

On this page
For years, Comet earned its place in ML teams by solving a painful problem: experiments were scattered across notebooks, local files, and half-written spreadsheets. Comet brought structure. It gave teams a single interface for logging and comparing runs without digging through code. That visibility made iteration faster and collaboration easier, especially when models moved beyond solo research into shared workflows.
But as evaluation practices mature, Comet struggles with one of these things:
- Inflexible governance controls
- Volume-based limits
- Overwhelming platform work for production self-hosting
That’s why many ML engineers and platform teams look for alternatives that treat evaluation as a first-class, scalable practice. Some want open-source tools they can fully control. Others want cloud-native platforms that handle security and scale by default.
We tried and tested the best Comet alternatives and wrote about the top 9 in this article.
👀 Note: Comet is the company name, and the product lineup includes both Comet MLOps (experiment management) and Opik (GenAI observability and evaluation), which have different pricing models and plan limits.
A Quick Overview of the Best Comet Alternatives
- Why look for alternatives: Comet’s enterprise-only identity and governance features (e.g., SSO and org/project RBAC) plus usage-based limits on some tiers can create friction as evaluation volume and team size grow.
- Who should care: ML and platform engineers and Python developers who run eval suites in CI, compare many model or prompt variants, or must keep eval data inside their own environment.
- What to Expect: A direct comparison of 9 tools, each broken down with evaluation-focused features, official pricing, plus pros and cons drawn from reviews and issue trackers.
The Need for a Comet Alternative?
Teams are migrating away from Comet for three reasons: scale, cost, and infrastructure control.
1. Key Evaluation and Governance Features are Gated to Enterprise
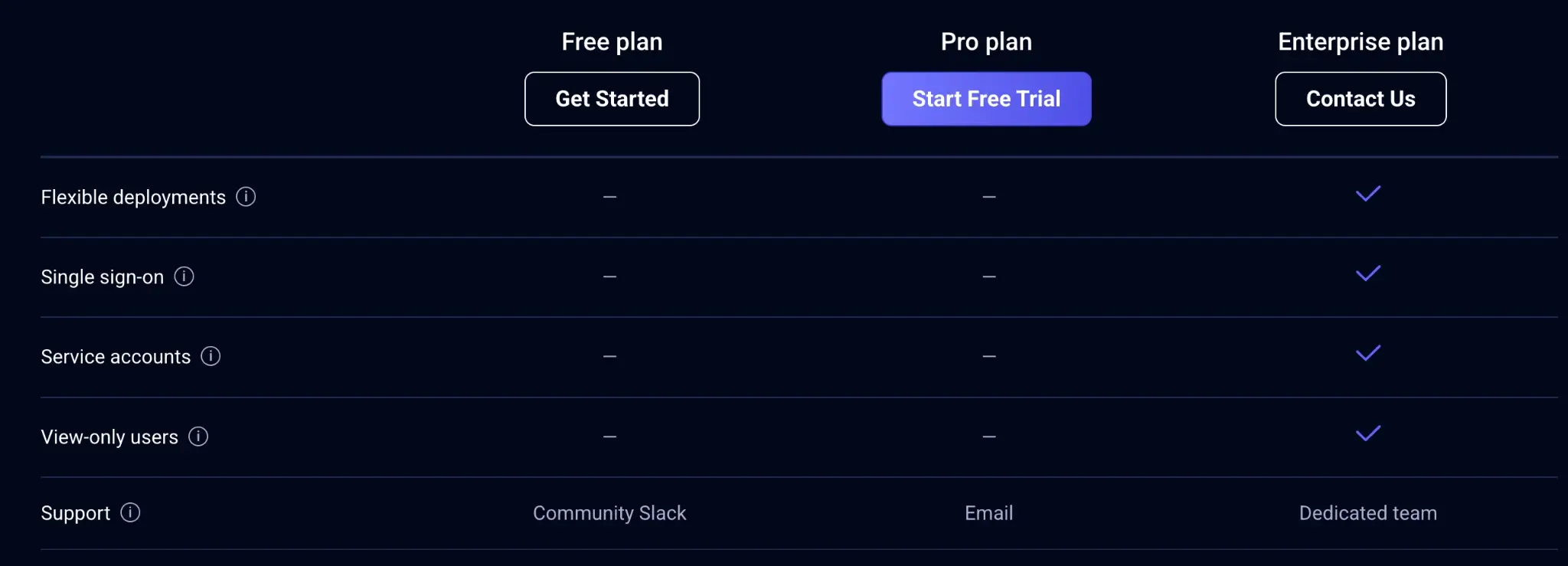
Governance is a common reason why engineers switch to a Comet alternative.
