On this page
Prefect is a popular open-source workflow orchestration tool, but it isn’t a one-size-fits-all solution.
While it excels at scheduling and managing data pipelines in Python, many teams find themselves supplementing Prefect with other tools to cover its gaps in experiment tracking, artifact versioning, and cost-effective scalability.
In this article, we explore eight Prefect alternatives that can better serve ML engineers. Each alternative addresses specific limitations of Prefect, from providing integrated experiment tracking and model registry to ensuring cloud neutrality and more flexible cost models.
TL;DR
- Why Look for Alternatives: Prefect lacks native ML experiment management features – there’s no built-in experiment UI or model registry, and by default, it doesn’t version outputs persistently. ML Teams often have to pair Prefect with external tools like MLflow for tracking to fill these gaps.
- Who Should Care: MLOps engineers, ML and AI engineers, data scientists, and platform teams who need more than orchestration. If you require first-class experiment tracking, robust data/artifact version control, or more deployment freedom (on-prem, multi-cloud) than what Prefect offers, these alternatives are worth examining.
- What to Expect: The eight alternatives below span three categories – Workflow Orchestration, Artifact and Data Versioning, and Experiment Tracking and Observability – to address different shortcomings of Prefect. For each, we outline key features (particularly where they shine compared to Prefect) and list pros and cons.
The Need for a Prefect Alternative
There are three core reasons why teams often seek a Prefect alternative instead of doubling down on Prefect’s ecosystem.
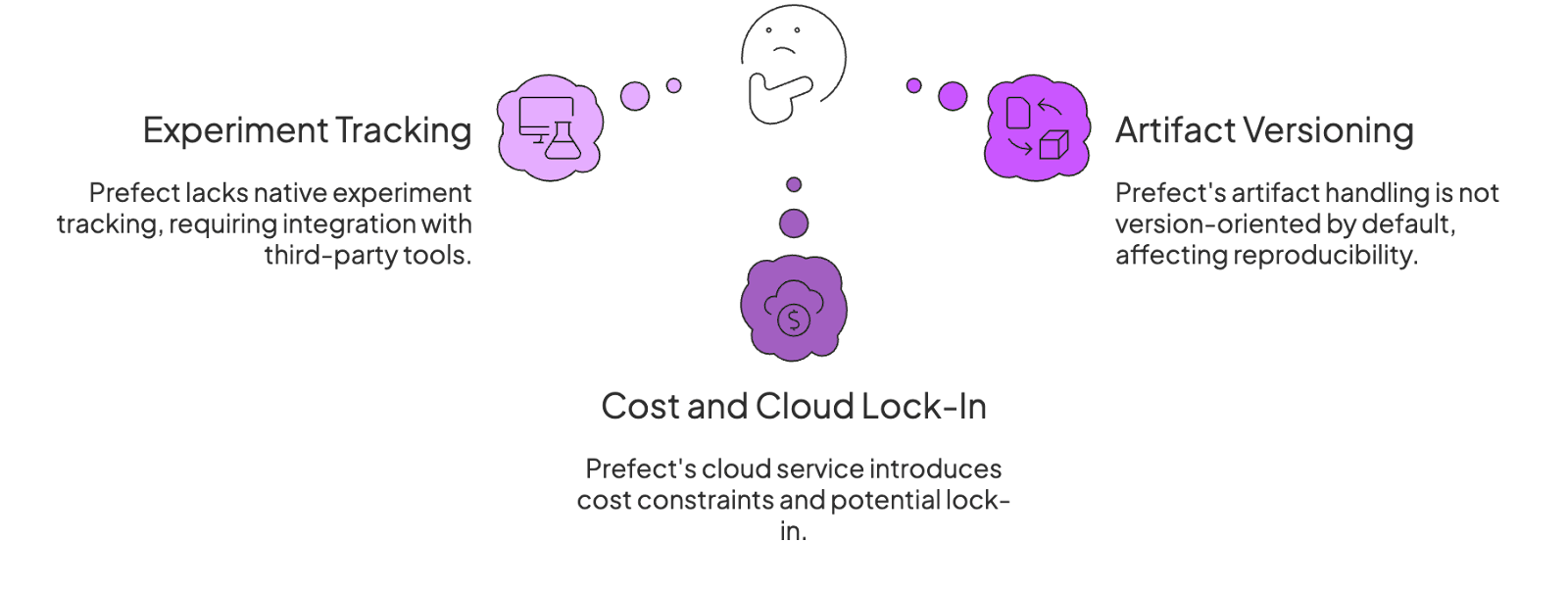
Reason 1. Missing First-Class Experiment Tracking and Model Registry
Prefect focuses on orchestration and leaves experiment tracking to external systems. It provides no native experiment UI or model registry for logging metrics, parameters, or model versions.
If you’re a Prefect user, you must integrate with third-party tools like MLflow or Weights & Biases to track ML experiments. This adds complexity – you end up managing multiple platforms to get a full picture of pipeline runs and model results.
✅ ZenML addresses this by offering automatic experiment logging out of the box. It seamlessly captures metrics, parameters, and model versions, reducing complexity and the need to integrate multiple platforms.
Reason 2. Limited Artifact Versioning
Prefect’s handling of artifacts and results is not version-oriented by default. By design, any return value from a Prefect task or flow is ephemeral – results are not persisted to the Prefect backend unless you explicitly enable result persistence.
Intermediate outputs (what Prefect calls ‘artifacts’) are mutable and can be overwritten in place; there’s no automatic version history for data produced during pipelines. Artifacts are versioned if a key is supplied; the UI shows the history.
