
Pydantic AI vs CrewAI: Which One’s Better to Build Production-Grade Workflows with Gen AI
In this Pydantic AI vs CrewAI, we discuss which one is better at building production-grade workflows with generative AI.

Oct 26, 202512 mins
17 posts with this tag
In this Pydantic AI vs CrewAI, we discuss which one is better at building production-grade workflows with generative AI.

Discover the 9 best LLM orchestration frameworks for agents and RAG.

In this Langflow vs n8n, we compare both platforms’ features, pricing, and integrations.
Discover the 9 best data embedding models for RAG pipelines you build this year.

Discover the 10 best data vector databases for RAG pipelines.

In this Haystack vs LlamaIndex, we explain the difference between the two and conclude which one is the best to build AI agents.
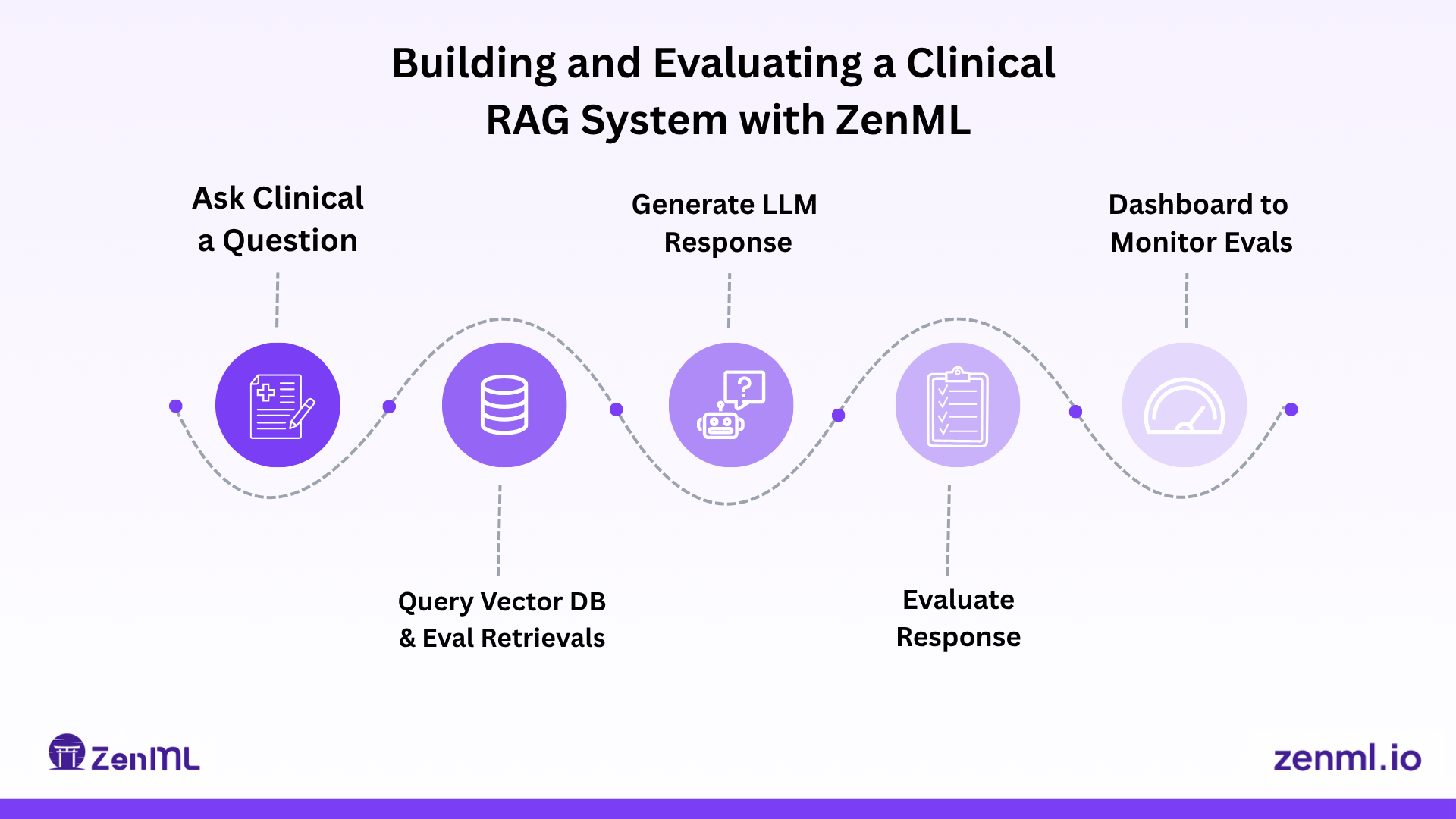
On custom evaluation frameworks for clinical RAG systems, showing why domain-specific metrics matter more than plug-and-play solutions when trust and safety are non-negotiable.

In this Vellum AI pricing guide, we discuss the costs, features, and value Vellum AI provides to help you decide if it’s the right investment for your business.

In this Semantic Kernel vs Autogen article, we explain the differences between the two frameworks and conclude which one is best suited for building AI agents.

Discover the top 8 RAG tools for agentic AI you should try this year.
Are your query rewriting strategies silently hurting your Retrieval-Augmented Generation (RAG) system? Small but unnoticed query errors can quickly degrade user experience, accuracy, and trust. Learn how ZenML's automated evaluation pipelines can systematically detect, measure, and resolve these hidden issues—ensuring that your RAG implementations consistently provide relevant, trustworthy responses.

Practical lessons on prompt engineering in production settings, drawn from real LLMOps case studies. It covers key aspects like designing structured prompts (demonstrated by Canva's incident review system), implementing iterative refinement processes (shown by Fiddler's documentation chatbot), optimizing prompts for scale and efficiency (exemplified by Assembled's test generation system), and building robust management infrastructure (as seen in Weights & Biases' versioning setup). Throughout these examples, the focus remains on systematic improvement through testing, human feedback, and error analysis, while balancing performance with operational costs and complexity.

An in-depth exploration of LLM agents in production environments, covering key architectures, practical challenges, and best practices. Drawing from real-world case studies in the LLMOps Database, this article examines the current state of AI agent deployment, infrastructure requirements, and critical considerations for organizations looking to implement these systems safely and effectively.

Discover how embeddings power modern search and recommendation systems with LLMs, using case studies from the LLMOps Database. From RAG systems to personalized recommendations, learn key strategies and best practices for building intelligent applications that truly understand user intent and deliver relevant results.

Explore real-world applications of Retrieval Augmented Generation (RAG) through case studies from leading companies in the ZenML LLMOps Database. Learn how RAG enhances LLM applications with external knowledge sources, examining implementation strategies, challenges, and best practices for building more accurate and informed AI systems.

As organizations rush to adopt generative AI, several major tech companies have proposed maturity models to guide this journey. While these frameworks offer useful vocabulary for discussing organizational progress, they should be viewed as descriptive rather than prescriptive guides. Rather than rigidly following these models, organizations are better served by focusing on solving real problems while maintaining strong engineering practices, building on proven DevOps and MLOps principles while adapting to the unique challenges of GenAI implementation.

We dive deep into the world of Retrieval-Augmented Generation (RAG) pipelines and how ZenML can streamline your RAG workflows.


