvements.
- Test prompts visually using a side-by-side playground for model and prompt comparison without writing code.
- Collect human feedback from domain experts via comments, ratings, and annotations stored alongside evaluation results.
- Log production data through a proxy or SDK and turn real-world failures into test cases.
- Run evals in CI/CD and catch prompt regressions before deploys, with real-time production monitoring and alerts.
Pricing
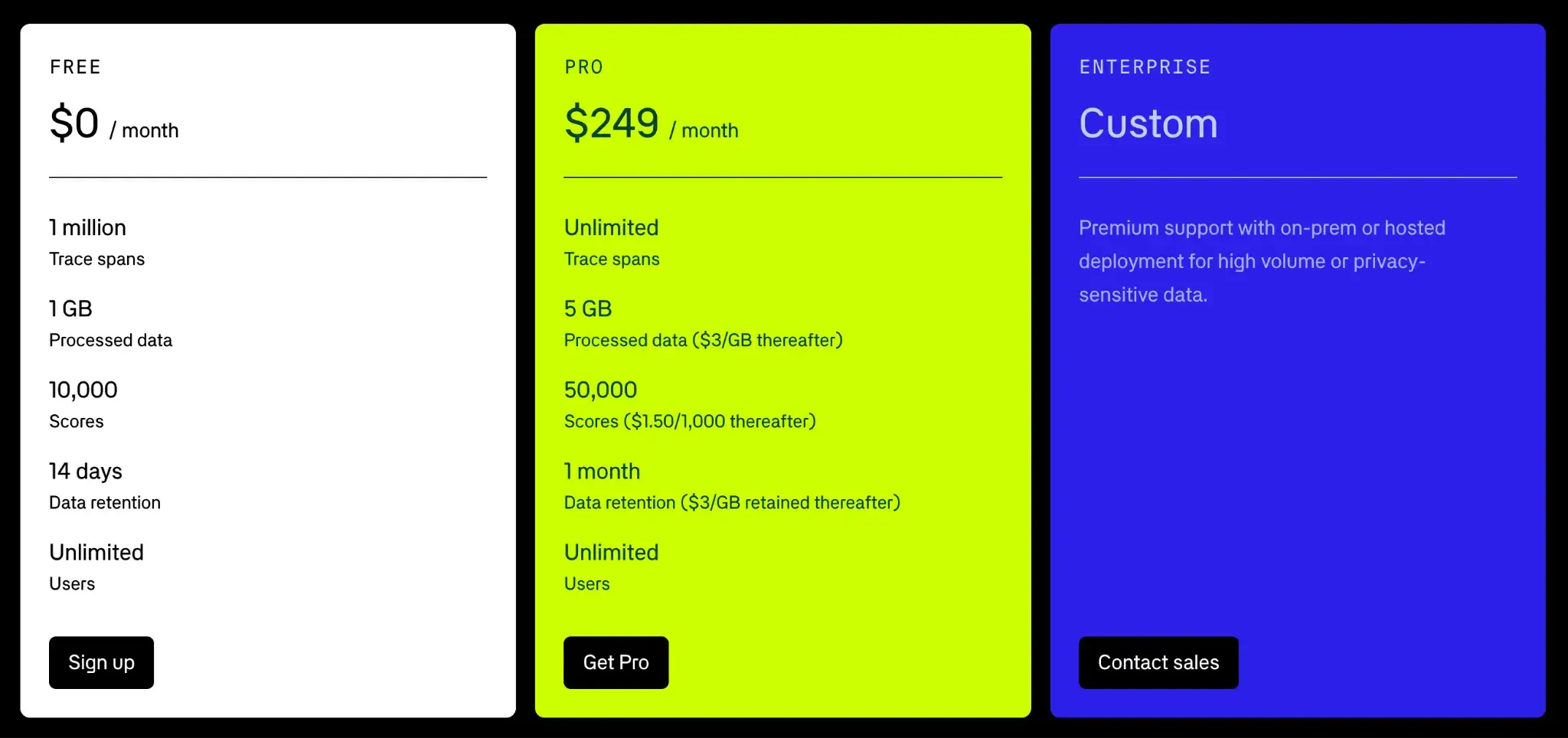
Braintrust offers a free tier for development with up to 1 million trace spans and 1GB processed data. Paid plans are usage-based, priced as follows:
- Pro: $249 per month
- Enterprise: Custom pricing
Pros and Cons
Braintrust delivers a slick, unified experience that allows you to run large regression tests in seconds, which encourages more frequent testing. The interface is praised for being intuitive for both engineers and non-engineers. Braintrust’s generous free tier and built-in proxy logging make it easy to adopt.