On Comet’s pricing page, Enterprise is the only tier with RBAC, single sign-on, and other security and compliance features.
Startups and mid-sized teams find themselves forced into expensive contracts just to secure their evaluation data or manage user permissions effectively. If your organization needs those controls early, you either budget for Enterprise or you move to tools where access control matches the way you buy software.
2. Usage Limits Become a Tax on Evaluation at Scale
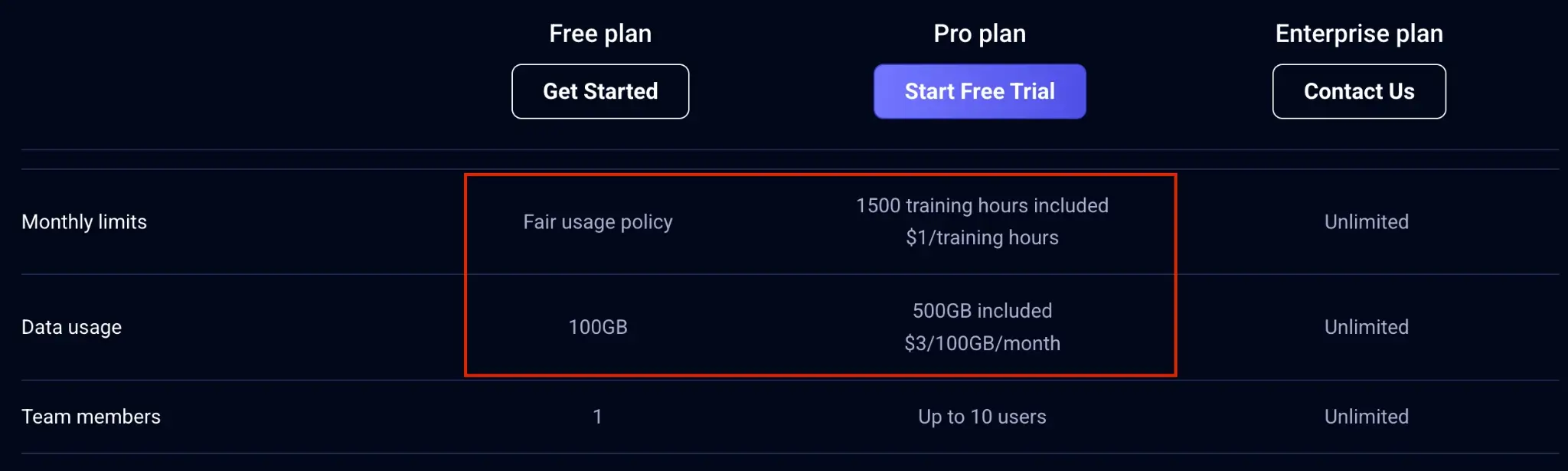
Comet’s cloud-hosted free and pro plans have serious usage limit issues. Data usage at 500 GB sounds reasonable on paper, but experiment tracking data adds up fast: metrics, artifacts, model files, checkpoints, images, and logs.
Also, Comet Pro caps teams at 10 users, which means any organization with multiple ML squads is effectively forced into the Enterprise plan. If anything, you upgrade just to unlock basics like centralized access control, shared workspaces, and safe collaboration across projects.
Once you move to Enterprise, Comet’s published plan limits for training hours and data usage are removed (both are listed as unlimited). The remaining “constraint” is contractual: pricing and terms are negotiated, and you still need internal cost attribution if multiple teams share one account.
3. Self-Hosting is Possible, But Still Real Work for Platform Teams
Comet supports self-hosting and multiple deployment modes (including self-serve and on‑premise). But running it in a production setting still shifts operational burden onto your platform team: upgrades, database and storage operations, backups, and reliability planning become your responsibility. For many organizations, that workload is acceptable only if they already have dedicated DevOps capacity.
