

On this page
DeepEval has become the go-to evaluation framework for many ML engineers testing LLM applications. Its Python-first approach and pre-built evaluation metrics make it appealing to many.
But as evaluation workflows scale, you hit limitations: heavy reliance on LLM-as-a-judge scoring, rising inference costs, or integration friction with non-Python ecosystems.
In this article, we survey the 8 best open-source LLM evaluation frameworks that serve as alternatives to DeepEval. We briefly discuss why you need an alternative, outline key criteria for choosing an eval framework, and then dive into the top tools available.
TL;DR
- Why Look for Alternatives: DeepEval's heavy reliance on LLM-as-a-judge scoring is expensive and slow. It doesn’t cover every scenario, like custom rule-based checks or integration with your data. DeepEval alternatives offer more cost-efficient, flexible, or transparent evaluation methods beyond AI judges.
- Who Should Care: ML engineers and Python developers building production LLM applications who need efficient evaluation frameworks with flexible metrics, cost transparency, and better integration with observability layers.
- What to Expect: We evaluate each alternative on cost efficiency, metric philosophy (judges, rules, or both), coverage of use cases (RAG, agents, safety), and data governance. Each framework handles single and multi-turn evaluations differently.
The Need for a DeepEval Alternative?
1. Heavy Reliance on LLM-as-a-judge
DeepEval leans almost entirely on using AI models to grade other AI models. In fact, nearly all metrics in DeepEval are LLM-as-a-judge.
At a time when LLMs are known to confidently produce plausible-sounding but entirely fabricated or incorrect information, using AI to judge another AI messes up the equation.
That’s why teams are shifting from DeepEval toward hybrid AI systems, emphasizing ‘human-in-the-loop’ processes. Human judgments remain costly and slow, though more reliable and accurate.

2. Cost and Latency of Large-Scale Evals
Using GPT-5 or similar large models as evaluation judges is not cheap. Each test case performs another LLM inference, compounding costs dramatically when you have hundreds or thousands of cases.
This means running a massive evaluation suite with DeepEval racks up significant API bills and also slows down CI pipelines due to the latency of model calls.
Many alternatives aim to reduce this by offering lighter-weight metrics (like embedding-based similarity or regex checks) or by allowing the use of smaller local models as judges to cut costs.
3. Python-First Ecosystem and Integration Friction
DeepEval’s design is inspired by unit testing (with Pytest integration) and comes with a companion cloud platform (Confident AI).
But fitting it into an existing MLOps toolchain requires extra effort. In short, if DeepEval doesn’t play nicely with your environment, an alternative with a more flexible or lightweight integration saves a lot of headaches.
Evaluation Criteria
Not all evaluation frameworks are built the same. Here are the key criteria to consider as you evaluate DeepEval alternatives:
- Associated costs: What is the true cost of ownership at scale? Understanding pricing models helps determine feasibility for large-scale deployments.
- Coverage of your use cases: Does the tool evaluate RAG, agents, chatbots, safety concerns, and more? Different frameworks excel in different domains, so matching coverage to your architecture is critical.
- Metric philosophy: Does the alternative offer judges, rules, or both? A balanced approach reduces costs while maintaining evaluation flexibility.
- Data, privacy, open source, and governance: Is it open-source? Can you self-host? Teams with compliance requirements need on-premise options and clear data handling practices.
What are the Top Alternatives to DeepEval?
Here’s a quick table comparing all the top DeepEval alternatives we’re going to talk about next:
| DeepEval Alternatives | Best For | Key Features | Pricing |
|---|---|---|---|
| ZenML | Teams that want a unified, end-to-end MLOps + LLMOps platform with built-in evaluation, reproducibility, and full pipeline observability. | - Includes a powerful evaluation framework ideal for RAG systems - Connects evaluation automatically into CI/CD workflows - Provides full experiment tracking and lineage across the entire LLM lifecycle | Both free and paid (custom pricing) |
| Ragas | RAG-specific evaluation with deep semantic metrics. | - Faithfulness and relevance scoring - Synthetic test generation - Hybrid evaluators | Free (Open-source) |
| TruLens | Trace-first evals with LLM feedback and integration with LangChain. | - Token-level trace logging - Built-in evals like groundedness - LLM feedback functions | Free (Open-source) |
| Promptfoo | Fast, repeatable prompt testing and CI integration. | - CLI + CI testing - Prompt performance tracking - Failure logs and metadata | Free (Open-source) |
| Arize Phoenix | Notebook-first debugging and RAG evals with OpenTelemetry. | - Local trace execution - LLM and metric-based evals - Cost-aware RAG tuning | - Open-source - Paid plan starts at $50 per month |
| Langfuse | Full-stack LLM observability with prompt control and evals. | - Nested trace trees - Prompt versioning - Live latency/cost dashboards | - Open-source - Paid plans start at $29 per month |
| UpTrain | Custom monitoring for safety, drift, and behavior regressions. | - Multi-modal evals (LLM, rules) - Feedback + drift logging - Segmented error analysis | Free (Open-source) |
| LangSmith | LangChain-native apps needing hosted trace + eval infra. | - Prompt + chain versioning - LLM/human/rule feedback - Visual debug tools | - Free - Paid plans start at $39 per month |
1. ZenML
Best for: Teams that want a unified, end-to-end MLOps + LLMOps platform with built-in evaluation, reproducibility, and full pipeline observability, making it one of the strongest full-stack DeepEval alternatives.