In fact, to retain outputs between flow runs, you must adjust settings or code (persist_result flags, storage blocks, etc.) to store results in an external location.
✅ To resolve the issue, ZenML provides built-in artifact versioning by default. All outputs, artifacts, and parameters are versioned automatically, ensuring complete reproducibility and lineage without additional configuration. Prefect’s artifact versioning is manual (you must supply a key); ZenML versions everything automatically.
Reason 3. Cost and Cloud Lock-In Considerations
While Prefect’s open-source core is free, Prefect’s managed Cloud service introduces cost constraints and potential lock-in. The Prefect Cloud Starter plan begins at $100/month for only 3 developer seats and up to 20 workflows.
Key enterprise features – role-based access control (RBAC), longer log retention beyond a few days, high API rate limits, and SSO integrations – are gated behind Pro or Enterprise tiers. For growing teams, costs can escalate quickly as you scale users and flow deployments.

✅ That’s why you should use ZenML. Our platform emphasizes backend flexibility with zero vendor lock-in. You can easily configure and switch between different storage and compute backends, providing cost efficiency and complete control over your deployment environments.
Evaluation Criteria
When evaluating Prefect alternatives, we focused on a few key criteria to ensure any new tool meets the demands of modern ML workflows:
1. Deployment Flexibility and Cloud Neutrality
We looked for tools that are cloud-agnostic and flexible in how they can be deployed. This means supporting multiple environments (local, on-premises, various cloud providers) without hassle.
A strong alternative should not force you into a specific cloud service or proprietary managed solution – unless you want it.
The ability to self-host or run the tool within your own cloud account is a big plus, as it avoids lock-in and allows sensitive data to remain under your control.
We also considered how easy it is to scale the tool’s deployment: Can you start quickly on a laptop and then scale up to a distributed cluster or a managed service?
A cloud-neutral orchestrator, for example, would let you run workflows on AWS, GCP, or Azure, or even switch between them, with minimal changes.
2. Observability and Debugging Experience
Effective pipeline management requires more than just running tasks – you need insight into what’s happening.
We evaluated whether each alternative provides a rich observability layer: think interactive UIs or dashboards to monitor workflows, real-time logs and metrics for each run, and alerting capabilities.
A good debugging experience includes features like an interactive DAG view (so you can click on a failed node and see what went wrong), the ability to retry or replay tasks, and logs that are searchable and organized by run, task, or trigger.
3. Ecosystem Integration
No tool operates in a vacuum, especially in MLOps, where pipelines touch many systems - data warehouses, feature stores, model serving platforms, etc.
We assessed how well each alternative integrates with the broader ecosystem. This includes native connectors or plugins for common tools and frameworks – for example, does the platform have built-in support for things like Snowflake or BigQuery, TensorFlow or PyTorch, model serving tools, or experiment trackers like MLflow?
An alternative gets bonus points if it has a rich plugin library or SDK that makes it easy to extend.
Essentially, the best alternatives play nicely with others, allowing you to ‘mix and match’ components in your ML platform.
What are the Best Alternatives to Prefect?
Some of the best alternatives to Prefect are:
| Category | Alternatives | Key Features |
|---|---|---|
| 1. Workflow Orchestration and Deployment | ZenML, Apache Airflow, Metaflow | Python-native orchestration, flexible deployment |
| 2. Artifact and Data Versioning | lakeFS, MLflow | Version-controlled artifacts, reproducibility |
| 3. Observability and Experiment Tracking | Weights & Biases, Neptune AI, Kedro | Real-time monitoring, robust experiment tracking capabilities |
Category 1. Python-Native Workflow Orchestration
The first three alternatives – ZenML, Apache Airflow, and Metaflow – focus on orchestrating machine learning workflows, emphasizing seamless deployment and pipeline management capabilities.
1. ZenML
ZenML is an open-source MLOps framework that provides Python-native pipeline orchestration tailored to ML workflows.
Created to bridge the gap between research experimentation and production, ZenML lets you define pipelines using familiar Python code and then run them on various orchestration backends (from local execution to Kubernetes) with minimal changes.
ZenML’s Python-Native Workflow Orchestration Features
ZenML transforms Python code into reproducible ML pipelines with simple decorators. You write regular Python functions, add @pipeline and @step decorators, and ZenML constructs the workflow DAG automatically. No heavy DSL or YAML configuration required. Your code stays Pythonic while ZenML handles the orchestration complexity.
You can create a step on ZenML with a few lines of code:
from zenml import step
@step
def load_data() -> dict:
training_data = [[1, 2], [3, 4], [5, 6]]
labels = [0, 1, 0]
return {'features': training_data, 'labels': labels}The framework’s stack architecture separates pipeline logic from infrastructure. You develop locally and deploy to any environment by switching configurations. A single pipeline runs on your laptop during development, then deploys to Kubernetes, Airflow, or Kubeflow in production without code changes. Each stack combines components like orchestrators, artifact stores, and compute resources.