Being closed-source and cloud-first, Braintrust might not meet strict data control requirements unless you go Enterprise. The proxy approach, while useful, could introduce latency and potential data privacy concerns. Its Pro plan includes a base monthly fee, and you may also incur usage-based charges, which can become expensive for solo users as usage grows.
8. Weights & Biases Weave
W&B Weave is the LLM-focused toolkit from Weights & Biases, the industry standard for experiment tracking. It lets you instrument your LLM calls, evaluate responses, and compare results visually, all integrated into the W&B platform. If you’re already using W&B for ML experiments, adopting Weave can consolidate your LLM prompt monitoring into the same workflow.
Features
- Track inputs, outputs, and traces for LLM calls with a lightweight, functional API that doesn't force a specific framework on you.
- Evaluate responses with LLMs or custom Python functions and log scores alongside each output.
- Compare prompts and models visually in the W&B UI to track performance across versions or experiments.
- Build dashboards and reports to share prompt accuracy, regression results, or dataset-level trends with your team.
- Track agent behavior with multi-step traces and highlight runs that show anomalies or policy violations.
Pricing
Weave usage falls under W&B’s normal pricing. W&B has a free plan for individual projects and two paid plans:
- Pro: $60 per month
- Enterprise: Custom pricing

Pros and Cons
W&B Weave is a natural choice if you are already in the W&B ecosystem. It keeps your LLM experiments in the same place as your training runs. It’s also code-first and highly customizable: you decide what to log and how to evaluate, which can all be done in Python.
On the flip side, if you’re not using W&B already, Weave might feel like adding a heavyweight solution just for prompts. Unlike PromptLayer’s simple prompt management UI, Weave expects you to instrument code. For pure prompt ops, tools like Langfuse or Braintrust might offer more targeted features.
9. DeepEval
DeepEval is an open-source evaluation framework from Confident AI. It brings LLM testing and evaluation into one framework. If your main pain point with PromptLayer is limited evaluation capabilities or a lack of rigorous testing, DeepEval is a strong alternative to consider.