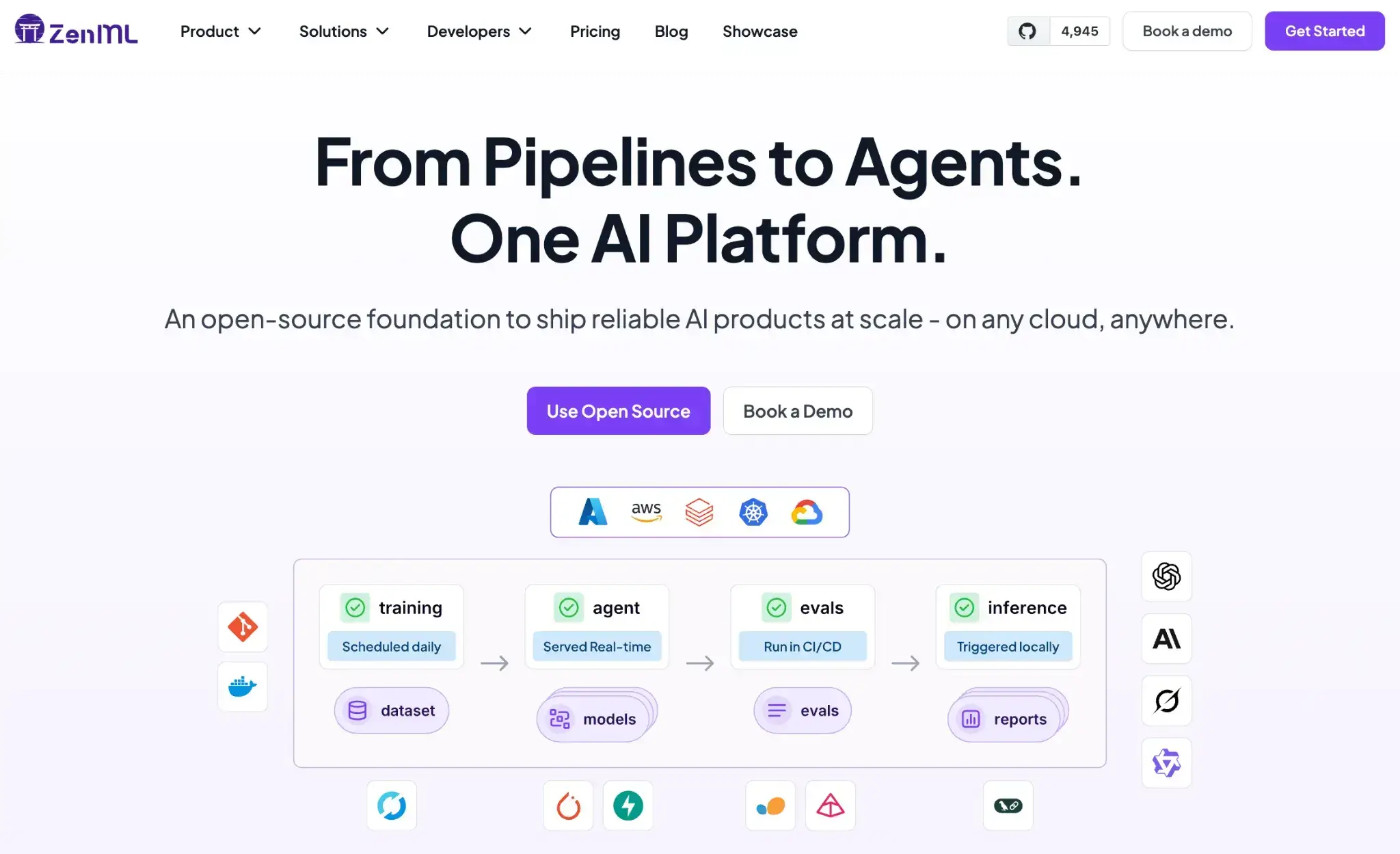
ZenML is an open-source MLOps + LLMOps framework designed to bring structure, reproducibility, and governance to ML and LLM applications.
As a DeepEval alternative, ZenML stands out because it integrates evaluation directly into orchestrated pipelines, giving teams not just metrics but also full lineage, versioning, and CI/CD automation around their evaluation workflows.
Key Feature 1. RAG Evaluation
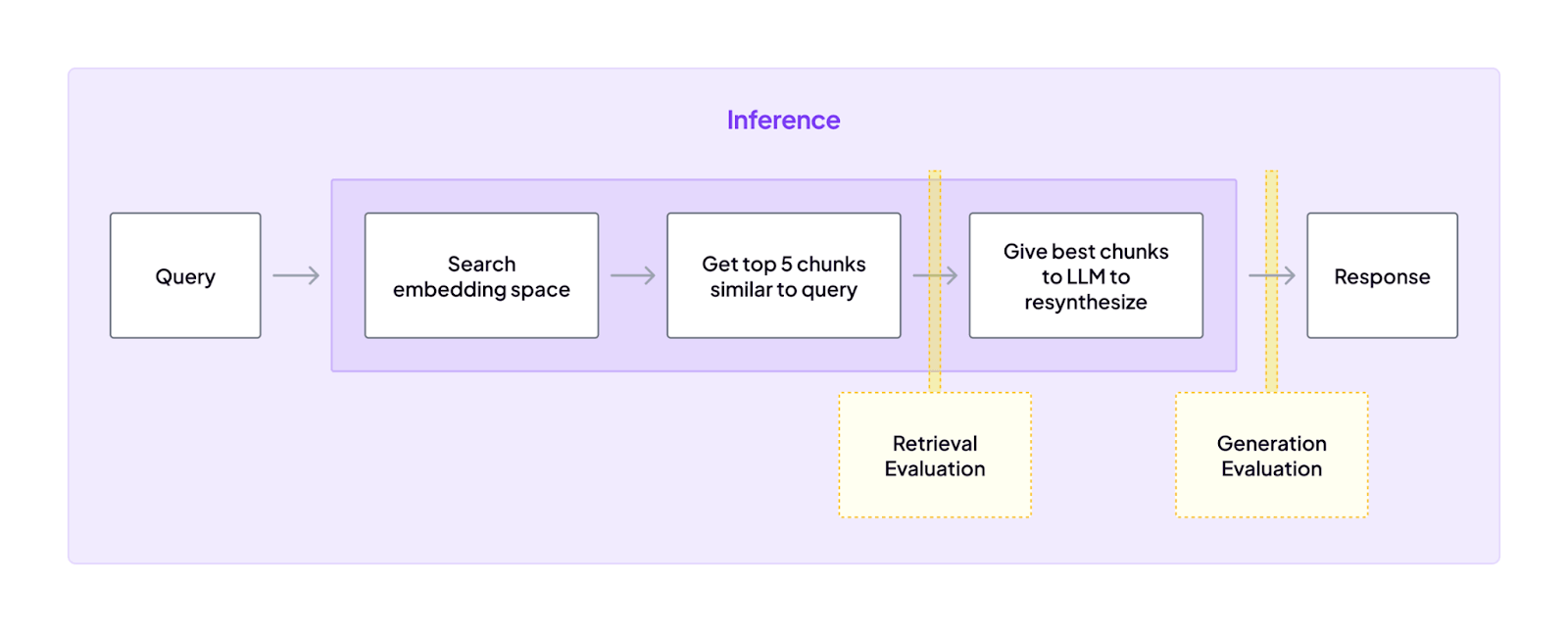
ZenML includes a powerful evaluation framework ideal for RAG systems. It supports building evaluation pipelines with metrics for relevance, factuality, hallucination detection, and context quality.