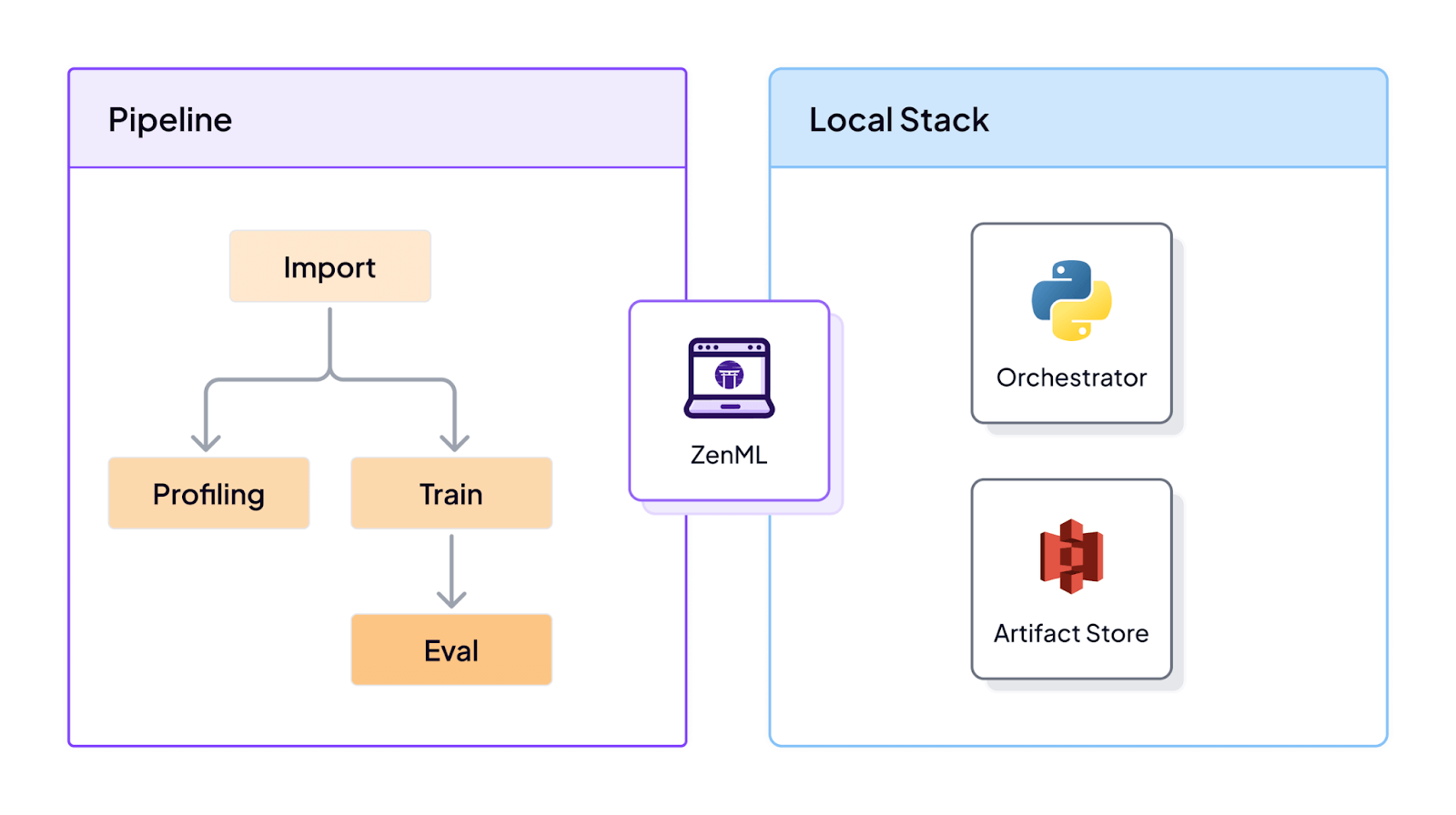
This approach solves the ‘works on my machine’ problem. ML engineers and data scientists write familiar Python code while ZenML manages execution across different environments. The same pipeline that processes test data locally can scale to production workloads on cloud infrastructure. Multi-cloud deployments become straightforward since infrastructure choices exist in configuration, not code.
Other Prominent Features
- Automatic Experiment Logging: Provides ‘Full Visibility, Zero Effort’ logging of everything from code versions to data to parameters. When you run a pipeline, it automatically captures run metadata, system environment, and even the Git commit of your code. This built-in experiment tracking helps you compare runs and know exactly what code and data produced each model, without adding extra logging code by hand.
- Built-in Lineage and Artifact Tracking: Every pipeline run in ZenML automatically tracks the artifacts and metadata of each step. ZenML versions all outputs and parameters by default, giving you a lineage of how each artifact was produced.
- Backend Flexibility – No Vendor Lock-in: ZenML emphasizes ‘backend flexibility, zero lock-in’ as a core feature. You can mix and match storage, compute, and orchestrators. For instance, use S3 for artifact storage, run orchestration on Kubernetes, and deploy models to AWS SageMaker – all configured in a ZenML stack.
Pros and Cons
ZenML provides an end-to-end framework that covers orchestration and basic experiment tracking in one tool. It’s highly Pythonic and makes it easy for ML engineers to define pipelines with decorators instead of learning a new DSL. Its stack abstraction and backend flexibility gives you true cloud freedom.
As a newer player, ZenML’s ecosystem and community are still growing – it’s not as battle-tested as Apache Airflow or MLflow in large-scale deployments (though it’s maturing quickly).
2. Apache Airflow
Apache Airflow remains the most battle-tested workflow orchestrator in the data ecosystem. Originally developed at Airbnb and now an Apache Software Foundation project, it powers data pipelines at thousands of organizations through its mature DAG-based architecture.
Airflow’s Python-Native Workflow Orchestration Features
Airflow uses the concept of Directed Acyclic Graphs (DAGs) to define workflows in Python.
In a DAG file, you declare tasks using operators like the PythonOperator to run Python functions, the BashOperator for shell commands, etc., and set dependencies between tasks to control their execution order.
The Airflow scheduler handles triggering these tasks at the right times (based on a cron schedule or manual trigger), and it manages retries if tasks fail.