Features
- Write prompt tests in Python using simple, Pytest-style syntax with assertions or evaluation metrics.
- Apply 30+ built-in metrics to score outputs on relevance, coherence, grammar, or even GPT-based G-Eval methods.
- Visualize test results in a dashboard when paired with Confident AI, including trace logs and team collaboration.
- Run evaluations in CI/CD to block releases when prompt changes cause quality regressions.
- Extend with custom logic using the open-source core to add your own metrics, datasets, or eval workflows.
Pricing
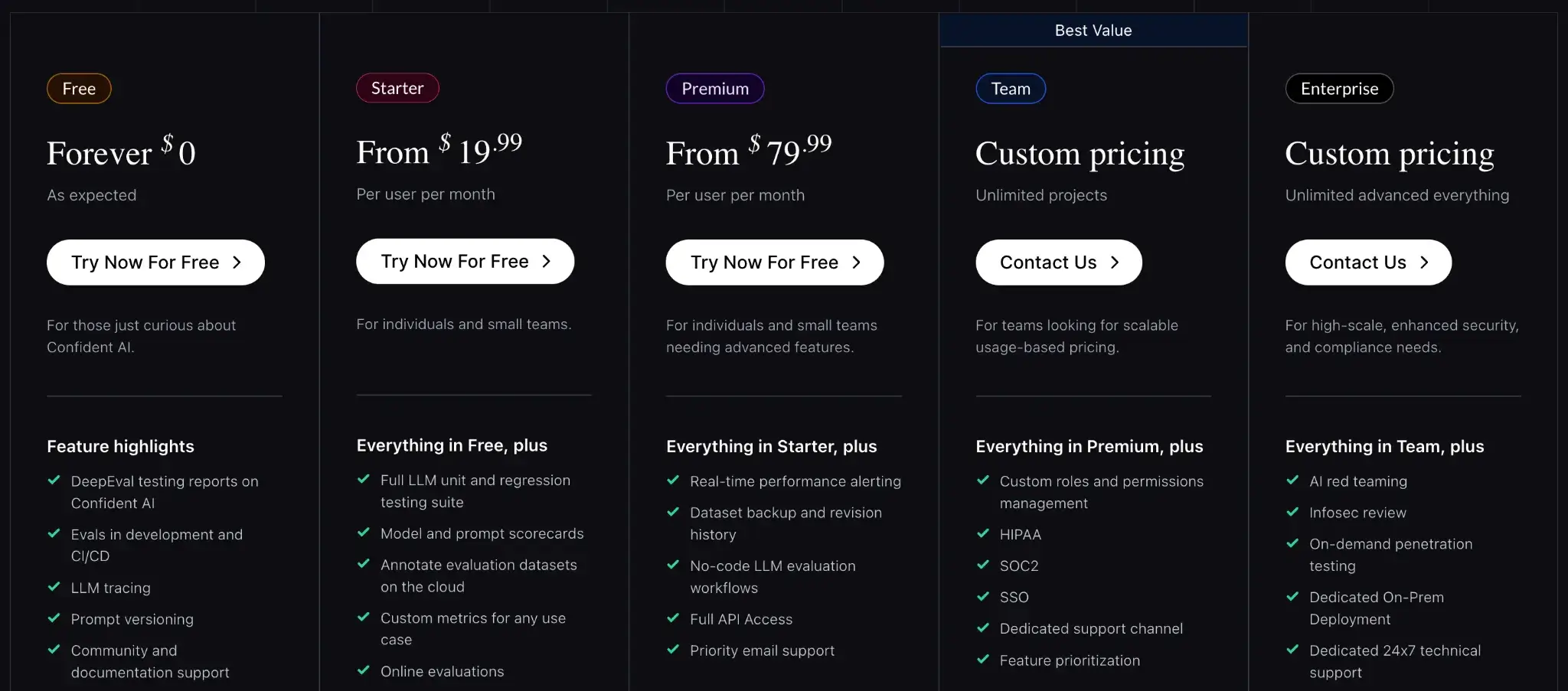
The DeepEval framework is open-source and free. Confident AI (the hosted platform) has a free tier and multiple paid plans:
- Starter: $19.99 per user per month
- Premium: $79.99 per user per month
- Team: Custom pricing
Pros and Cons
DeepEval gives developers a lightweight way to test prompts with familiar Python syntax. It supports both deterministic tests and LLM-as-judge scoring, making it flexible for different use cases. The Confident AI dashboard adds visibility for teams without forcing vendor lock-in. Its open-source core and integration with CI tools make it a good fit for code-first workflows.
Without Confident AI, visualization and collaboration features are limited. It lacks deeper trace logging or observability tools out of the box. Teams looking for live monitoring or prompt version management may need to combine it with other tools. It’s focused more on evaluation than full-stack prompt tracking.
10. Vellum
Vellum is a production-grade platform built for teams building complex LLM applications. It’s an end-to-end application builder, which includes prompt engineering, semantic search, and evaluation into a single workflow, often targeting startups and enterprises.
Features
- Design agent workflows visually using a drag-and-drop canvas that lets you chain prompts, functions, and retrieval steps.
- Manage prompt versions and tests with a built-in system for labeling, A/B testing, and bulk evaluations on datasets.
- Integrate RAG workflows directly by indexing documents and embedding search steps within prompt flows.
- Track usage and performance across prompts and agents with metrics like response time, success rate, and alerts.
- Control team access by assigning roles and sharing projects, with RBAC available on paid plans.