Using ZenML’s Evaluation Stack and standard evaluators, you can:
- Run structured RAG evaluations as part of reproducible pipelines.
- Combine LLM-based, embedding-based, or rule-based metrics.
- Version datasets, prompts, and results for complete reproducibility.
- Store all evaluation outputs (scores, artifacts, traces) centrally for comparison and governance.
This gives teams a systematic way to compare multiple retrievers, generators, models, or prompt versions; something DeepEval does not natively handle at the pipeline level.
Key Feature 2. CI/CD Integration
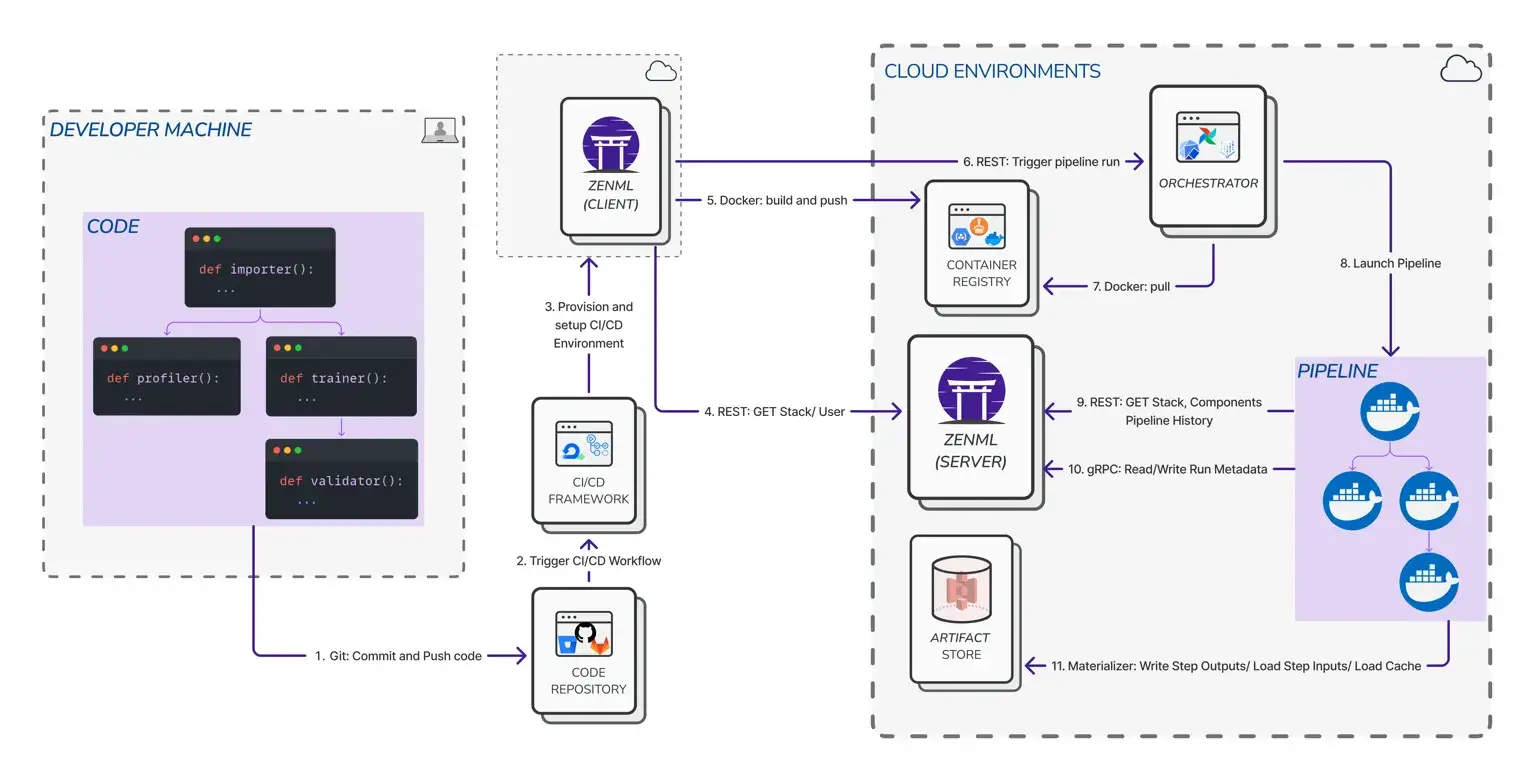
ZenML connects evaluation automatically into CI/CD workflows. Your evaluation steps run as part of CI pipelines, whether on GitHub Actions, GitLab CI, Jenkins, or cloud orchestrators.
With ZenML CI/CD, you can:
- Trigger evaluation pipelines on every commit or model update.
- Automatically block deployments if evaluation scores regress.
- Integrate with container registries, artifact stores, secret managers, and feature stores.
- Standardize evaluation as a testable, production-grade workflow, not just an isolated script.