Under the hood, Airflow’s extensible executor system lets you choose how tasks run: for example,
- A LocalExecutor can run tasks on a single machine process for simple setups,
- A CeleryExecutor distributes work across multiple worker nodes
- The KubernetesExecutor launches each task in its own pod for cloud-native scaling.
This flexibility means Airflow can be deployed almost anywhere – on a single server, across VMs, or on a Kubernetes cluster – whether in the cloud or on-prem. Teams often deploy Airflow with a persistent database and a web server component, ensuring that the orchestration environment is robust and accessible for monitoring.
Other Prominent Features
- Provides a web-based UI to visualize DAGs, monitor task progress, view logs, and manage runs. This makes it easy to see your pipeline’s state at a glance and troubleshoot issues.
- It comes with a large ecosystem of pre-built operators and hooks for common tools and platforms (e.g., AWS, GCP, Azure services, databases, Hadoop/Spark).
- Each Airflow task can be configured with retry behavior (number of retries, delay between retries), and Airflow will automatically re-run failed tasks according to that policy.
Pros and Cons
Airflow is a proven, robust orchestrator with years of real-world use. It excels at scheduling complex workflows with dependencies and timing. If your use case is to run a reliable daily or hourly pipeline, Airflow offers industrial-grade solutions with functionalities like retries, alerting, backfills, and more.
However, compared to newer ML-focused tools, Airflow to us felt heavyweight and not ML-native. It was originally designed for ETL jobs, so it lacks built-in experiment tracking, model registry, or artifact versioning – you’d have to incorporate those separately.
📚 Relevant articles to read:
<a href="https://www.zenml.io/integrations/airflow" target="_blank">ZenML integrates with Apache Airflow</a> to streamline ML workflows. This powerful combination simplifies the orchestration of complex machine learning workflows, enabling data scientists and engineers to focus on building high-quality models while leveraging Airflow's proven production-grade features.3. Metaflow
Developed by Netflix to boost data scientists’ productivity, Metaflow provides a unique approach to ML workflow orchestration. It focuses on making the transition from prototype to production as smooth as possible while handling infrastructure complexity behind the scenes.
Metaflow’s Python-Native Workflow Orchestration
In Metaflow, you create a Python class (subclassing FlowSpec) to define a workflow, and within it, decorate methods with @step to mark them as steps in the flow.
from metaflow import FlowSpec, step
class MyFlow(FlowSpec):
@step
def start(self):
self.next(self.end)
@step
def end(self):
pass
if __name__ == '__main__':
MyFlow()The order of execution is specified by using self.next() transitions between steps, forming a DAG of tasks. This human-friendly API hides the underlying orchestration complexity.
By default, Metaflow runs workflows locally, but it offers seamless scalability to the cloud. For example, you can use decorators like @batch or @kubernetes on a step to indicate it should execute on AWS Batch or a Kubernetes cluster – Metaflow will package that code, ship it to the cloud, and retrieve results automatically.
Other Prominent Features
- Every step in Metaflow can produce data (Python objects), and Metaflow automatically stores these artifacts in a content-addressed data store (commonly an S3 bucket). These artifacts are versioned by run ID, meaning you can always retrieve the data produced by any step of any run.
- Although Metaflow itself is CLI/SDK driven, Netflix open-sourced a Metaflow UI that can be deployed to visualize flows, runs, and artifacts. This isn’t built into the OSS by default, but it’s available. It provides a graph of your pipeline and run details.
- If a flow fails at some step, Metaflow allows you to resume from that step once you’ve fixed the issue, rather than re-running from scratch. Because artifacts are persisted from earlier steps, you don’t lose the intermediate state. This can save a lot of time in debugging.
Pros and Cons
If you’re a Python user, you will find Metaflow extremely easy to use. It feels like writing a normal script, with minimal hassle around defining workflows. This lowers the barrier for ML engineers and data scientists to orchestrate their own pipelines.
However, remember that inspecting runs can be done either via the command line or by setting up a separate UI service. This is a con for those who prefer a polished web UI like Prefect or Airflow have.
📚 Relevant articles to read:
Category 2. Artifact and Data Versioning
Effective data and artifact versioning is crucial for reproducibility and lineage tracking. Alternatives like lakeFS and MLflow specifically address Prefect’s limitations around persistent and versioned artifact storage.
