
Don't make Claude do the same work twice
Claude Agent SDK runs the agent loop. Kitaru adds the durable runtime around a completed invocation — checkpointed results, artifacts, replay boundaries, and waits.

Claude Agent SDK runs the agent loop. Kitaru adds the durable runtime around a completed invocation — checkpointed results, artifacts, replay boundaries, and waits.

LangGraph keeps graph state, threads, and interrupts. Kitaru adds the durable workflow around the graph call — replay boundaries, durable waits, and inspectable runs.

The OpenAI Agents SDK stays the harness; Kitaru adds the runtime around it — durable workflow waits, replay boundaries, and inspectable execution history.
I rebuilt zenml.io — 2,224 pages, 20 CMS collections — from Webflow to Astro in a week using Claude Code and a multi-model AI workflow. Here's how.


Agentic RAG without guardrails spirals out of control. Here's how ZenML's dynamic pipelines give you fan-out, budget limits, and lineage without limiting the LLMs.

ZenML's new Quick Wins skill for Claude Code automatically audits your ML pipelines and implements 15 best-practice improvements (from metadata logging to Model Control Plane setup) based on what's actually missing in your codebase.

ML pipeline scheduling hides complexity beneath simple cron syntax—lessons on freshness, monitoring gaps, and overrun policies from Twitter, LinkedIn, and Shopify.

Analysis of 1,200 production LLM deployments reveals six key patterns separating successful teams from those stuck in demo mode: context engineering over prompt engineering, infrastructure-based guardrails, rigorous evaluation practices, and the recognition that software engineering fundamentals—not frontier models—remain the primary predictor of success.


Explore 419 new real-world LLMOps case studies from the ZenML database, now totaling 1,182 production implementations—from multi-agent systems to RAG.

ZenML's new pipeline deployments feature lets you use the same pipeline syntax to run both batch ML training jobs and deploy real-time AI agents or inference APIs, with seamless local-to-cloud deployment via a unified deployer stack component.

ZenML launches Pipeline Deployments, a new feature that transforms any ML pipeline or AI agent into a persistent, high-performance HTTP service with no cold starts and full observability.

We're expanding ZenML beyond its original MLOps focus into the LLMOps space, recognizing the same fragmentation patterns that once plagued traditional machine learning operations. We're developing three core capabilities: native LLM components that provide unified APIs and management across providers like OpenAI and Anthropic, along with standardized prompt versioning and evaluation tools; applying established MLOps principles to agent development to bring systematic versioning, evaluation, and observability to what's currently a "build it and pray" approach; and enhancing orchestration to support both LLM framework integration and direct LLM calls within workflows. Central to our philosophy is the principle of starting simple before going autonomous, emphasizing controlled workflows over fully autonomous agents for enterprise production environments, and we're actively seeking community input through a survey to guide our development priorities, recognizing that today's infrastructure decisions will determine which organizations can successfully scale AI deployment versus remaining stuck in pilot phases.


Comprehensive analysis of why simple AI agent prototypes fail in production deployment, revealing the hidden complexities teams face when scaling from demos to enterprise-ready systems.

Lessons from the Maven Evals course are combined with 50+ real-world case studies from ZenML's LLMOps Database to show how companies like Discord, GitHub, and Coursera implement the Three Gulfs model and Analyze-Measure-Improve lifecycle to transform failing LLM systems into production-ready applications.

287 latest curated summaries of LLMOps use cases in industry, from tech to healthcare to finance and more. This blog also highlights some of the trends observed across the case studies.

ZenML's new DXT-packaged MCP server transforms MLOps workflows by enabling natural language conversations with ML pipelines, experiments, and infrastructure, reducing setup time from 15 minutes to 30 seconds and eliminating the need to hunt across multiple dashboards for answers.

Learn how to build production-ready agentic AI workflows that combine powerful research capabilities with enterprise-grade observability, reproducibility, and cost control using ZenML's structured approach to controlled autonomy.

Future-proof your ML operations by building portable pipelines that work across multiple platforms instead of forcing standardization on a single solution.

Discover how to optimize GPU utilization in Kubernetes environments by integrating NVIDIA's KAI Scheduler with ZenML pipelines, enabling fractional GPU allocation for improved resource efficiency and cost savings in machine learning workflows.