This makes ZenML ideal for teams who want evaluation to function like software testing: automated, repeatable, and tightly integrated into release processes.
Key Feature 3. Tracking and Lineage
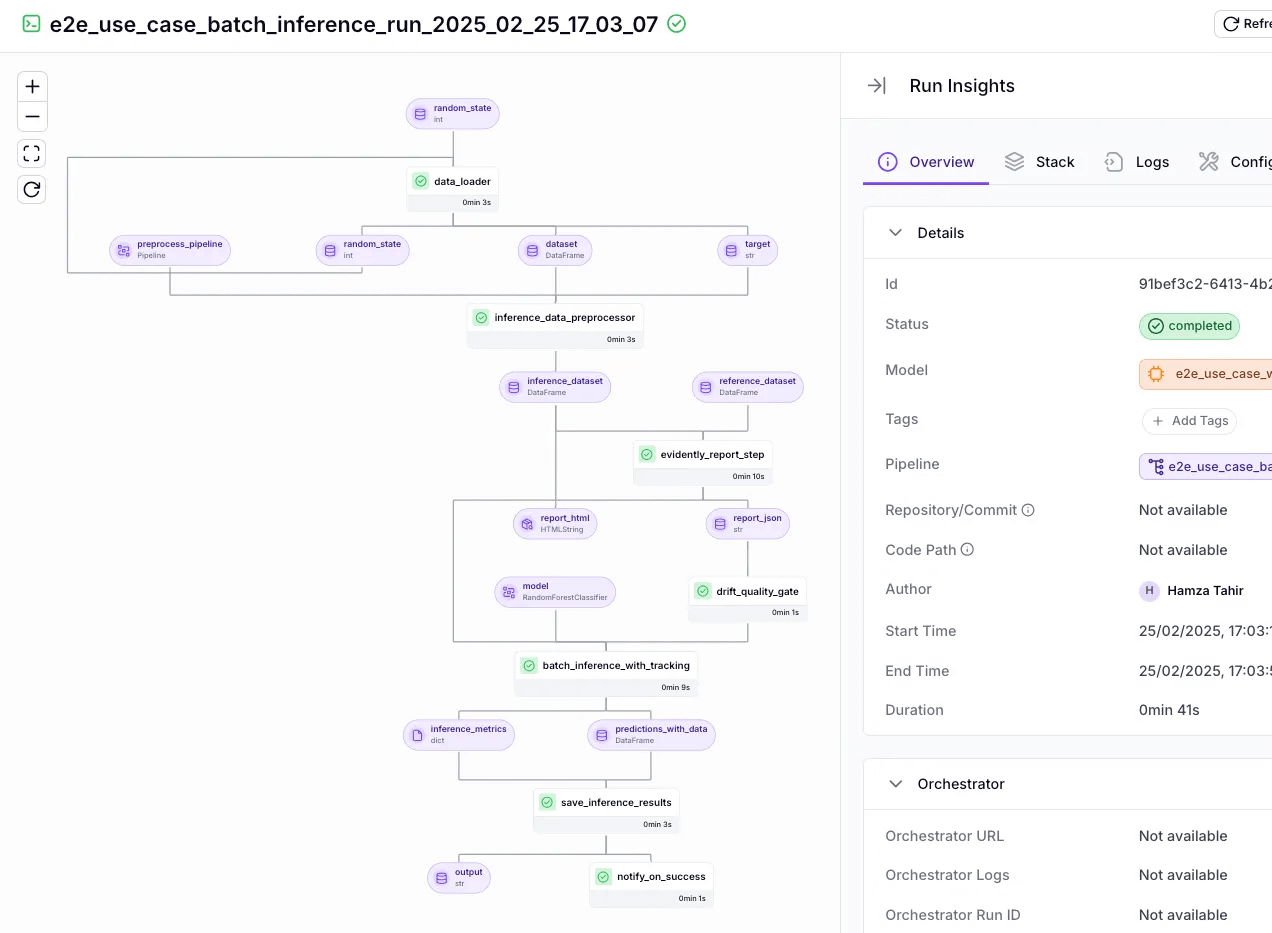
ZenML provides full experiment tracking and lineage across the entire LLM lifecycle - an area where DeepEval lacks coverage.
ZenML automatically tracks:
- Dataset versions
- Prompt versions
- Model versions
- Pipeline runs
- Input/output artifacts
- Metrics from evaluation steps
This lineage ensures complete reproducibility and auditability, making it easy to compare model or prompt variations and identify why a given evaluation score changed.
What’s more, it also enables governance capabilities like traceability, model compliance, and dataset audits.
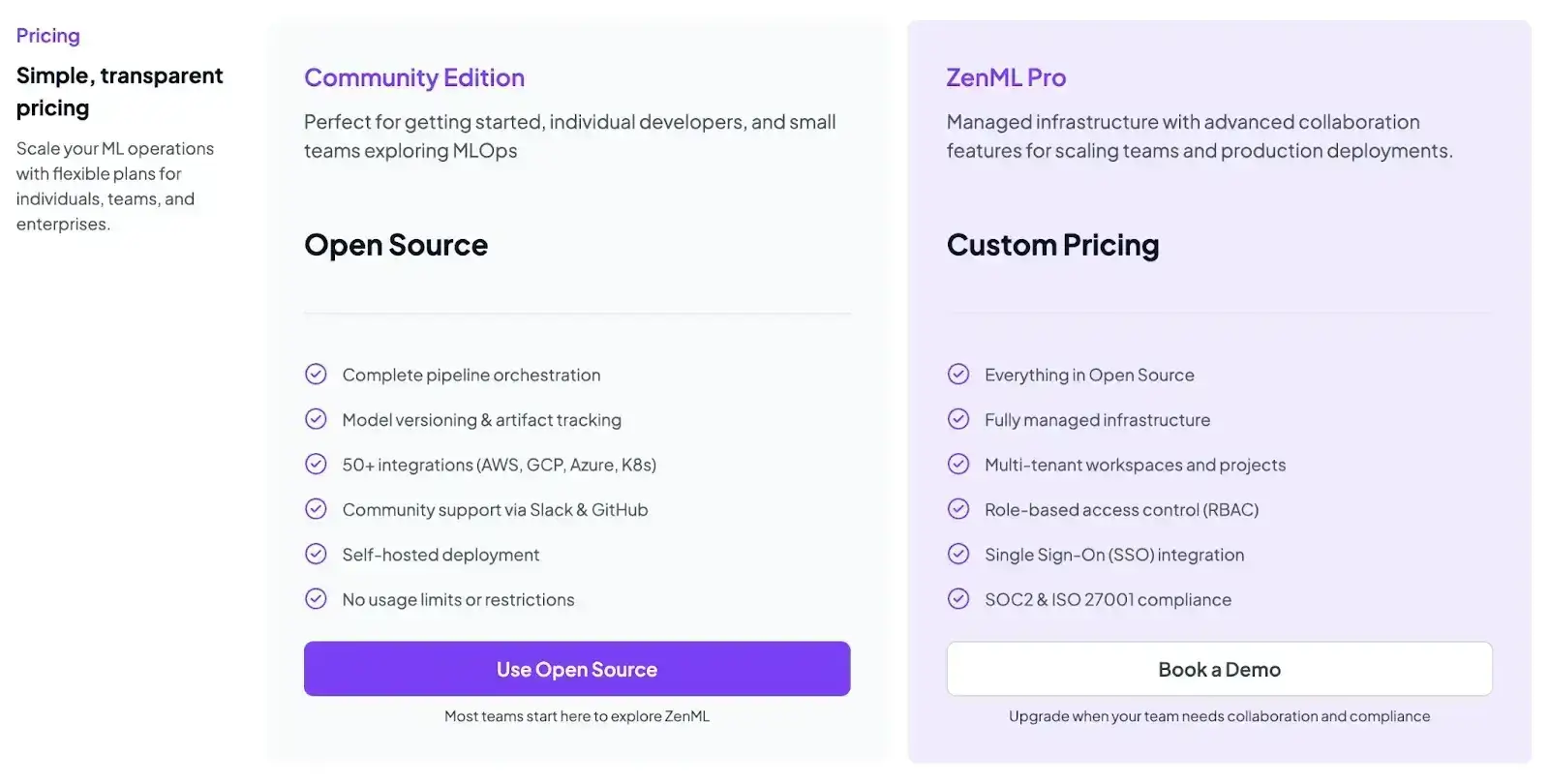
Pricing
ZenML is free and open-source under the Apache 2.0 license. The core framework, dashboard, and orchestration features are fully available at no cost.
For teams requiring enterprise-grade collaboration, managed hosting, advanced security, and premium support, ZenML provides custom business plans. These typically depend on deployment model (cloud or on-premises), usage, or team size.
Pros and Cons
ZenML outshines DeepEval by integrating evaluation directly into reproducible pipelines with full lineage and CI/CD automation. It also offers strong dataset and prompt versioning and supports hybrid metrics for balanced cost and accuracy. Its open-source, self-hosted design makes it ideal for privacy-sensitive teams.
But remember, being a full MLOps framework requires more initial setup than lightweight tools like DeepEval. Teams looking only for a quick Python-based judge metric may find ZenML’s broader workflow approach more comprehensive than they need.
2. Ragas

Ragas is a lightweight, open-source evaluation toolkit purpose-built for RAG pipelines. It offers domain-specific metrics like context relevance, faithfulness, and semantic similarity scoring.
Features
- Score RAG outputs using context precision, recall, faithfulness, and response relevance to pinpoint retrieval or generation failures.
- Combine LLM and classic metrics like BLEU or ROUGE for accurate, semantic evaluations beyond surface-level text match.
- Generate synthetic test cases with question-answer pairs to evaluate pipelines without labeled datasets.
- Integrate into Python workflows with a LangChain-compatible API and simple dataframe inputs.
- Extend with custom metrics by adding your own evaluators and running tests in any script, notebook, or CI job.
Pricing
Ragas is completely free and open-source under the MIT license. You only pay for LLM API calls used by LLM-based metrics, making it the most cost-effective option for RAG evaluation.
Pros and Cons
Ragas is excellent at RAG-specific evaluation. That level of insight is a major advantage over black-box evaluations done by DeepEval. Ragas is also highly extensible and open source, so you can adapt it as needed. Another pro is its simplicity; being code-first, you can integrate it into tests or scripts easily without a new UI to learn.
But keep in mind, Ragas focuses on RAG and isn’t much preferred for general LLM evaluation. If you’re spanning multiple patterns, you must combine Ragas with other evaluation tools.
3. TruLens

TruLens is an open-source framework that provides evaluation and tracing for LLM applications. Rather than DeepEval’s black-box evaluation, TruLens emphasizes explainability through feedback functions. It lets you compose logic from small, reusable feedback functions measuring groundedness, relevance, language match, and custom criteria.
Features
- Log every LLM call and trace nested chains with token usage, latency, and feedback scores across reasoning steps.
- Run built-in evals like groundedness, context relevance, and answer accuracy using LLM-based feedback functions.
- Compare multiple versions of prompts, chains, or models with side-by-side leaderboards and aggregate scores.
- Visualize traces and metrics in a local dashboard to spot failing cases and inspect intermediate outputs.
- Evaluate agent flows by capturing tool calls, sub-prompts, and intermediate reasoning steps in chain-of-thought logic.
Pricing
TruLens is completely free and open-source under the MIT license, with no usage fees or cloud hosting costs.
Pros and Cons
TruLens’s major pro is the rare combination of evaluation + tracing it provides. Many tools do one or the other, but TruLens does both, which means you get the ‘Why’ behind the scores. The local dashboard is a big plus for quick, interactive debugging of LLM behavior, which boosts developer productivity.
Building feedback functions requires more engineering effort than using DeepEval’s LLM-as-a-judge. You write more code defining quality criteria. Additionally, DeepEval lacks a built-in scheduler or database for long-term storage, relying solely on its local usage.