4. lakeFS
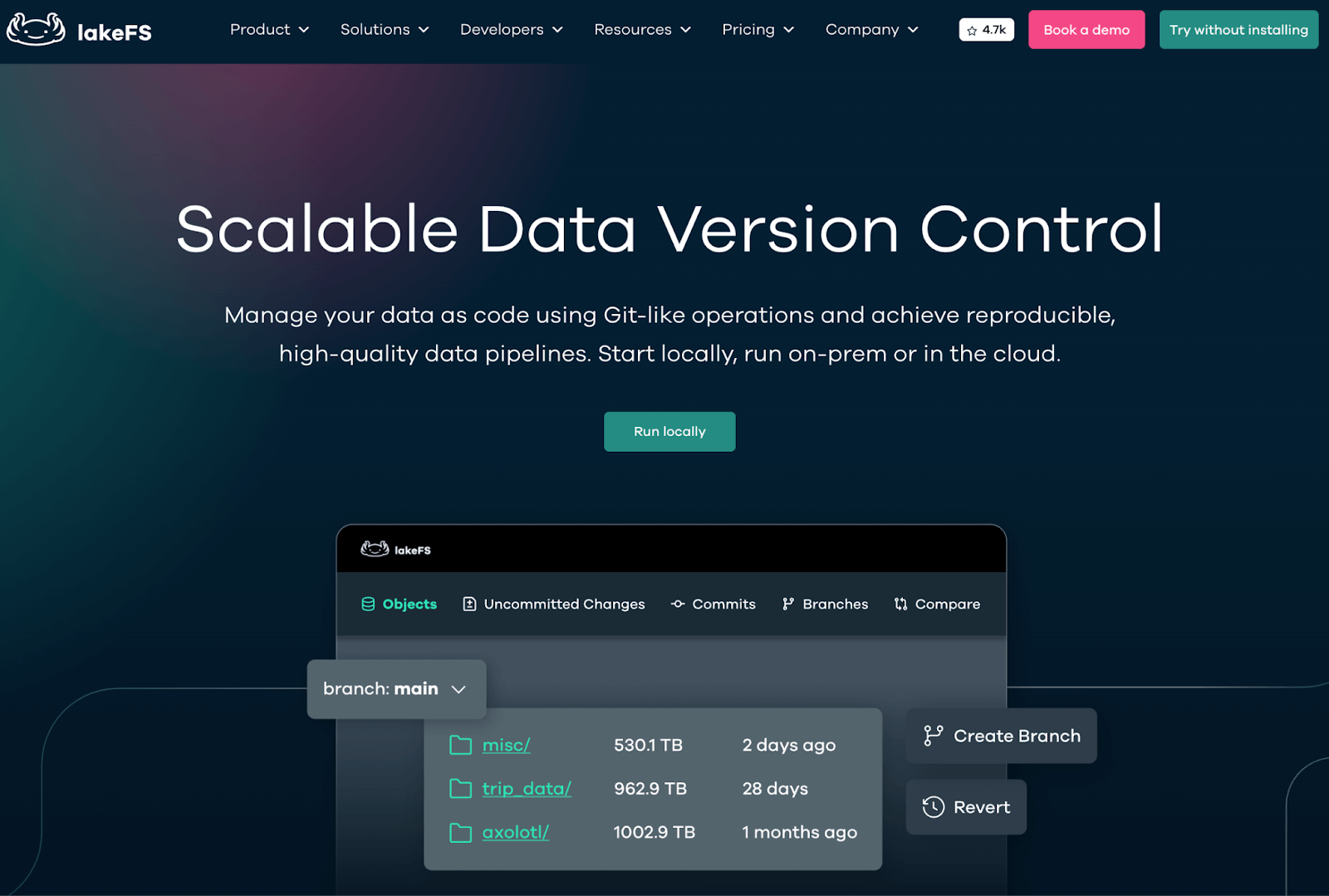
lakeFS brings Git-like version control to data lakes, solving one of the most challenging aspects of ML pipelines – data versioning and lineage. By treating data as code, it enables reproducibility and experimentation at the data layer.
lakeFS’ Artifact and Data Versioning Features
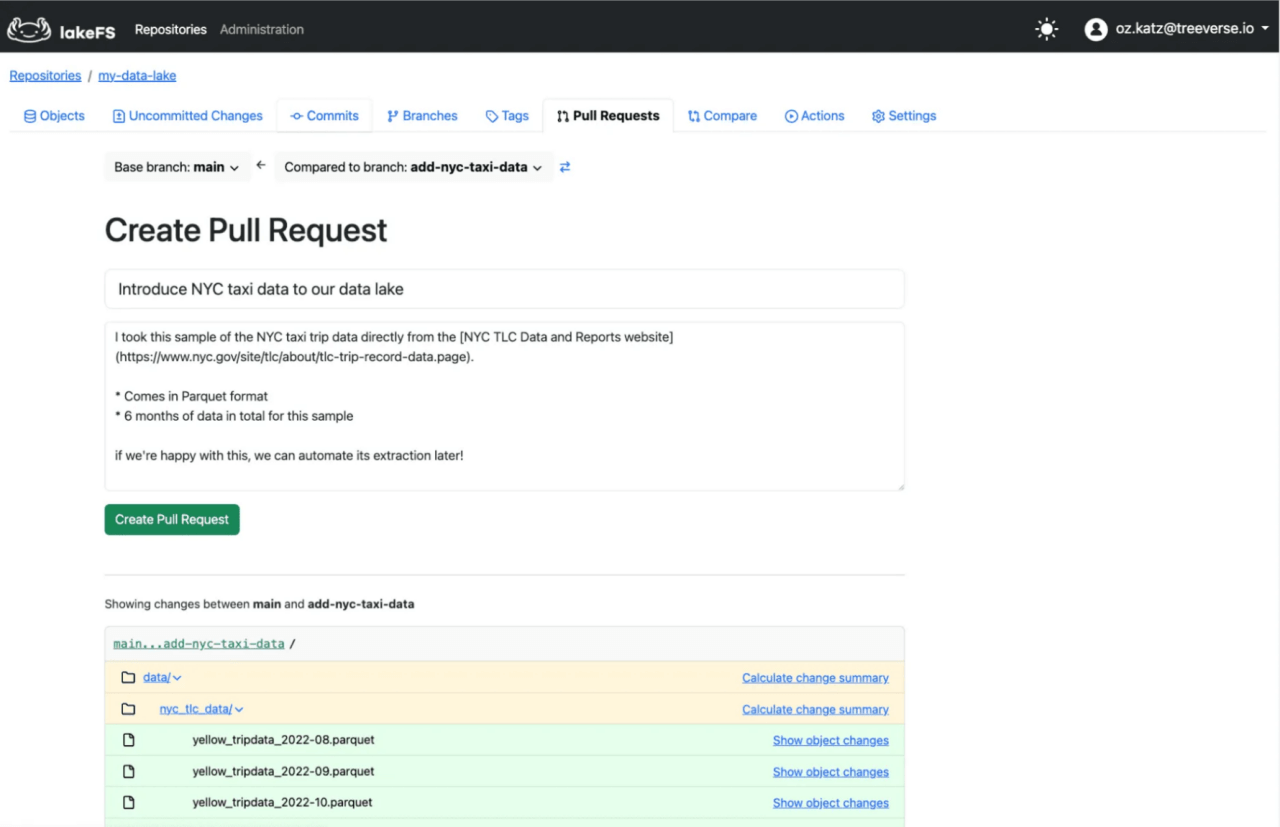
akeFS versions data using Git-like operations. You create branches that serve as isolated snapshots of your data at specific points in time. Each branch tracks changes independently without affecting other branches.