Pricing
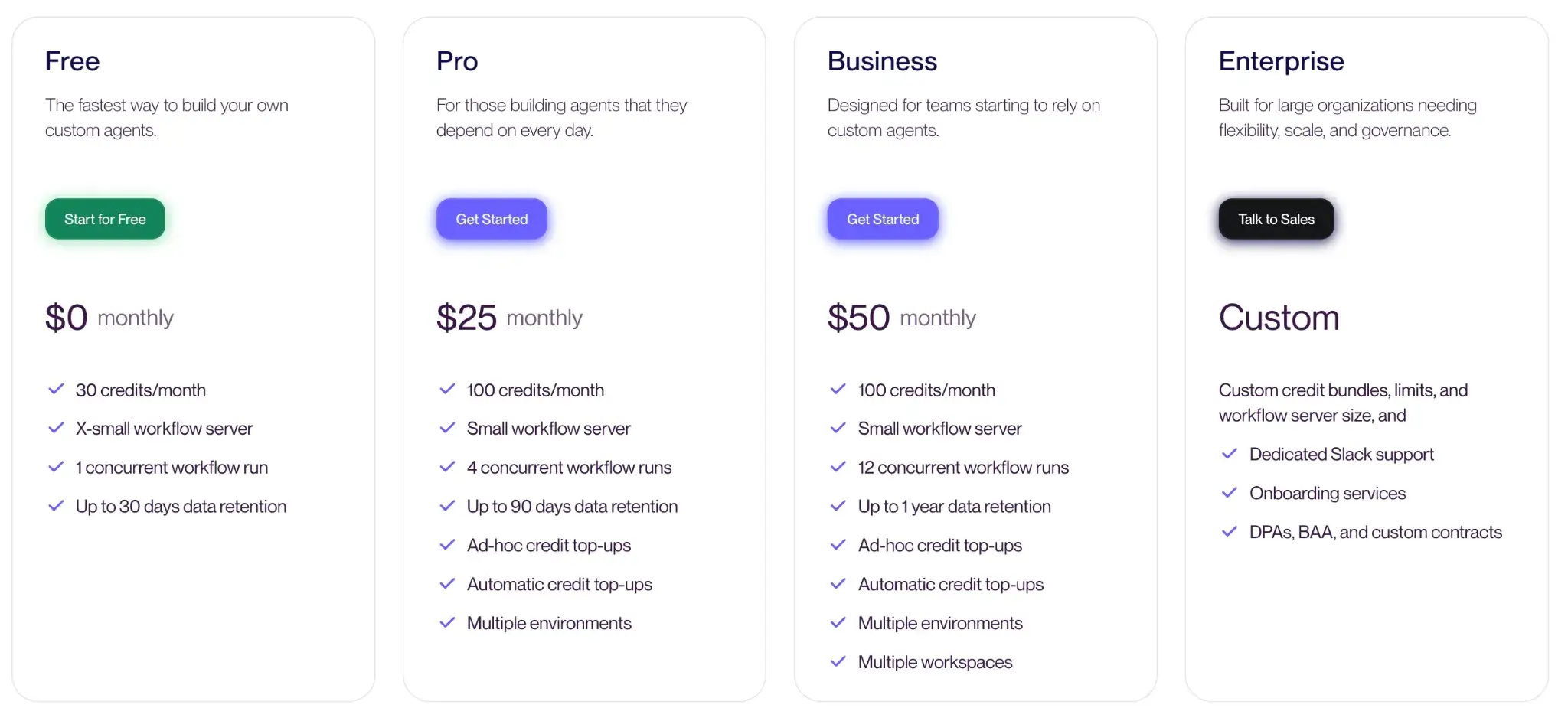
Vellum has a free plan for building bite-sized custom agents. For scale, it offers three paid plans:
- Pro: $25 per month
- Business: $50 per month
- Enterprise: Custom pricing
Pros and Cons
Vellum is one of the most polished tools on this list. It feels like a complete IDE for LLM development. The ability to deploy a prompt as an API endpoint is time-saving when decoupling prompt logic from application code.
The main barrier is cost and accessibility. Vellum is closed-source and fully cloud-hosted; there’s no self-host except possibly on expensive enterprise contracts. If you are a small team or an open-source project, Vellum is likely overkill and over budget.
The Best PromptLayer Alternatives to Version, Test, and Monitor Prompts in ML Workflows
Each of these 10 alternatives brings something unique to the table, whether it’s open-source freedom, advanced evaluation capabilities, or enterprise-grade controls. When choosing a PromptLayer alternative, prioritize what matters most to your use case:
- Choose Langfuse if you need granular observability for complex agents. It offers best-in-class tracing capabilities and allows you to self-host the entire platform, making it ideal for teams who want deep debugging tools without vendor lock-in.
- Choose Helicone if you need a lightweight gateway to control costs. It sits between your code and the LLM provider to handle caching, rate limiting, and logging with almost zero configuration changes.
- Choose ZenML if you need to treat prompts as immutable code artifacts. It allows you to version, track, and evaluate prompts within your existing ML pipelines, ensuring full reproducibility and data privacy on your own infrastructure.
📚 Relevant alternative articles to read:


