
On this page
Last updated: November 14, 2022.
Whether you are a data scientist or a machine learning engineer, nothing quite beats the feeling of seeing your model perform well on a test set. It’s the culmination of many coffee-infused hours of work, trial-error iterations and the occasional curse word. Those endorphins are well-earned, albeit short-lived.
The performance of your model doesn’t have to share the same fate as your neuropeptide levels as it hits the harsher conditions of the real world in production. All you need is some good old-fashioned test automation to keep your model in good shape after it’s been deployed.
In this article, I introduce Deepchecks, an open-source Python library for data and model validation that can be easily integrated into your ZenML pipelines to implement continuous testing and monitoring of your workflows. The article includes a full end-to-end example that shows just how simple it is to combine Deepchecks and ZenML. Going through the exercise will give you a glimpse of how to use automated data and model validation to not only build better models but also to reduce the operational overhead of maintaining them long after their first deployment.
Who Wants To Do Testing Anyway?
If developers could be honest about implementing automated tests (via giphy)
Test automation is a common practice in software engineering, but it’s usually something that people don’t enjoy doing as much as they enjoy working on the product itself. I happen to share that sentiment and I have yet to meet someone who would rather spend time coding tests instead of features.
Having made the transition to ML with a software engineering background, I can also confirm that having to do test automation for machine learning doesn’t get easier. To put it bluntly, ML models, especially those used in deep learning, are statistical black boxes. You can’t break a model into smaller units and test them individually and you can only make statistical assumptions about the model’s behavior.
Have I put you off ML test automation yet? I hope not, because that is not my intention. In fact, I’m here to tell you that it’s not all doom and gloom. These pains are well understood in the ML community and some emerging tools are already doing a great job to address them. Deepchecks is one of these new tools and I will argue in this article that it has one of the best approaches I’ve seen in this problem space.
Why Deepchecks?
Before going into detail, I’ll say this about Deepchecks: it makes implementing automated testing for ML seem like less of a chore. Deepchecks is more than what you would expect from a traditional testing framework. It comes fully packed with up-to-date ML validation best practices and out-of-the-box batteries of default tests that you can simply plug into your existing ML pipelines. This allows you to start incorporating automated testing early into your workflow and gradually build up your test suites as you go.
The part that I find incredibly useful is that Deepchecks test results are presented in a format that is readable and comprehensible by humans, accompanied by carefully crafted interpretations that makes it easy even for the uninitiated to understand what went wrong and how to fix it. This is showcased in the hands-on part of this article.
Even noobs can brag about using Deepchecks (via GIPHY)
The other thing that I like about Deepchecks, and this will also appeal to you if you have some experience with traditional DevOps, is that it takes a methodical approach to ML testing. I’ve seen too many tools trying to blindly apply traditional software development practices to the ML domain and completely ignore the fact that ML is fundamentally different. Deepchecks is on the completely opposite end of the spectrum. It takes a step back and looks at the problem from a fresh perspective. Rather than trying to fit a square peg into a round hole, it redefines both the peg and the hole to fit the real problem.
But don’t take my word for it, go check out some of the amazing Deepchecks blog posts to get a glimpse into the thought process that goes into the project.
If I had to pick something that could be improved about Deepchecks, it would be the fact that it is currently not easy to configure tests in a declarative manner. Every check has a list of conditions the parameters of which can be tweaked to customize the test, but the check doesn’t provide a way to specify these condition parameters as a dictionary or something similar. Instead, you have to call each condition method separately and pass them as keyword arguments. This is not a big deal if you are using Deepchecks on its own, but in the context of running pipelines the separation of configuration from execution is key to reusability, provenance and lineage.
The Deepchecks ZenML Integration
The process of integrating a new tool with ZenML can usually be described as fitting it into one of the existing ZenML concepts and abstractions. Deepchecks was a bit of a special case in that regard. Its design is so innovative that we decided to change the way we think about ML validation in ZenML to accommodate it instead. This is now reflected in the Deepchecks Data Validator abstraction and the built-in data and model validation pipeline steps shipped with ZenML.
The Deepchecks Data Validator
The Data Validator is a type of ZenML stack component that was recently introduced to commonly represent the category of tools and processes used in model and data profiling and validation. I briefly mentioned the Data Validator in my previous article on integrating Great Expectations with ZenML.
ZenML now also features a Deepchecks Data Validator that needs to be added as a component to your ZenML stack to use Deepchecks in your pipelines, e.g.:
zenml integration install -y deepchecks
zenml data-validator register deepchecks --flavor=deepchecks
zenml stack update --data_validator deepchecksThe Data Validator is also an abstraction that ZenML is gradually expanding into something that will become a standard interface for all operations related to ML validation that can be used in ML pipelines. The importance of abstractions and interfaces is something that is greatly valued at ZenML because they are what allows us to build a common language for portable and reproducible pipelines on top of a wide range of different tools used in the ML lifecycle.
With the Deepchecks integration, the Data Validator abstraction was redefined to incorporate the patterns reflected in the Deepchecks API. While this isn’t final and not yet directly accessible to ZenML users, it is an important step in the evolution of the Data Validator abstraction.
Standard Deepchecks Data and Model Validation Pipeline Steps
In accordance with our continued strategy of making it as easy as possible to use new tools in ZenML, the library now also includes builtin pipeline steps that can be plugged into any ZenML pipeline to perform data and model validation with Deepchecks, wherever this is applicable:
- the data integrity check step: use it to run Deepchecks data integrity tests on a single dataset. This step is useful for guarding against data integrity issues (e.g. missing values, conflicting labels, mixed data types etc.) before the data is used as input in other ML processes such as model (re)training, validation or inference.
- the data drift check step: use it to runs Deepchecks data drift checks on two input datasets. The step detects data skew, data drift and concept drift problems by comparing a target dataset against a reference dataset (e.g. feature drift, label drift, new labels etc.). Regularly running this step on new data as it comes in can help you detect data drift issues early and take corrective action before they can impact the performance of your model.
- the model validation check step: runs Deepchecks model performance tests using a single dataset and a mandatory model as input. You would typically use this step after retraining a model to detect if its performance drops below a set of pre-defined metrics (e.g. confusion matrix, ROC, model inference time). The step can also be used to benchmark an existing model against a new dataset.
- the model drift check step: runs Deepchecks model comparison/drift tests using a mandatory model and two datasets as input. Use this step to score a model using two different datasets or slices of the same dataset.
This is an example of adding a Deepchecks data integrity check step to a ZenML pipeline:
from zenml.integrations.deepchecks.steps import (
DeepchecksDataIntegrityCheckStepConfig,
deepchecks_data_integrity_check_step,
)
data_validator = deepchecks_data_integrity_check_step(
step_name="data_validator",
config=DeepchecksDataIntegrityCheckStepConfig(),
)The step can be inserted into a pipeline where it can take in a dataset artifact, e.g.:
from zenml.integrations.constants import DEEPCHECKS
from zenml.pipelines import pipeline
@pipeline(required_integrations=[DEEPCHECKS])
def data_validation_pipeline(
data_loader,
data_validator,
):
df_train, df_test = data_loader()
data_validator(dataset=df_train)
pipeline = data_validation_pipeline(
data_loader=data_loader(),
data_validator=data_validator,
)
pipeline.run()The step will run all available Deepchecks data integrity tests on the input dataset and save the results in the Artifact Store, where they can be recalled and visualized with the ZenML visualizer. Of course, the steps are fully customizable in terms of the tests that are run, their parameters and the conditions that can be configured. This is fully covered in the ZenML docs.
Ready to Try It Out?
Pull up your sleeves (via GIPHY)
I reserved the second half of this article for a quick demo of the Deepchecks ZenML integration that showcases the full range of available categories of Deepchecks validations at various points during a model training pipeline:
- data integrity checks on the training dataset
- data drift checks comparing the train and validation dataset slices
- model validation checks on the model and the training dataset
- model performance comparison checks that compare how the model performs on the training vs the validation dataset
A similar, up-to-date version of this example can be accessed in the ZenML GitHub repository.
Setup ZenML
You can run the following to install ZenML on your machine (e.g. in a Python virtual environment) as well as the Deepchecks and scikit-learn integrations used in the example:
pip install zenml["server"]
zenml integration install deepchecks sklearn -y
zenml init
zenml upZenML automatically sets up a default stack that leverages the compute and storage resources on your local machine to run pipelines and record results. You’ll need to add Deepchecks as a Data Validator to this stack or a copy of it to be able to use the Deepchecks builtin steps:
zenml data-validator register deepchecks --flavor=deepchecks
zenml stack copy default deepchecks
zenml stack update deepchecks -dv deepchecks
zenml stack set deepchecksRun a ZenML Deepchecks Data Validation Pipeline
The following code defines a pipeline that trains a scikit-learn model on the Iris dataset. The pipeline also includes Deepchecks data and model validation check steps that are inserted at various points in the pipeline to validate the model and the data being used to train it and evaluate it. The Deepchecks test suite results generated by the validation pipeline run are then visualized in the post-execution phase:
import pandas as pd
from rich import print
from sklearn.model_selection import train_test_split
from sklearn.base import ClassifierMixin
from sklearn.ensemble import RandomForestClassifier
from zenml.integrations.constants import DEEPCHECKS, SKLEARN
from zenml.integrations.deepchecks.visualizers import DeepchecksVisualizer
from zenml.logger import get_logger
from zenml.pipelines import pipeline
from zenml.repository import Repository
from zenml.steps import Output, step
from deepchecks.tabular.datasets.classification import iris
# import the Deepchecks data and model validation step utilities
from zenml.integrations.deepchecks.steps import (
DeepchecksDataIntegrityCheckStepConfig,
deepchecks_data_integrity_check_step,
DeepchecksDataDriftCheckStepConfig,
deepchecks_data_drift_check_step,
DeepchecksModelValidationCheckStepConfig,
deepchecks_model_validation_check_step,
DeepchecksModelDriftCheckStepConfig,
deepchecks_model_drift_check_step,
)
LABEL_COL = "target"
# define the data loader pipeline step
@step
def data_loader() -> Output(
reference_dataset=pd.DataFrame, comparison_dataset=pd.DataFrame
):
"""Load the iris dataset."""
iris_df = iris.load_data(data_format="Dataframe", as_train_test=False)
df_train, df_test = train_test_split(
iris_df, stratify=iris_df[LABEL_COL], random_state=0
)
return df_train, df_test
# define the model training pipeline step
@step
def trainer(df_train: pd.DataFrame) -> ClassifierMixin:
# Train Model
rf_clf = RandomForestClassifier(random_state=0)
rf_clf.fit(df_train.drop(LABEL_COL, axis=1), df_train[LABEL_COL])
return rf_clf
# instantiate and configure the Deepchecks pipeline steps
data_validator = deepchecks_data_integrity_check_step(
step_name="data_validator",
config=DeepchecksDataIntegrityCheckStepConfig(
dataset_kwargs=dict(label=LABEL_COL, cat_features=[]),
),
)
data_drift_detector = deepchecks_data_drift_check_step(
step_name="data_drift_detector",
config=DeepchecksDataDriftCheckStepConfig(
dataset_kwargs=dict(label=LABEL_COL, cat_features=[]),
),
)
model_validator = deepchecks_model_validation_check_step(
step_name="model_validator",
config=DeepchecksModelValidationCheckStepConfig(
dataset_kwargs=dict(label=LABEL_COL, cat_features=[]),
),
)
model_drift_detector = deepchecks_model_drift_check_step(
step_name="model_drift_detector",
config=DeepchecksModelDriftCheckStepConfig(
dataset_kwargs=dict(label=LABEL_COL, cat_features=[]),
),
)
# define the pipeline by connecting the steps together into a DAG
docker_settings = DockerSettings(required_integrations=[DEEPCHECKS, SKLEARN])
@pipeline(enable_cache=False, settings={"docker": docker_settings})
def data_validation_pipeline(
data_loader,
trainer,
data_validator,
model_validator,
data_drift_detector,
model_drift_detector,
):
"""Links all the steps together in a pipeline"""
df_train, df_test = data_loader()
data_validator(dataset=df_train)
data_drift_detector(
reference_dataset=df_train,
target_dataset=df_test,
)
model = trainer(df_train)
model_validator(dataset=df_train, model=model)
model_drift_detector(
reference_dataset=df_train, target_dataset=df_test, model=model
)
if __name__ == "__main__":
# instantiate and run the pipeline
pipeline_instance = data_validation_pipeline(
data_loader=data_loader(),
trainer=trainer(),
data_validator=data_validator,
model_validator=model_validator,
data_drift_detector=data_drift_detector,
model_drift_detector=model_drift_detector,
)
pipeline_instance.run()
# extract and visualize the Deepchecks test suite results
last_run = pipeline_instance.get_runs()[-1]
data_val_step = last_run.get_step(step="data_validator")
model_val_step = last_run.get_step(step="model_validator")
data_drift_step = last_run.get_step(step="data_drift_detector")
model_drift_step = last_run.get_step(step="model_drift_detector")
DeepchecksVisualizer().visualize(data_val_step)
DeepchecksVisualizer().visualize(model_val_step)
DeepchecksVisualizer().visualize(data_drift_step)
DeepchecksVisualizer().visualize(model_drift_step)In order to run this code, simply copy it into a file called run.py and run it with:
python run.pyYou should see the ZenML visualizer kicking in and opening four tabs in your browser, one for each of the Deepchecks test suite results generated by the pipeline steps.
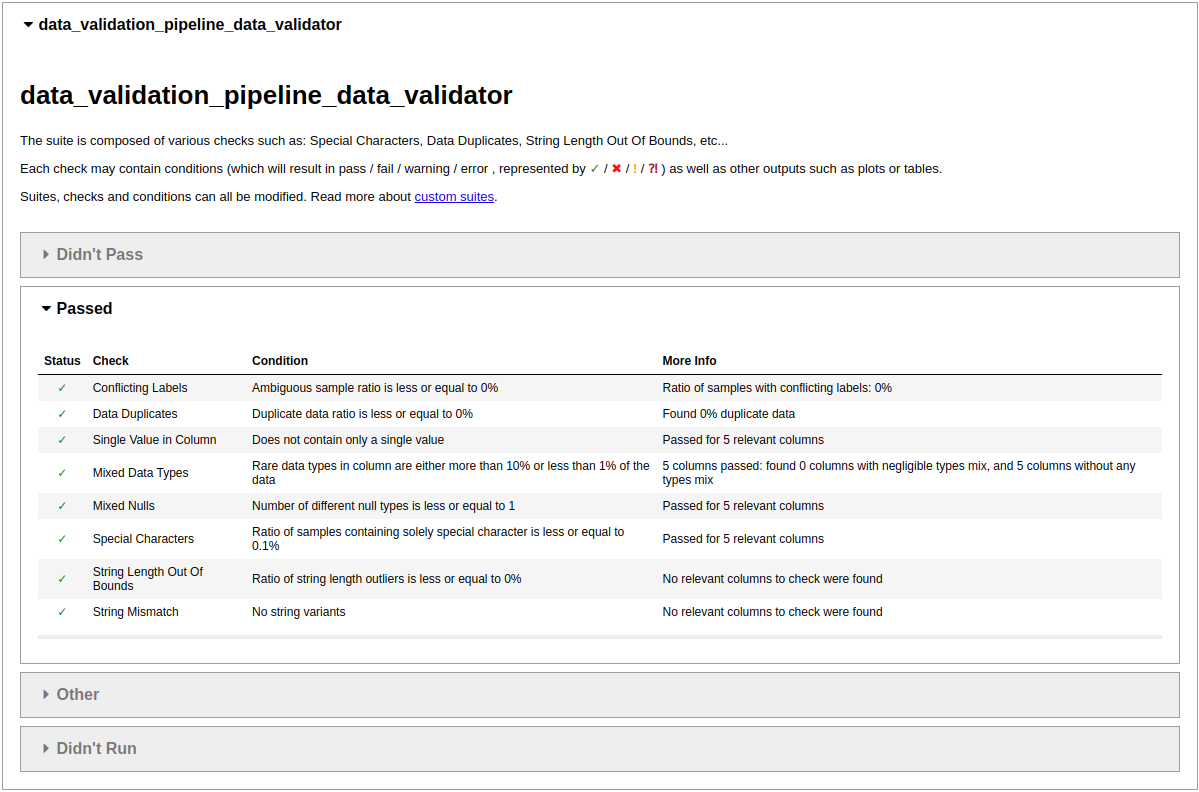
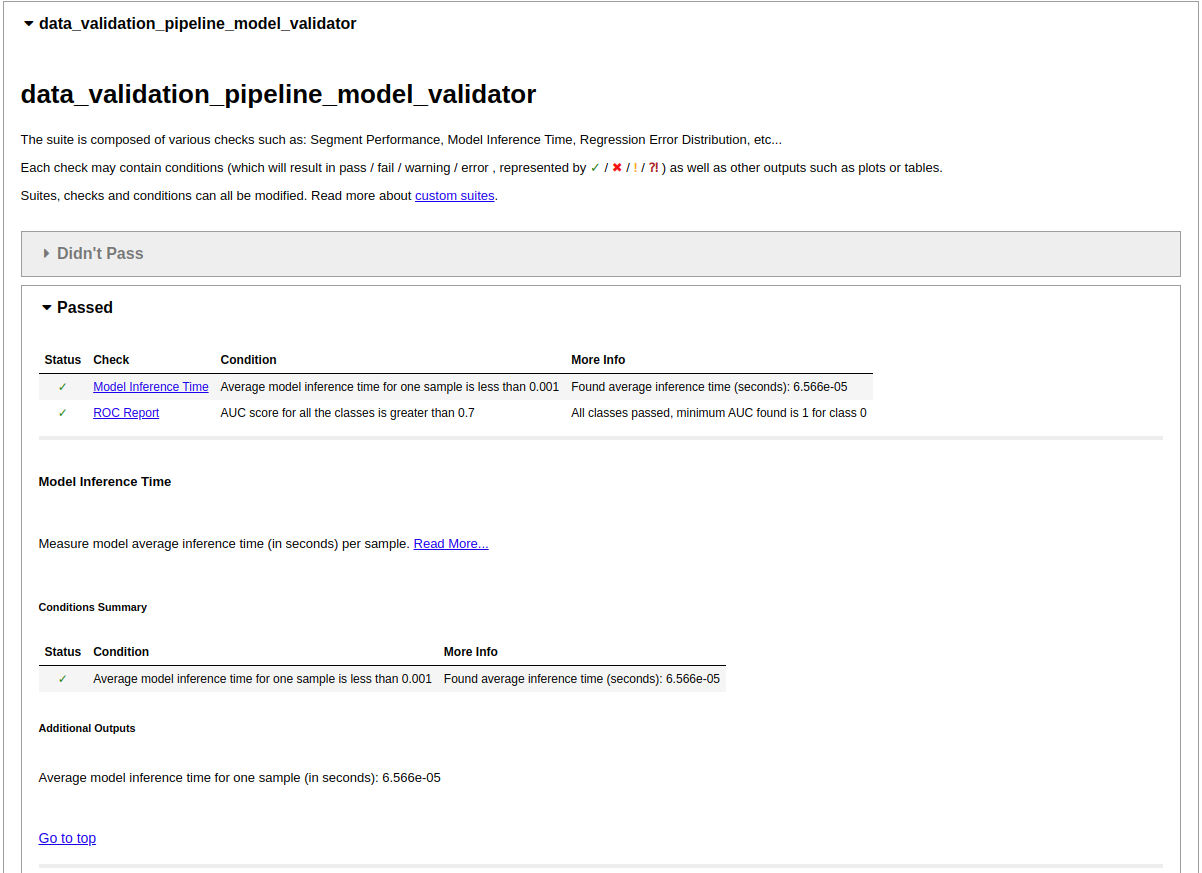
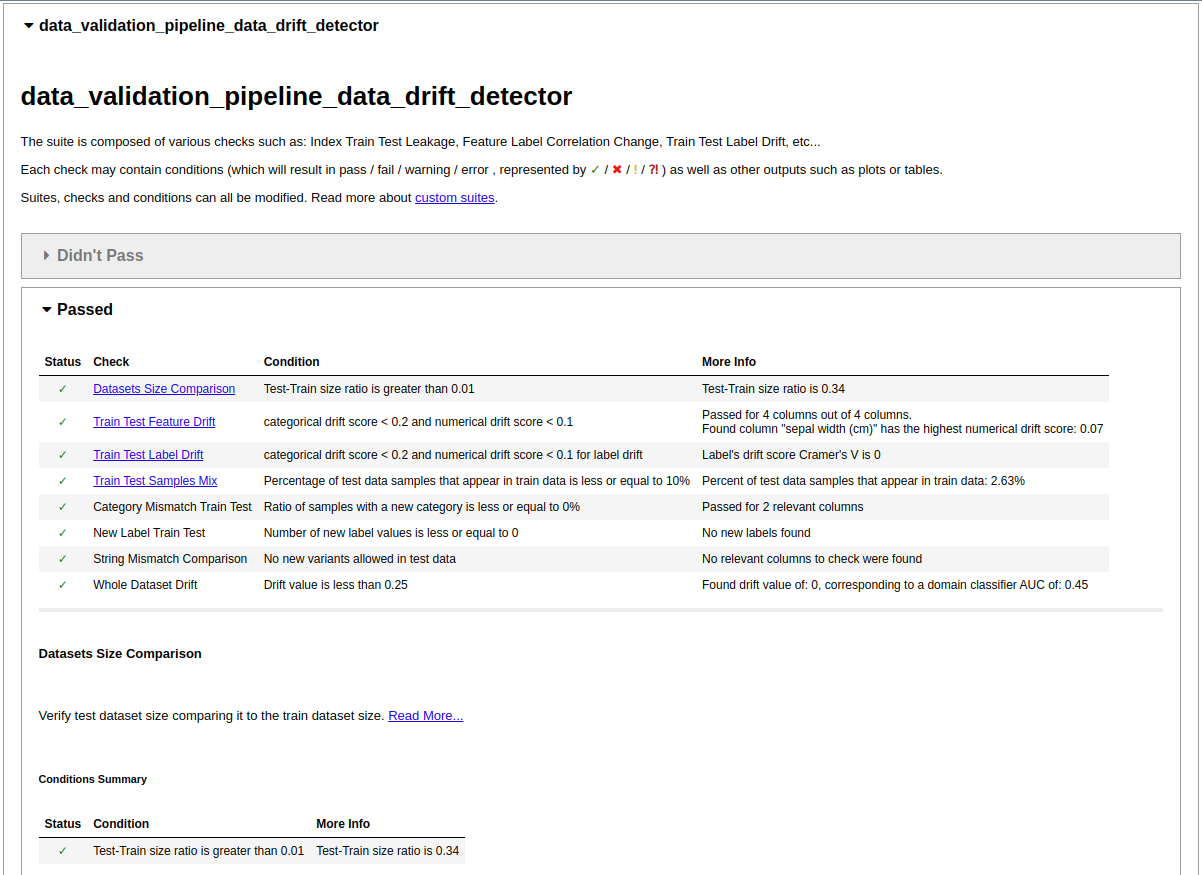
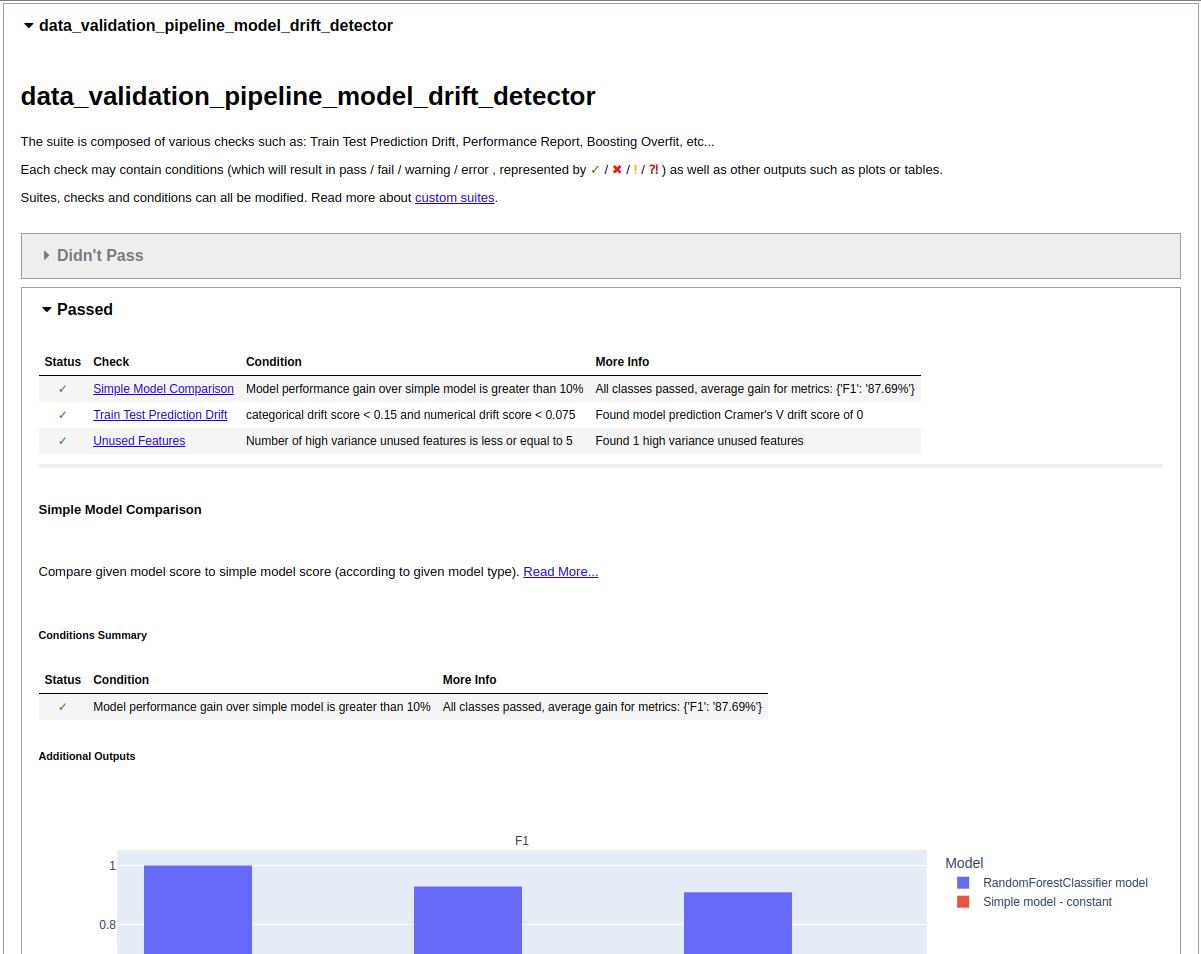
So What Happened Here?
If you successfully installed ZenML and ran the example, you were presented with four tabs in your browser, each containing the results of a Deepchecks test. You may have noticed that aside from indicating the label feature we didn’t really do much in the way of configuration. We simply imported the Deepchecks pipeline steps and instantiated them with the default configuration and yet we got a full set of results from the Deepchecks tests, most of which have passed. This is all possible due to the Deepchecks’ ability to provide sensible defaults for the test suite parameters.
Some tests have failed, however, and this gives me a good opportunity to show you just how great the Deepchecks tests reports really are. My data integrity test run reported a feature label correlation problem. The test report is pretty clear about what the problem is, so I’ll just enclose it here.
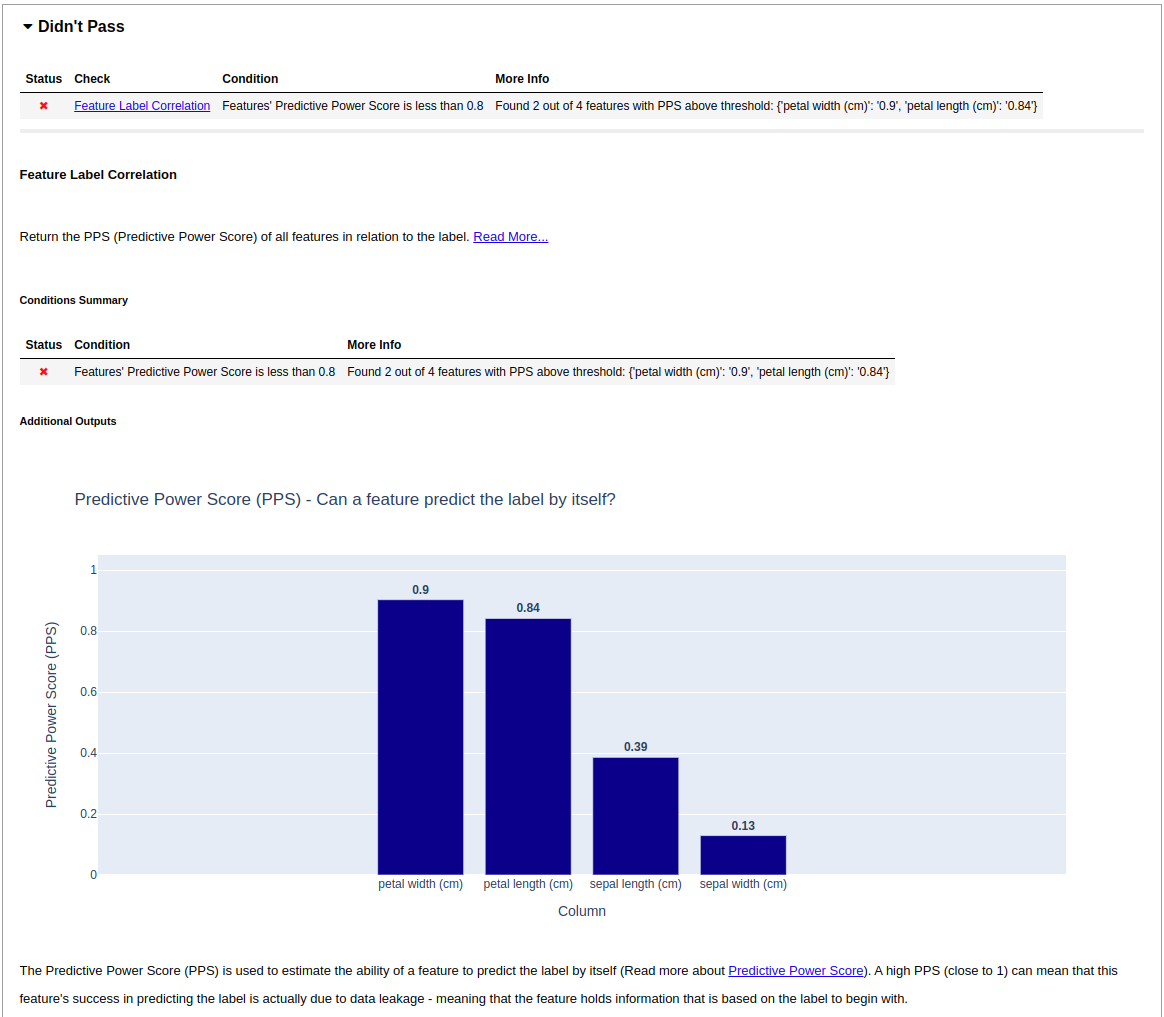
The report tells us that the feature petal width is highly correlated with the target label and can probably be used to predict it on its own. This aspect is also detected in the data drift test, which reports a similar error.
My model drift test also failed because it detected a difference in the performance model on the training dataset compared to the validation datasets.
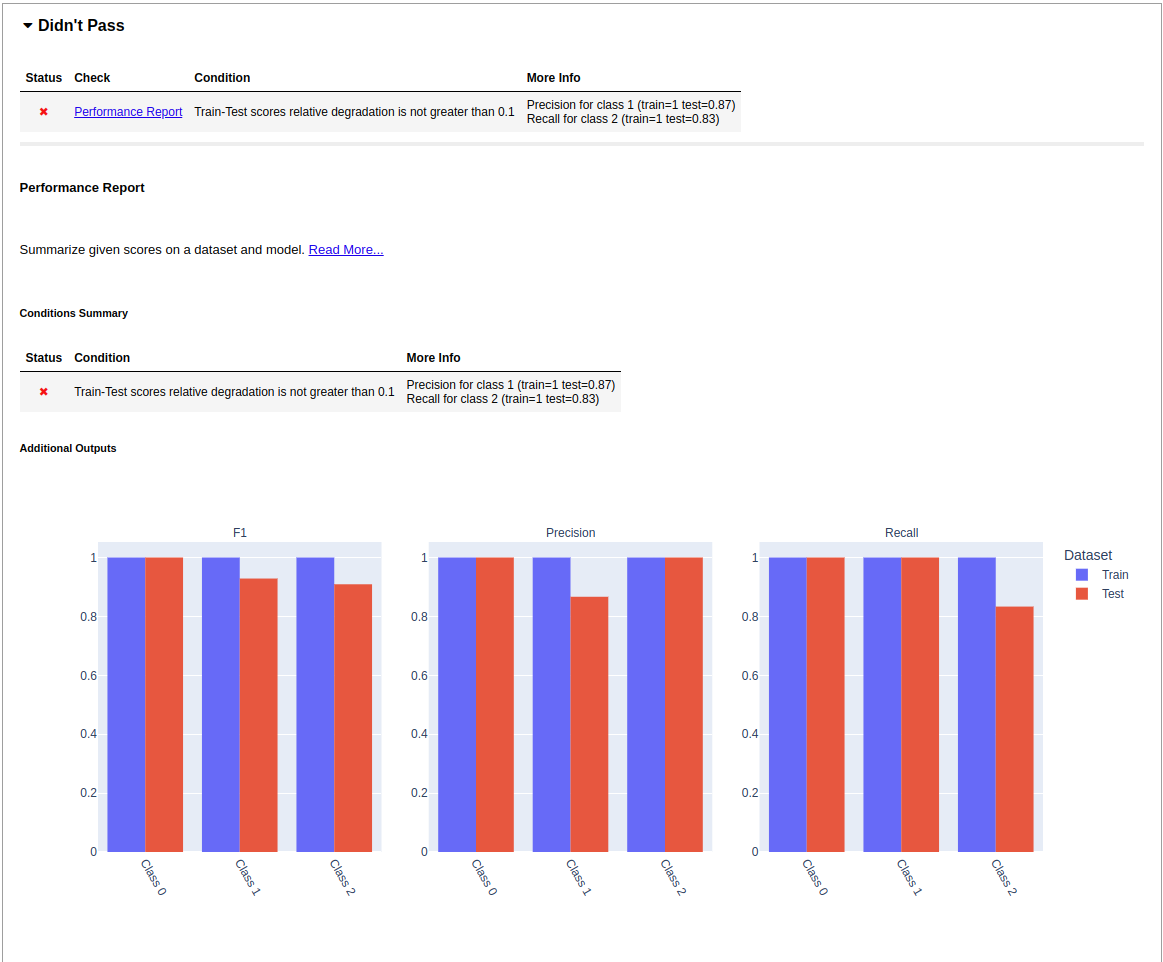
Some of these failures can be silenced by tweaking the test parameters to be less sensitive. The data integrity test can be configured to ignore highly-correlated features and the model drift test can be configured with a higher threshold for the performance difference, as shown here:
from zenml.integrations.deepchecks.validation_checks import (
DeepchecksDataIntegrityCheck,
)
data_validator = deepchecks_data_integrity_check_step(
step_name="data_validator",
config=DeepchecksDataIntegrityCheckStepConfig(
dataset_kwargs=dict(label=LABEL_COL, cat_features=[]),
check_kwargs={
DeepchecksDataIntegrityCheck.TABULAR_FEATURE_LABEL_CORRELATION: dict(
condition_feature_pps_less_than=dict(
threshold=0.91,
)
)
},
),
)
from zenml.integrations.deepchecks.validation_checks import (
DeepchecksModelDriftCheck,
)
model_drift_detector = deepchecks_model_drift_check_step(
step_name="model_drift_detector",
config=DeepchecksModelDriftCheckStepConfig(
dataset_kwargs=dict(label=LABEL_COL, cat_features=[]),
check_kwargs={
DeepchecksModelDriftCheck.TABULAR_PERFORMANCE_REPORT: dict(
condition_train_test_relative_degradation_not_greater_than=dict(
threshold=0.5,
)
)
},
),
)Keep in mind that just because the tests can be reconfigured to silence the failures doesn’t mean they should be. The lesson to be learned here is that Deepchecks tests still need to be tweaked to fit your specific use case.
Wrap-Up
The pipeline featured in this article is just a basic example of what Deepchecks can do for continuous ML validation, but hopefully it is a good starting point for anyone willing to explore the possibilities. Whether you are just starting with ZenML or you are already a seasoned user, adding Deepchecks to the mix is guaranteed to improve the quality of your data and the performance of your models in a way that is easy to understand, explain and maintain.
🔥 Do you use data or model validation tools with your ML pipelines, or do you want to add one to your MLOps stack? At ZenML, we are looking for design partnerships and collaboration to develop the integrations and workflows around using ML validation within the MLOps lifecycle. If you have a use case which requires ML validation in your pipelines, please let us know what you’re building. Your feedback will help set the stage for the next generation of MLOps standards and best practices. The easiest way to contact us is via our Slack community which you can join here.
If you have any questions or feedback regarding the Deepchecks integration or the tutorial featured in this article, we encourage you to join our weekly community hour.
If you want to know more about ZenML or see more examples, check out our docs and examples.