When you modify files in a branch and commit, lakeFS creates an immutable checkpoint of your entire data lake state. These commits get unique identifiers similar to Git SHAs. You can merge branches to integrate changes from experiments into production datasets.
The branching happens through zero-copy operations. Creating a new branch doesn’t duplicate data physically but creates pointers to the current state. This approach makes branching instant regardless of data size.
During merges, lakeFS detects conflicts when branches modify the same files differently. You resolve these by selecting one version or reconciling manually. This version control mechanism ensures you can always reproduce ML experiments by referencing exact data snapshots used during training.
Other Prominent Features
- When merging branches in lakeFS, if there are conflicts like two branches modified the same file differently, lakeFS will flag it. You can then resolve conflicts by choosing one version or manually reconciling.
- lakeFS can sit in front of sensitive data and provide controlled access via branches. You might give certain teams access only to specific branches, which acts as a security layer.
- lakeFS allows you to tag commits with human-friendly names (just like Git tags). For instance, you could tag a commit as ‘v1.0 data release’ or ‘before_retraining’.
Pros and Cons
lakeFS offers true version control for data, a game-changer for reproducible ML and data engineering. It gives you confidence that you can always reproduce a model or analysis by pinpointing the exact data snapshot used.
But keep this in mind that lakeFS is specialized for data versioning, so it’s not a full pipeline orchestrator or ML platform by itself. You still need something like ZenML or Airflow to schedule jobs, and perhaps an experiment tracker for metrics – lakeFS will version the data, but not track model metrics or parameters.
5. MLflow
MLflow is an open-source platform for managing the ML lifecycle, primarily known for its experiment tracking and model registry components. It does not orchestrate workflows like Prefect, but it complements orchestrators by handling the metadata, parameters, metrics, artifacts, and models that result from ML runs.
MLflow’s Artifact and Data Versioning Features
MLflow Tracking records every run of an ML experiment with a unique run ID under an experiment name.
For each run, you can log:
- Metrics: Numerical performance values
- Parameters: Input settings
- All essential artifacts: Models, Plots, or data snapshots
MLflow’s Tracking Server uses an artifact store (a blob storage or local filesystem) to save these artifacts for each run.
This provides a basic form of artifact versioning. Every run’s artifacts are stored in a structured directory, and you can retrieve any past run’s artifacts via the UI or API.
For example, if run abc123 produced a model file and a confusion matrix plot, MLflow keeps those accessible and immutable in that run’s artifact directory.
Lastly, the MLflow Model Registry is a dedicated component for versioning models in a lifecycle. You register a model name, and MLflow will allow you to push model artifacts as new versions of that model. Each version can have metadata, tags, and a stage, for example - ‘Version 5 is Staging,’ ‘Version 2 in Production,’ etc.
Other Prominent Features
- MLflow’s tracking API is available in Python, R, Java, and REST. So, it’s not limited to Python workflows – if you have a Java training pipeline, it can still log to the same MLflow server. This is helpful in heterogeneous environments.
- MLflow has simple ways to deploy models (example -
mlflow models serveto launch a REST API for a model, or plugins to deploy to SageMaker or Spark). These are basic but can cover quick deployment needs or testing served models. - Although open-source MLflow is free to use, there are managed versions like those on Databricks or Azure ML that integrate it deeply. This means if you ever outgrow managing it yourself, you could switch to a managed service and not change your logging code. That flexibility is nice.
Pros and Cons
MLflow is widely adopted and has become a standard for experiment tracking, meaning lots of tools integrate with it. It provides a simple yet effective way to track experiments and artifacts, solving one of Prefect’s biggest gaps.
No doubt about MLflow’s artifact and data versioning capabilities, but it’s not an orchestrator, so on its own, it doesn’t replace Prefect – it’s a complementary tool. Using MLflow introduces an additional service to manage (an MLflow server and a backing DB).
📚 Relevant articles to read:
<a href="https://www.zenml.io/integrations/mlflow" target="_blank">Integrate the power of MLflow's experiment tracking</a> capabilities directly into your ZenML pipelines. Effortlessly log and visualize models, parameters, metrics, and artifacts produced by your pipeline steps, enhancing reproducibility and collaboration across your ML workflows.Category 3. Observability and Experiment Tracking
Observability and robust experiment tracking are essential for understanding and optimizing ML experiments. Tools such as Weights & Biases, Neptune AI, and Kedro enhance visibility into pipeline executions and facilitate effective collaboration.
6. Weights & Biases
Weights & Biases has emerged as the premium experiment tracking platform, offering unparalleled visualization and collaboration features. While not an orchestrator, its deep integration capabilities make it a powerful complement to any workflow tool.