4. Promptfoo
Promptfoo is a lightweight prompt evaluation framework built for fast iteration and regression testing. It’s ideal for developers who want to track prompt quality, benchmark across models, and automate prompt testing in CI, all without complex setup.
Features
- Run prompt tests locally or in CI to validate outputs across models, prompts, or datasets with clear pass/fail results.
- Define test cases declaratively in YAML and compare models side-by-side for variations with diff views and without extensive coding.
- Run automated security scans detecting jailbreaks, prompt injections, and data leakage across models.
- Score generations automatically using exact match, regex, LLM-based, or custom evaluators.
Pricing
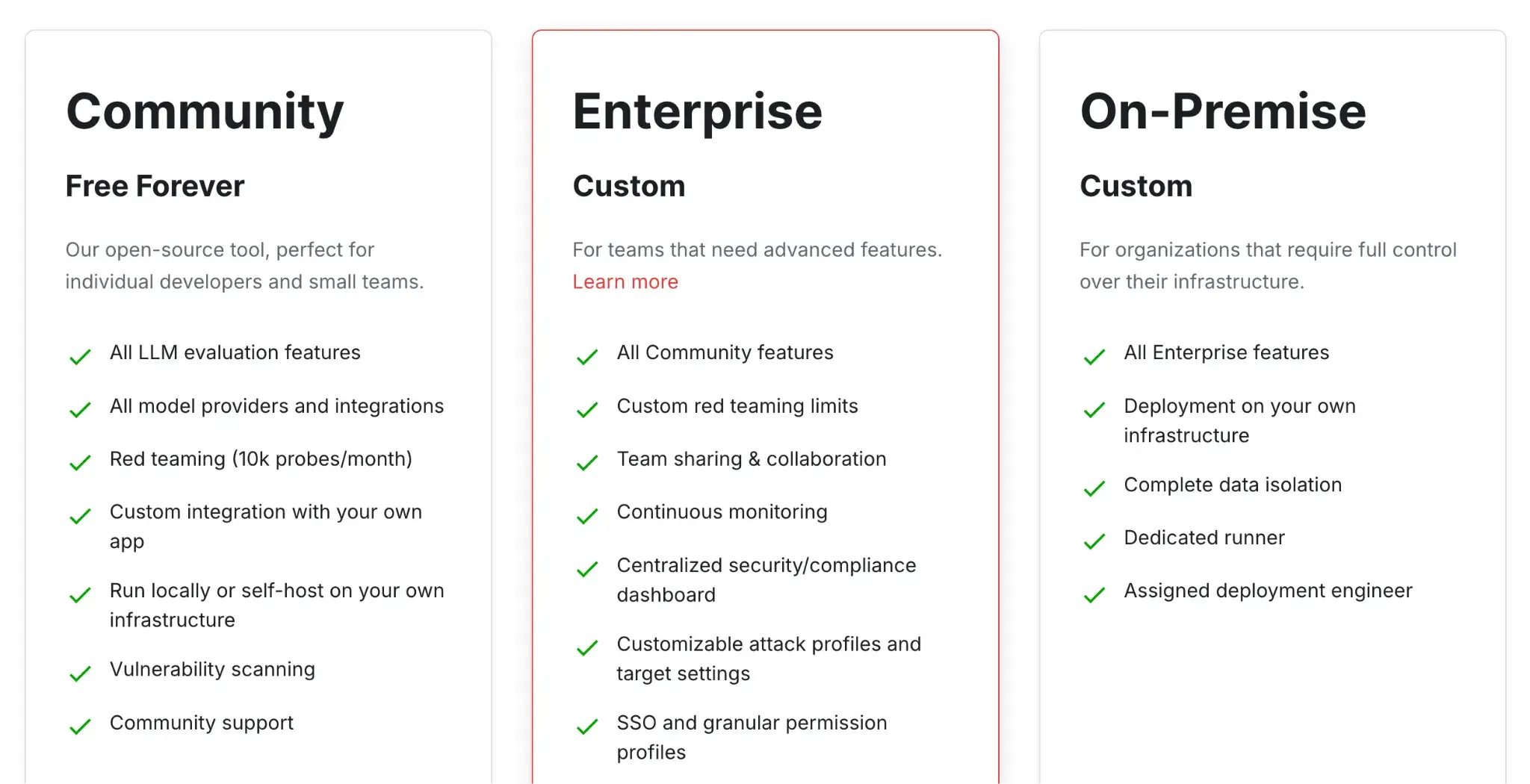
Promptfoo is completely free and open-source under the MIT license. Paid cloud hosting is available for team collaboration and result sharing.
Pros and Cons
Promptfoo is great for prompt engineers and devs who want no-fuss regression testing and clear test case visibility. Its strength lies in fast, model-agnostic evaluations with a focus on automation and repeatability.
However, it lacks deeper observability features like session tracking or UI-based prompt management. More of the reason why it’s better suited for smaller apps or early-stage LLM workflows.
5. Arize Phoenix
Arize Phoenix is an open-source observability platform from Arize AI. It captures traces through OpenTelemetry, enabling you to debug agent behavior, perform what-if analysis, and evaluate quality across runs. Its trace-first approach allows for quicker debugging visibility for complex LLM systems.
Features
- Log every LLM call with OpenTelemetry-based traces to capture nested tool usage, latency, and full multi-step flows.
- Run LLM-based evals on response quality, context relevance, and hallucinations using built-in or custom metrics.
- Track prompt experiments by comparing model versions or prompt changes across versioned datasets.
- Test prompts in the playground and replay past traces with edits to iterate quickly and A/B test variations.
- Inspect outputs visually in a local dashboard with filters, annotations, and detailed input/output breakdowns.