Explores how energy companies can leverage ZenML's MLOps framework to meet Ofgem's regulatory requirements for AI systems, ensuring fairness, transparency, accountability, and security while maintaining innovation in the rapidly evolving energy sector.

Learn when to upgrade from open-source ZenML to Pro features with our subway-map guide to scaling ML operations for growing teams, from solo experiments to enterprise collaboration.

Discover how ZenML's Service Connectors solve one of MLOps' most frustrating challenges: credential management. This deep dive explores how Service Connectors eliminate security risks and save engineer time by providing a unified authentication layer across cloud providers (AWS, GCP, Azure). Learn how this approach improves developer experience with reduced boilerplate, enforces security best practices with short-lived tokens, and enables true multi-cloud ML workflows without credential headaches. Compare ZenML's solution with alternatives from Kubeflow, Airflow, and cloud-native platforms to understand why proper credential abstraction is the unsung hero of efficient MLOps.

8 practical alternatives to Kubeflow that address its common challenges of complexity and operational overhead. From Argo Workflows' lightweight Kubernetes approach to ZenML's developer-friendly experience, we analyze each tool's strengths across infrastructure needs, developer experience, and ML-specific capabilities—helping you find the right orchestration solution that removes barriers rather than creating them for your ML workflows.

Our monthly roundup: new features with 0.80.0 release, more new models, and an MCP server for ZenML

We explore how successful LLMOps implementation depends on human factors beyond just technical solutions. It addresses common challenges like misaligned executive expectations, siloed teams, and subject-matter expert resistance that often derail AI initiatives. The piece offers practical strategies for creating effective team structures (hub-and-spoke, horizontal teams, cross-functional squads), improving communication, and integrating domain experts early. With actionable insights from companies like TomTom, Uber, and Zalando, readers will learn how to balance technical excellence with organizational change management to unlock the full potential of generative AI deployments.
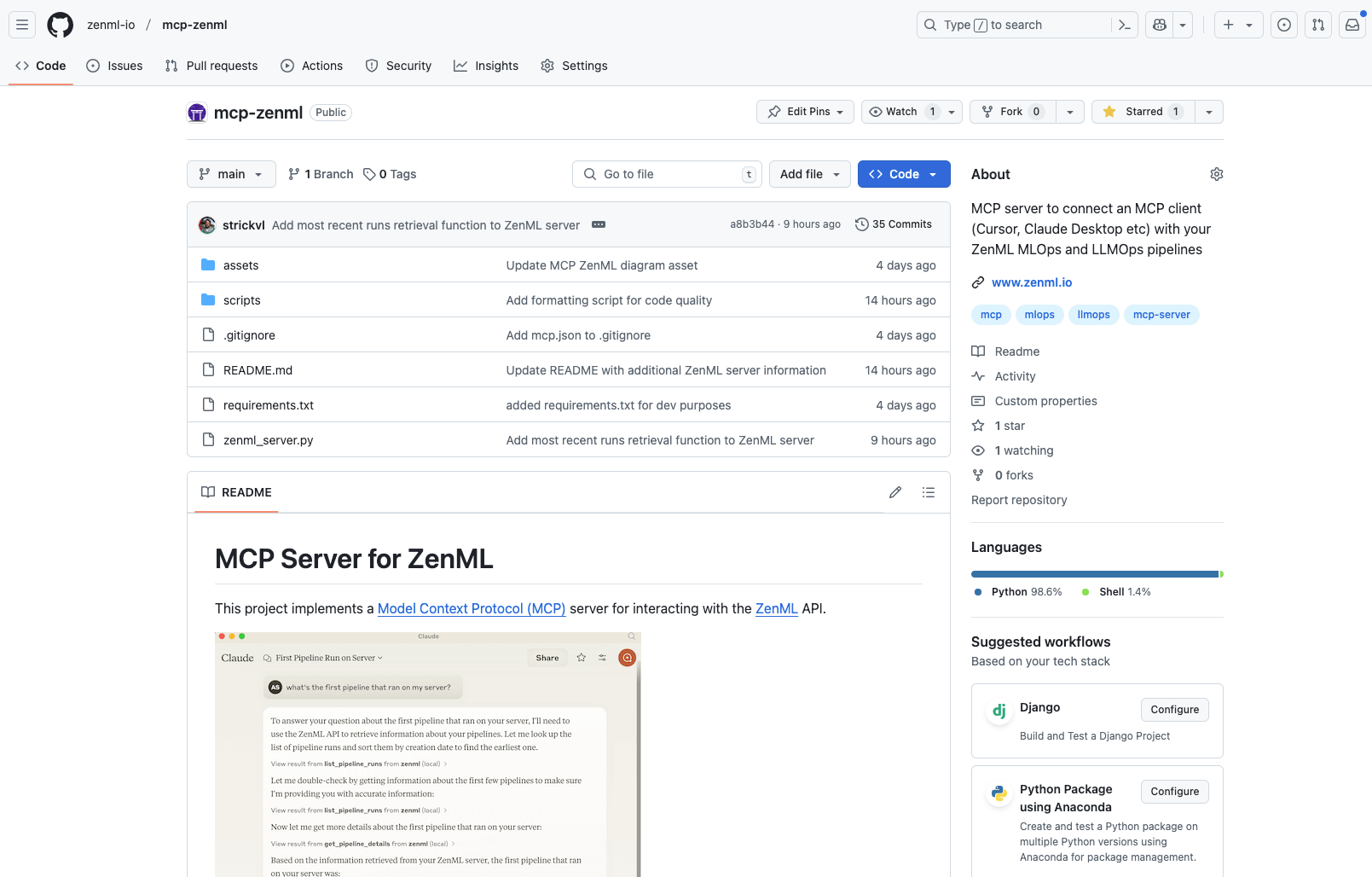
Discover the new ZenML MCP Server that brings conversational AI to ML pipelines. Learn how this implementation of the Model Context Protocol allows natural language interaction with your infrastructure, enabling query capabilities, pipeline analytics, and run management through simple conversation. Explore current features, engineering decisions, and future roadmap for this timely addition to the rapidly evolving MCP ecosystem.
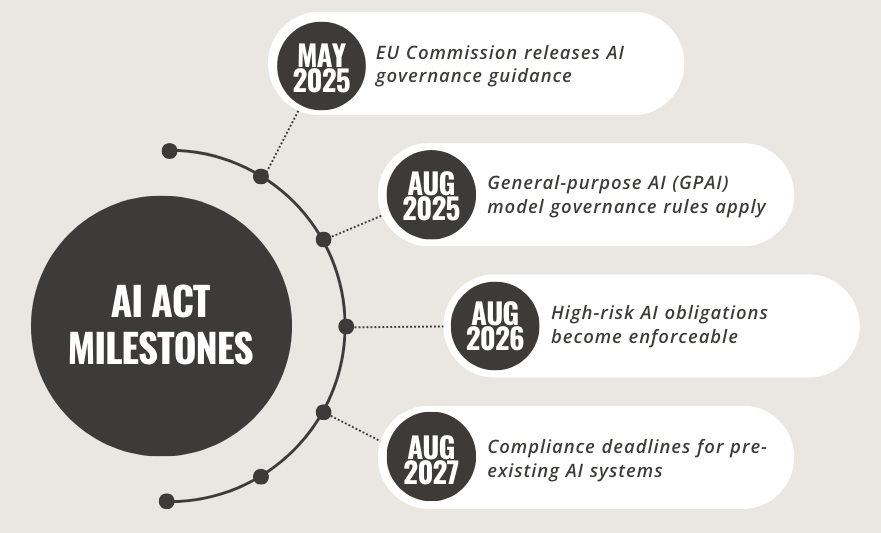
The EU AI Act, now partially in effect as of February 2025, introduces comprehensive regulations for artificial intelligence systems with significant implications for global AI development. This landmark legislation categorizes AI systems based on risk levels - from prohibited applications to high-risk and limited-risk systems - establishing strict requirements for transparency, accountability, and compliance. The Act imposes substantial penalties for violations, up to €35 million or 7% of global turnover, and provides a clear timeline for implementation through 2027. Organizations must take immediate action to audit their AI systems, implement robust governance infrastructure, and enhance development practices to ensure compliance, with tools like ZenML offering technical solutions for meeting these regulatory requirements.

A comprehensive overview of lessons learned from the world's largest database of LLMOps case studies (457 entries as of January 2025), examining how companies implement and deploy LLMs in production. Through nine thematic blog posts covering everything from RAG implementations to security concerns, this article synthesizes key patterns and anti-patterns in production GenAI deployments, offering practical insights for technical teams building LLM-powered applications.
Learn how leading companies like Dropbox, NVIDIA, and Slack tackle LLM security in production. This comprehensive guide covers practical strategies for preventing prompt injection, securing RAG systems, and implementing multi-layered defenses, based on real-world case studies from the LLMOps database. Discover battle-tested approaches to input validation, data privacy, and monitoring for building secure AI applications.
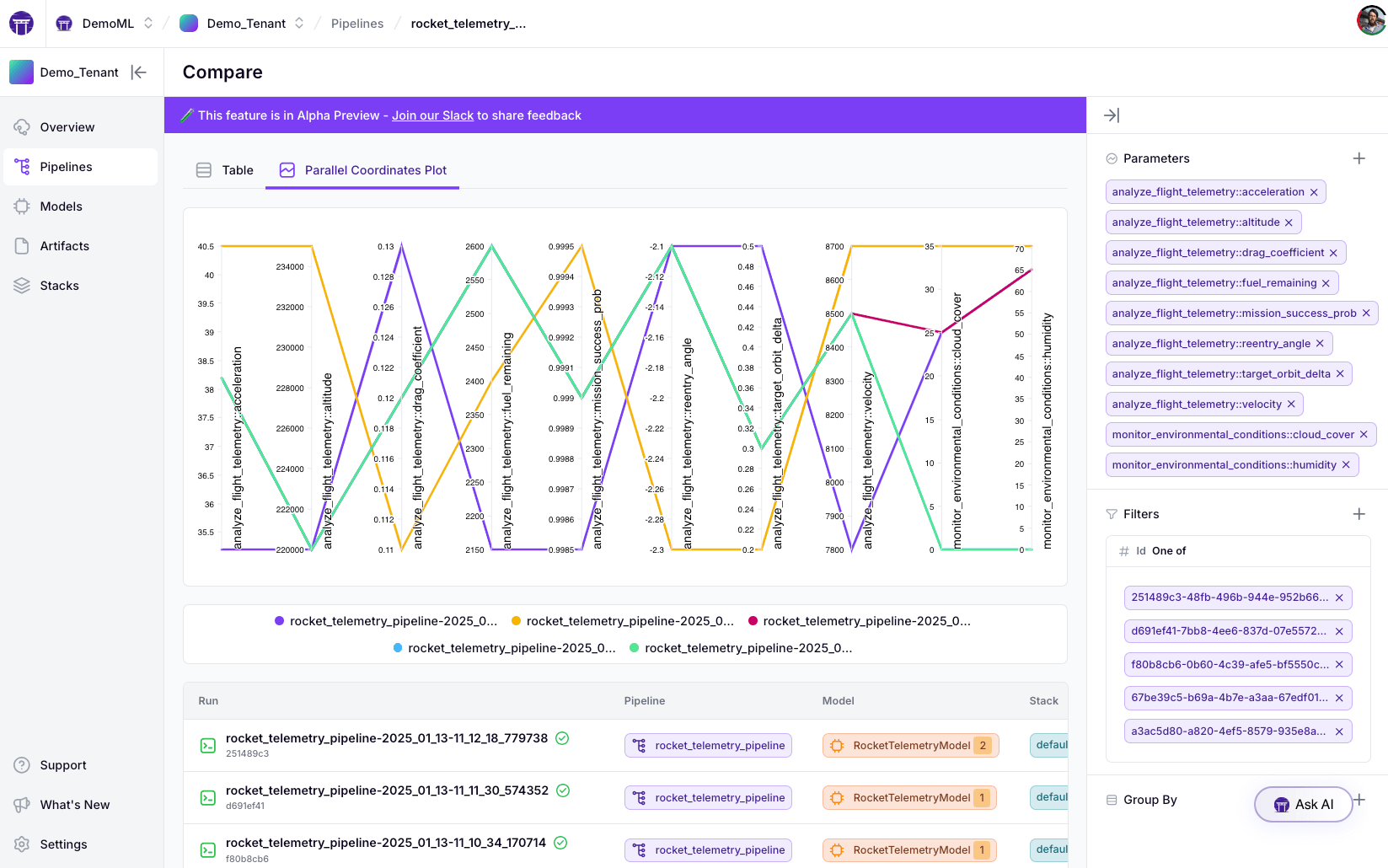
ZenML's new Experiment Comparison Tool brings powerful experiment tracking capabilities to your ML pipelines. Compare up to 20 pipeline runs simultaneously through intuitive tabular and parallel coordinates visualizations, helping teams derive actionable insights from their pipeline metadata. Now available in the Pro tier dashboard.

This comprehensive guide explores strategies for optimizing Large Language Model (LLM) deployments in production environments, focusing on maximizing performance while minimizing costs. Drawing from real-world examples and the LLMOps database, it examines three key areas: model selection and optimization techniques like knowledge distillation and quantization, inference optimization through caching and hardware acceleration, and cost optimization strategies including prompt engineering and self-hosting decisions. The article provides practical insights for technical professionals looking to balance the power of LLMs with operational efficiency.

A comprehensive exploration of real-world lessons in LLM evaluation and quality assurance, examining how industry leaders tackle the challenges of assessing language models in production. Through diverse case studies, the post covers the transition from traditional ML evaluation, establishing clear metrics, combining automated and human evaluation strategies, and implementing continuous improvement cycles to ensure reliable LLM applications at scale.

Practical lessons on prompt engineering in production settings, drawn from real LLMOps case studies. It covers key aspects like designing structured prompts (demonstrated by Canva's incident review system), implementing iterative refinement processes (shown by Fiddler's documentation chatbot), optimizing prompts for scale and efficiency (exemplified by Assembled's test generation system), and building robust management infrastructure (as seen in Weights & Biases' versioning setup). Throughout these examples, the focus remains on systematic improvement through testing, human feedback, and error analysis, while balancing performance with operational costs and complexity.

An in-depth exploration of LLM agents in production environments, covering key architectures, practical challenges, and best practices. Drawing from real-world case studies in the LLMOps Database, this article examines the current state of AI agent deployment, infrastructure requirements, and critical considerations for organizations looking to implement these systems safely and effectively.

Discover how embeddings power modern search and recommendation systems with LLMs, using case studies from the LLMOps Database. From RAG systems to personalized recommendations, learn key strategies and best practices for building intelligent applications that truly understand user intent and deliver relevant results.

Explore real-world applications of Retrieval Augmented Generation (RAG) through case studies from leading companies in the ZenML LLMOps Database. Learn how RAG enhances LLM applications with external knowledge sources, examining implementation strategies, challenges, and best practices for building more accurate and informed AI systems.

The LLMOps Database offers a curated collection of 300+ real-world generative AI implementations, providing technical teams with practical insights into successful LLM deployments. This searchable resource includes detailed case studies, architectural decisions, and AI-generated summaries of technical presentations to help bridge the gap between demos and production systems.

Explore key insights and patterns from 300+ real-world LLM deployments, revealing how companies are successfully implementing AI in production. This comprehensive analysis covers agent architectures, deployment strategies, data infrastructure, and technical challenges, drawing from ZenML's LLMOps Database to highlight practical solutions in areas like RAG, fine-tuning, cost optimization, and evaluation frameworks.

As organizations rush to adopt generative AI, several major tech companies have proposed maturity models to guide this journey. While these frameworks offer useful vocabulary for discussing organizational progress, they should be viewed as descriptive rather than prescriptive guides. Rather than rigidly following these models, organizations are better served by focusing on solving real problems while maintaining strong engineering practices, building on proven DevOps and MLOps principles while adapting to the unique challenges of GenAI implementation.

Machine Learning (ML) adoption is gaining momentum, but challenges include robust pipelines, quality issues, and scale monitoring. Recognizing and overcoming these challenges is crucial.
Master cloud-based LLM finetuning: Set up infrastructure, run pipelines, and manage experiments with ZenML's Model Control Plane for Microsoft's latest Phi model.

Playing around with some genAI services and tools to create a story and comic that showcases the journey of MLOps adoption for a small team.

Master cloud-based LLM finetuning: Set up infrastructure, run pipelines, and manage experiments with ZenML's Model Control Plane for Meta's latest Llama model.
Learn how to leverage caching, parameterization, and smart infrastructure switching to iterate faster on machine learning projects while maintaining reproducibility.
OpenAI's Batch API allows you to submit queries for 50% of what you'd normally pay. Not all their models work with the service, but in many use cases this will save you lots of money on your LLM inference, just so long as you're not building a chatbot!