Weights & Biases’ Experiment Tracking and Metadata Features
W&B tracks experiments through automatic logging of metrics, hyperparameters, and system metadata. Each run captures loss curves, accuracy trends, and custom metrics that update in real-time dashboards. The platform records configuration details, code versions, dataset references, and hardware specifications alongside performance data.
Beyond metrics, W&B logs rich media, including model predictions, confusion matrices, and attention maps. You can compare runs side-by-side, filter by hyperparameters, and analyze which configurations perform best. The platform maintains complete experiment lineage: what code produced which model using what data.
Interactive visualizations let you zoom into training curves, overlay multiple runs, and spot patterns across experiments. Tables organize runs by metadata fields like learning rate or batch size. This combination of automatic tracking and flexible visualization accelerates debugging and optimization. Every logged element becomes searchable metadata that helps reproduce successful experiments or understand failures.
Other Prominent Features
- Lets you version control data and model artifacts through the platform. The platform lets you log a dataset as an artifact, and each new version of the dataset becomes a new version in W&B, tracked with a unique ID and lineage info.
- Includes a robust hyperparameter sweep system. You define a search space (grid, random, Bayesian), and W&B will orchestrate running multiple trials, either sequentially or in parallel, to explore that space.
- Allows you and your team to collaborate on projects, with all experiment logs in a shared workspace. It also offers Reports, which are like interactive documents or dashboards that can include plots, tables, and notes, all linked to live results.
Pros and Cons
Weights & Biases offers a superior user experience for experiment tracking – its UI is feature-rich and designed by/for ML practitioners. You get real-time insights into training, which is invaluable for speedy iteration. The visualizations and comparisons are top-notch, with minimal effort required from the user to set it up.
But one thing to note is that Weights & Biases is primarily a hosted SaaS (cloud-based), which raises data privacy concerns. While they do offer an on-prem version for enterprise (and a local proxy option), the default is sending your experiment data to their cloud.
📚 Relevant articles to read:
<a href="https://www.zenml.io/integrations/wandb" target="_blank">Integrate Weights & Biases with ZenML</a> to track, log, and visualize your pipeline experiments effortlessly. This powerful combination enables you to leverage Weights & Biases' interactive UI and collaborative features while managing your end-to-end ML workflows with ZenML's pipelines.7. Neptune AI
Neptune provides a flexible metadata store for ML experiments, positioning itself between lightweight trackers and comprehensive platforms. Its strength lies in organizing and querying experimental data at scale.
Neptune’s Experiment Tracking and Metadata Features
Neptune is designed to handle a very high volume of logged metadata. You can log hundreds of metrics, even per epoch or per batch metrics for deep learning, and Neptune’s backend pre-processes and indexes this so that the UI remains responsive.
Let’s say you log every layer’s weights histogram from a neural network or the loss for every iteration, resulting in a huge time series; Neptune can still let you visualize or query that quickly. This focus on performance at scale is one of its differentiators.
Nepture provides an experiment dashboard where each run of your model (an experiment) is logged and can be viewed later. To use Neptune, you initialize a run in your code – neptune.init_run(project="workspace/project"), and then log various things:
- Scalars like metrics, for example, accuracy per epoch
- Hyperparameters
- Text logs
- Images like confusion matrix plots
- Artifacts – model weights, data files
Other Prominent Features
- Start logging with just two lines of code. Gradual adoption without refactoring existing workflows.
- Share projects with fine-grained permissions. Comment on experiments and create shared views.
- Works with any Python code and ML framework. Easy integration with various orchestrators, including several Prefect alternatives.
Pros and Cons
Neptune is highly scalable and organized for experiment tracking, making it ideal for your team if you generate a large number of experiments or detailed logs. Its fast, responsive UI at scale is what makes it special – you can log everything from your runs and still query and visualize it quickly.
However, Neptune’s visualization is more utilitarian – it may lack some advanced chart types or media handling that W&B provides.
<a href="https://www.zenml.io/integrations/neptune" target="_blank">Seamlessly integrate Neptune's advanced experiment tracking</a> features into your ZenML workflows to optimize your machine learning experimentation process. Leverage Neptune's intuitive UI to log, visualize, and compare pipeline runs, making it easier to identify the best performing models and iterate faster.8. Kedro
Kedro brings software engineering best practices to machine learning and data science workflows. Developed by QuantumBlack, it emphasizes maintainability, modularity, and collaboration in ML projects.
Kedro’s Observability and Experiment Tracking Features
Kedro enhances observability and experiment tracking primarily through its structured approach to pipeline development and reproducibility.
At its core, Kedro enforces well-structured pipeline definitions where work is broken into pure functions (nodes) with declared inputs and outputs, which enables automatic dependency resolution and eliminates manual orchestration errors.
This structure feeds into Kedro-Viz, a visualization tool that displays the pipeline DAG alongside data connections, providing clear data lineage information and allowing developers to see their entire workflow at a glance. While not a live monitoring solution, this static visualization aids in understanding data flow and debugging issues.
Kedro’s Data Catalog offers configuration-driven data management with built-in versioning support for file-based systems, automatically timestamping and managing file paths to prevent accidental overwrites and enable reference to historical outputs. This lightweight versioning addresses the ephemeral data challenges found in other orchestration tools.
Although Kedro doesn’t include native experiment tracking UI, it promotes reproducibility through a clear separation of parameters, data, and code in structured formats. The framework’s flexibility shines through its plugin ecosystem, particularly the Kedro-MLflow integration, which bridges Kedro pipelines with dedicated experiment tracking platforms by automatically logging parameters, metrics, and data versions.