Pricing
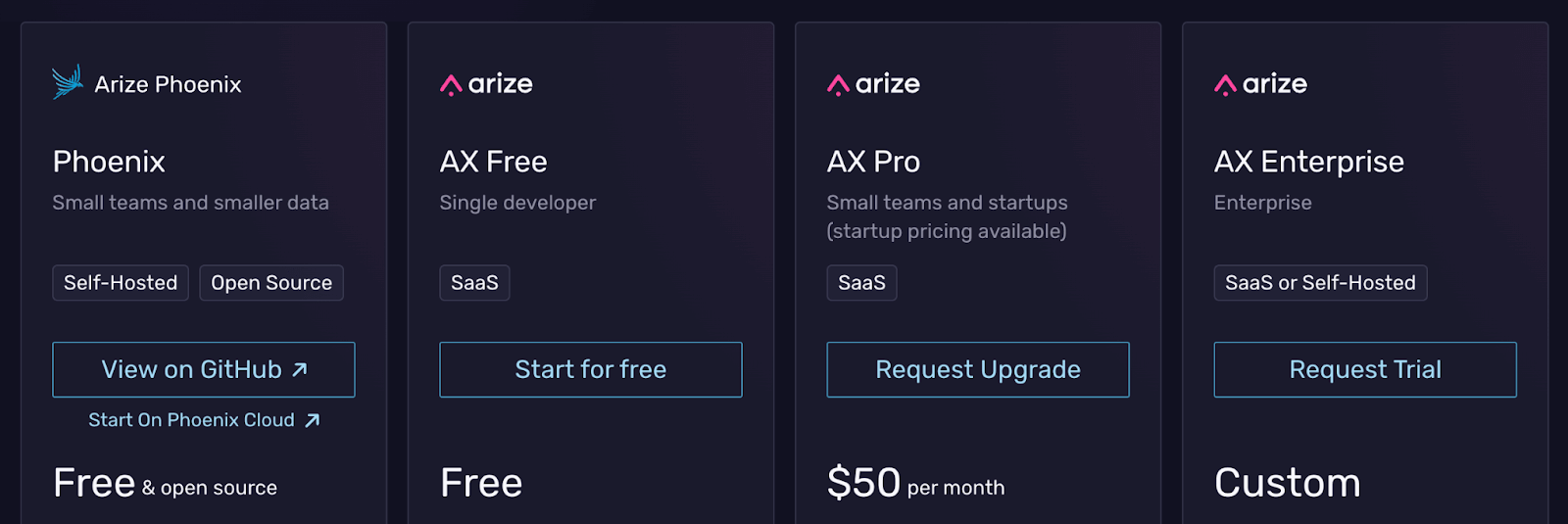
Arize Phoenix is free to self-host with no limit on the number of users. On top of that, it offers a free SaaS (cloud-hosted) plan for solo developers, and two paid plans:
- AX Pro: $50 per month
- AX Enterprise: Custom pricing
Pros and Cons
Phoenix’s strength is trace-first observability. If you need step-by-step visibility into your LLM app, Phoenix is great for it. OpenTelemetry foundation ensures cross-framework compatibility. Plus, it’s framework-agnostic and integrates well with LangChain, LlamaIndex, and others, making it easy to slot into most LLM stacks.
But Phoenix is observability-focused, not evaluation-focused. You get traces and debugging, but not pre-built evaluation metrics. Integrating RAGAS or safety checks requires separate tools. Phoenix lacks dataset management or prompt versioning, making it one component of a complete solution.
6. Langfuse
Langfuse is an open-source LLM engineering platform that directly competes in the space of LangSmith and Phoenix. It helps teams trace, evaluate, and manage prompts for LLM applications.
Features
- Trace all LLM calls, including nested calls, with automatic token counting and cost calculation across different model providers.
- Version and manage prompts independently from code with version-controlled templates and rollout tracking.
- Run automated evals using LLM-based or rule-based metrics like accuracy, cost, groundedness, or latency thresholds.
- Collaborate on traces by sharing, commenting, and labeling sessions directly in the Langfuse UI.
- Support multi-modal traces, including text, images, and audio, for better observability.
Pricing
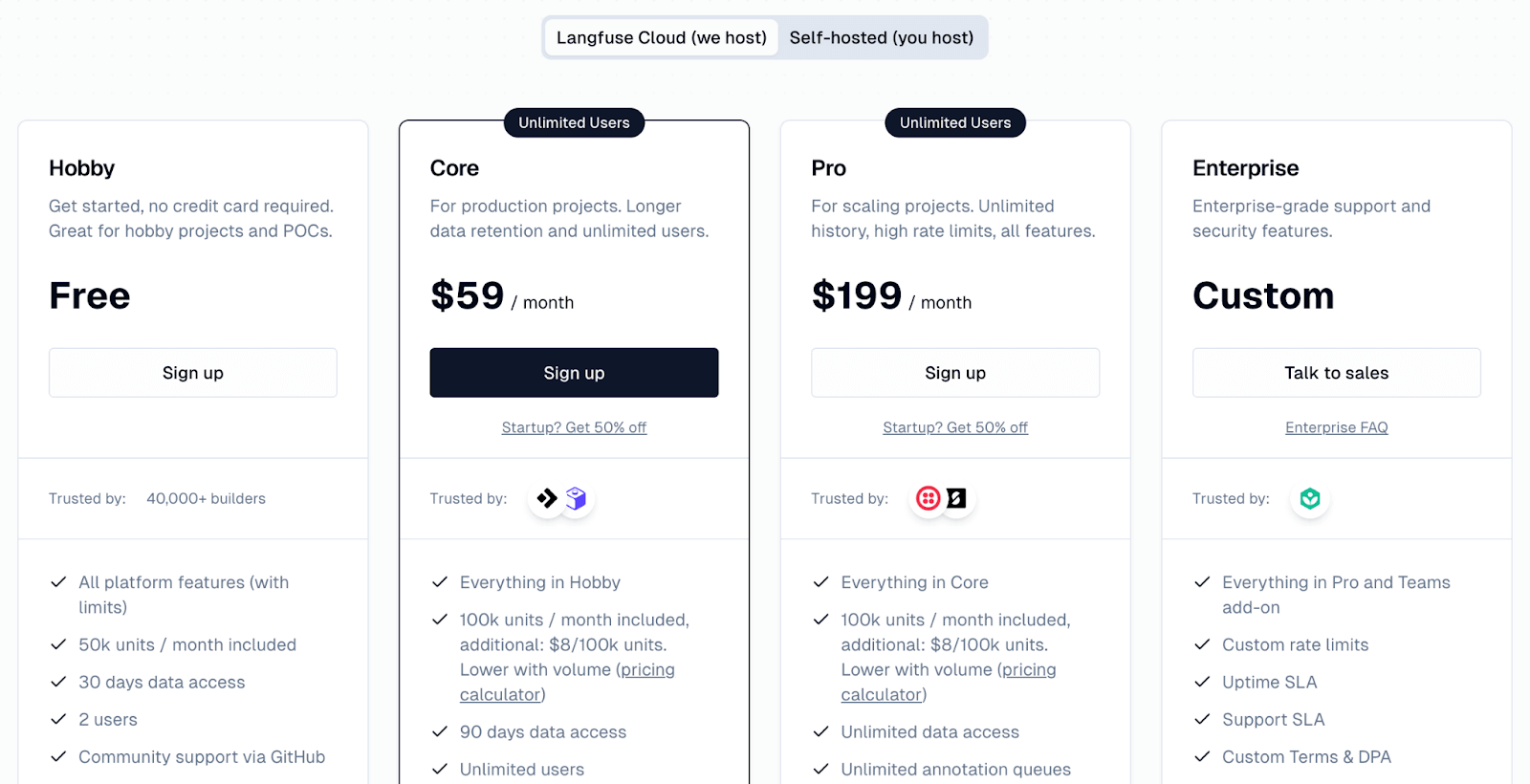
Langfuse is free to use and open-source for self-hosting. Langfuse Cloud offers a free Hobby tier and three paid plans:
- Core: $29 per month
- Pro: $199 per month
- Enterprise: $2499 per month
Pros and Cons
Langfuse combines trace-level visibility with evaluation tools in a beautiful UI. It’s open-source, easy to self-host, and includes versioned prompt tracking and collaborative debugging, too. Besides, DeepEval integration lets you use Langfuse’s tracing with DeepEval metrics.
The framework focuses primarily on the LLM layer, so it doesn’t cover full ML pipelines or training workflows. You’re layering tools for an all-in-one evaluation and tracing solution. You need to integrate multiple libraries rather than using one unified framework. This also makes the initial setup heavier than simpler tools like DeepEval.
7. UpTrain
UpTrain is an open-source observability and evaluation tool built for monitoring LLM outputs in production. It excels at automated quality checks, drift detection, and root-cause analysis across chatbot and RAG workflows.
Features
- Choose from 20+ pre-built metrics, including context relevance, accuracy, hallucination detection, and custom critique-based scoring.
- Run automated evals using LLMs, logic rules, or classifier-based checks to score response quality and safety.
- Create custom Python evaluation operators for domain-specific checks without rebuilding from scratch.
- Track performance drift with outlier and distribution shift detection on both input and output features.