Context windows in large language models are getting super big, which makes you wonder if Retrieval-Augmented Generation (RAG) systems will still be useful. But even with unlimited context windows, RAG systems are likely here to stay because they're simple, efficient, flexible, and easy to understand.

We released an updated way to deploy MLOps infrastructure, building on the success of the `mlops-stack` repo and its stack recipes. All the new goodies are available via the `mlstacks` Python package.
The 0.40.0 release introduces a completely reworked interface for developing your ZenML steps and pipelines. It makes working with these components much more natural, intuitive, and enjoyable.

We decided to explore how the emerging technologies around Large Language Models (LLMs) could seamlessly fit into ZenML's MLOps workflows and standards. We created and deployed a Slack bot to provide community support.
Getting started with your ML project work is easier than ever with Project Templates, a new way to generate scaffolding and a skeleton project structure based on best practices.

This week I spoke with Emeli Dral, co-founder and CTO of Evidently, an open-source tool tackling the problem of monitoring of models and data for machine learning. We discussed the challenges around building a tool that is both straightforward to use while also customizable and powerful.

I spoke with Karthik Kannan, cofounder and CTO of Envision, a company that builds on top of the Google Glass and using Augmented Reality features of phones to allow visually impaired people to better sense the environment or objects around them.

This week I spoke with Iva Gumnishka, the founder of Humans in the Loop. They are an organization that provides data annotation and collection services. Their teams are primarily made up of those who have been affected by conflict and now are asylum seekers or refugees.

We put together a list of 48 open-source annotation and labeling tools to support different kinds of machine-learning projects.

This week I spoke with Ben Wilson, author of 'Machine Learning Engineering in Action', a jam-backed guide to all the lessons that Ben has learned over his years working to help companies get models out into the world and run them in production.

I explain why data labeling and annotation should be seen as a key part of any machine learning workflow, and how you probably don't want to label data only at the beginning of your process.

This week I spoke with Kush Varshney, author of 'Trustworthy Machine Learning', a fantastic guide and overview of all of the different ways machine learning can go wrong and an optimistic take on how to think about addressing those issues.

This week I spoke with Matt Squire, the CTO and co-founder of Fuzzy Labs, where they help partner organizations think through how best to productionise their machine learning workflows.

This week I spoke with Emmanuel Ameisen, a data scientist and ML engineer currently based at Stripe. Emmanuel also wrote an excellent O'Reilly book called 'Building Machine Learning Powered Applications', a book I find myself often returning to for inspiration and that I was pleased to get the chance to reread in preparation for our discussion.

An exploration of some frameworks created by Google and Microsoft that can help think through improvements to how machine learning models get developed and deployed in production.

This week I spoke with Johnny Greco, a data scientist working at Radiology Partners. Johnny transitioned into his current work from a career as an academic — working in astronomy — where also worked in the open-source space to build a really interesting synthetic image data project.
We recently reworked a number of parts of our CLI interface. Here are some quick wins we implemented along the way that can help you improve how users interact with your CLI via the popular open-source library, rich.

Tristan and Alex discuss where machine learning and AI are headed in terms of the tooling landscape. Tristan outlined a vision of a higher abstraction level, something he's working on making a reality as CEO at Continual.
Use MLflow Tracking to automatically ensure that you're capturing data, metadata and hyperparameters that contribute to how you are training your models. Use the UI interface to compare experiments, and let ZenML handle the boring setup details.
A dive into Python type hinting, how implementing them makes your codebase more robust, and some suggestions on how you might approach adding them into a large legacy codebase.

Mohan and Alex discuss neurosymbolic AI and the implications of a shift towards that as a core paradigm for production AI systems. In particular, we discuss the practical consequences of such a shift, both in terms of team composition as well as infrastructure requirements.
ZenML recently added an integration with Evidently, an open-source tool that allows you to monitor your data for drift (among other things). This post showcases the integration alongside some of the other parts of Evidently that we like.

We discuss how to monitor models in production, and how it helps you in the long-run.

Use caches to save time in your training cycles, and potentially to save some money as well!


We discuss the role of MLOps in an organization, some deployment war stories from his career as well as what he considers to be 'best practices' in production machine learning.

A mix of mental and technical skills you can develop to get better at testing your Python code.