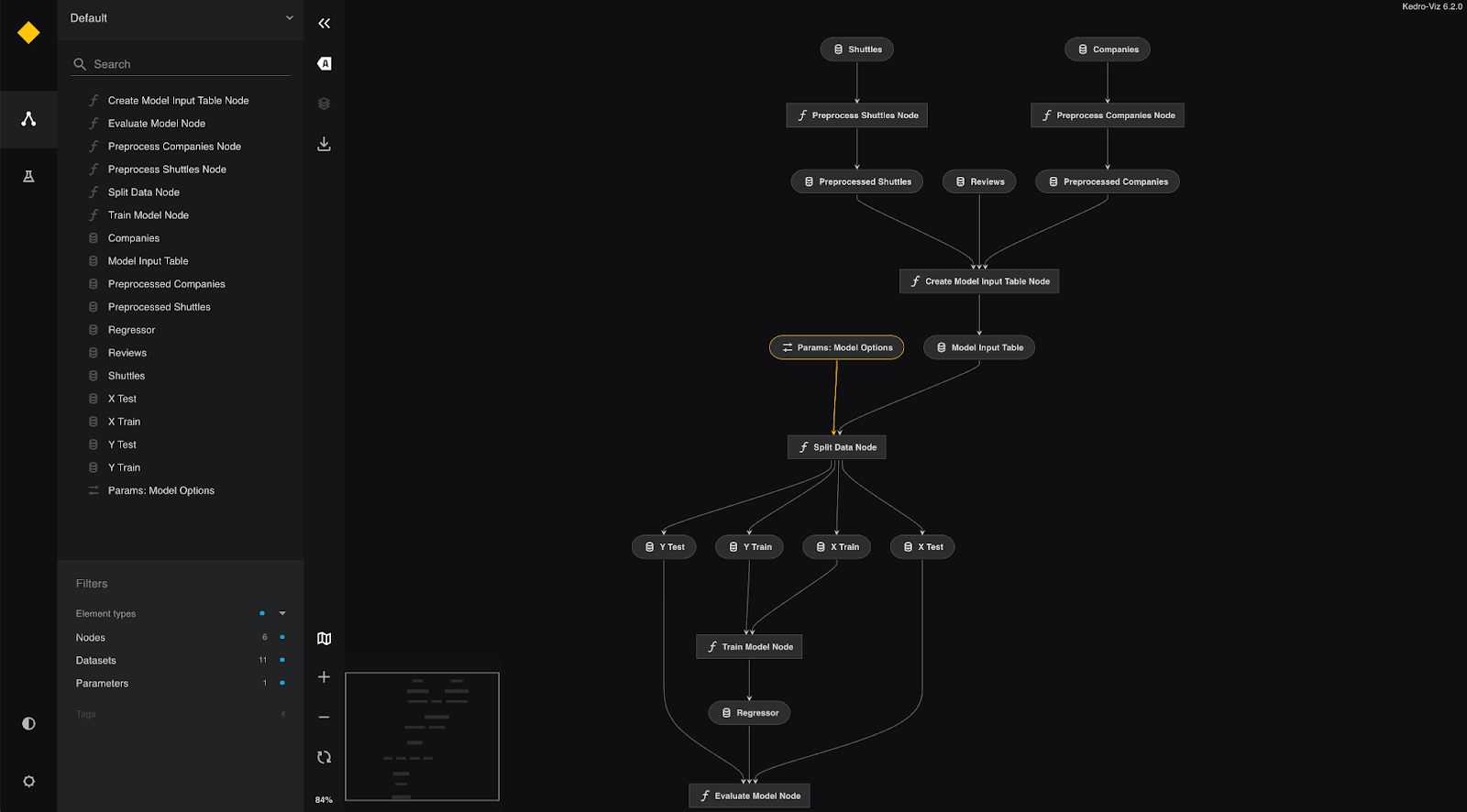
Other Prominent Features
- Lets you build reusable pipeline components with clear interfaces. You can also compose complex workflows from tested building blocks.
- Kedro's core involves nodes (wrappers for Python functions) and pipelines (collections of nodes) that organize dependencies and execution order. It supports building, merging, and describing pipelines, along with modular pipeline creation.
- Supports various deployment strategies, including single or distributed-machine deployment, and offers integrations with orchestrators like Apache Airflow, Prefect, Kubeflow, AWS Batch, and Databricks.
Pros and Cons
Kedro brings software engineering rigor to data/ML pipelines – a huge pro if your team has suffered from messy spaghetti code in workflows. It enforces a clean architecture and separation of concerns, which leads to more maintainable and debuggable pipelines.
Kedro is not an orchestrator – you will still need something to actually schedule/run the pipelines in production - Kedro can run them locally or you can invoke them in a script, but it doesn’t have a server or scheduler. This means the platform is often used alongside Prefect, not instead of, which could add complexity.
What’s the Best Prefect Alternative for ML Teams
The right Prefect alternative depends on your primary pain points.
- If you need full ML pipeline orchestration with experiment tracking and model deployment, ZenML provides the most complete solution. Its Python-native approach and flexible infrastructure stacks make it practical for teams that want to ship models to production.
- For teams focused on specific challenges, lakeFS excels at data versioning, MLflow handles model lifecycle management well, and Weights & Biases delivers superior experiment visualization. Kedro works best for data scientists who prioritize clean code structure over deployment features.
Now might be a good time to consider ZenML as a Prefect alternative if you want a single tool that covers the entire ML workflow. Starting with an all-in-one solution like ZenML reduces integration complexity while you establish your MLOps practices.
Still confused about where to get started? Book a personalized demo call with our Founder and discover how ZenML can help you build production-ready ML pipelines with true multi-cloud flexibility.