- Visualize test failures and segment them by model, prompt, use case, or user feedback signals.
Pricing
UpTrain is completely free and open-source, with enterprise offerings available upon request for advanced features or support.
Pros and Cons
UpTrain is built for teams that want customizable evaluations and monitoring without relying solely on LLM-as-a-judge. It supports a hybrid eval strategy and is known for surfacing regressions, safety violations, or behavioral drifts over time. Its architecture is developer-first, and it works well for both chat-based and RAG pipelines.
UpTrain has less community adoption than DeepEval, meaning fewer examples and integrations available. While comprehensive, it remains RAG and agent-focused, offering less flexibility for highly custom evaluation logic like TruLens provides.
8. LangSmith
LangSmith is LangChain’s commercial observability platform. It’s a managed SaaS platform developed by the LangChain team. It’s deeply integrated with the LangChain ecosystem and designed to track prompts, sessions, and evaluation signals across development and production environments.
Features
- Log every LLM call with detailed spans, inputs, outputs, errors, and nested tool usage for complete traceability.
- Version prompts and chains to run reproducible experiments and compare output quality over time.
- Run feedback-based evals using LLM, human, or rule-based scoring to analyze accuracy, relevance, and safety.
- Explore traces and metrics in an interactive UI that supports filtering, tagging, and multi-turn debugging.
- Integrate with LangChain directly for zero-config setup across agents, chains, and tools.
Pricing
Langsmith offers a free developer plan and two paid plans:
- Plus: $39 per seat per month
- Enterprise: Custom pricing

Pros and Cons
LangSmith’s biggest pro is its plug-and-play observability option for teams already invested in LangChain. Its UI is highly polished and easy to use. The managed service handles infrastructure and scaling automatically, reducing operational burden.
However, being a managed SaaS platform comes with tradeoffs. Pricing scales with trace volume, and there’s no open-source self-hosting option, except for the enterprise plan. Governance and data privacy are also concerns for regulated industries.
The Best DeepEval Alternatives for LLM Observability
Each of these DeepEval alternatives addresses a unique challenge of LLM evaluation and observability. So the best choice depends on your priorities. Here are our recommendations:
- For teams focused on RAG evaluation, Ragas offers the most targeted metric suite with lower costs than LLM-as-judge approaches.
- For those needing an explainable evaluation, TruLens provides a transparent feedback function framework where every decision is auditable.
- For teams wanting unified MLOps and LLMOps with evaluation in pipelines, ZenML provides end-to-end orchestration and reproducibility.
📚 Relevant alternative articles to read:
Take your AI agent projects to the next level with ZenML. We have built first-class support for agentic frameworks (like CrewAI, LangGraph, and more) inside ZenML, for our users who like pushing boundaries of what AI agents can do. With ZenML, you can seamlessly integrate whichever agent framework you choose into robust, production-grade workflows.