Evaluation Criteria
We evaluated each Comet alternative based on how well it supports production-grade model evaluation across three categories:
- Deployment and operations: We checked if the tool offers self-hosted or managed options. A viable alternative needs Kubernetes readiness, clear upgrade paths, and manageable stateful dependencies like databases or object storage. We also considered the expected disaster recovery and backup requirements.
- Security, access control, and compliance: It’s no secret that enterprise evaluation requires strict governance. We looked for SSO/SAML integration, granular role-based access control at the project or model level, and comprehensive audit logs. We also took factors like proper handling of PII, encryption, and data residency policies into our assessment.
- Metrics flexibility (classic ML + LLM): Evaluation tools must support custom metrics that teams can version and share. For LLM use cases, we prioritized tools that handle factuality, toxicity, and hallucination checks. The best platforms support multiple judge strategies and allow metric aggregation across different data slices.
What are the Top Alternatives to Comet
These 9 Comet alternatives fall into four buckets: pipeline and lineage platforms, experiment tracking suites, cloud ML platforms, and LLM-first tracing plus evaluation tools.
<tr>
<td><a href="https://www.zenml.io/" target="_blank">ZenML</a></td>
<td>Building reproducible evaluation workflows across ML and LLMs</td>
<td>
<ul>
<li>Pipeline-based evaluation runs</li>
<li>Artifact and metric lineage</li>
<li>CI-friendly eval execution</li>
</ul>
</td>
<td>
<ul>
<li>Self-hosted: Free forever and custom plans</li>
<li>SaaS: Plans start from $399/month</li>
</ul>
</td>
</tr>
<tr>
<td><a href="https://wandb.ai/site/" target="_blank">Weights & Biases Weave</a></td>
<td>Comparing models and evaluations at scale with rich visual analysis</td>
<td>
<ul>
<li>Eval metrics and run comparison</li>
<li>LLM tracing via Weave</li>
<li>Dataset and artifact tracking</li>
</ul>
</td>
<td>
<ul>
<li>Free (Personal)</li>
<li>Paid plans from $60/month</li>
</ul>
</td>
</tr>
<tr>
<td><a href="https://mlflow.org/" target="_blank">MLflow</a></td>
<td>A lightweight, standard evaluation and model tracking</td>
<td>
<ul>
<li>Metric and artifact logging</li>
<li>Model registry with versioning</li>
<li>Offline and batch eval runs</li>
</ul>
</td>
<td>
<ul>
<li>Free (Open source)</li>
</ul>
</td>
</tr>
<tr>
<td><a href="https://www.databricks.com/" target="_blank">Databricks</a></td>
<td>Running an evaluation inside a unified lakehouse</td>
<td>
<ul>
<li>MLflow-based eval tracking</li>
<li>Notebook-driven analysis</li>
<li>Native Spark scalability</li>
</ul>
</td>
<td>
<ul>
<li>Usage-based (Platform)</li>
</ul>
</td>
</tr>
<tr>
<td><a href="https://google.github.io/adk-docs/" target="_blank">Google ADK</a></td>
<td>Building and testing agents on Google’s stack</td>
<td>
<ul>
<li>Structured agent eval hooks</li>
<li>Tool and action tracing</li>
<li>Tight GCP integration</li>
</ul>
</td>
<td>
<ul>
<li>Free (SDK)</li>
<li>GCP usage costs</li>
</ul>
</td>
</tr>
<tr>
<td><a href="https://aws.amazon.com/sagemaker/" target="_blank">Amazon SageMaker</a></td>
<td>AWS-native team evaluating models in production pipelines</td>
<td>
<ul>
<li>Built-in model monitoring</li>
<li>Batch and real-time eval jobs</li>
<li>Managed infra and security</li>
</ul>
</td>
<td>
<ul>
<li>Usage-based (AWS)</li>
</ul>
</td>
</tr>
<tr>
<td><a href="https://azure.microsoft.com/en-us/products/machine-learning" target="_blank">Azure Machine Learning</a></td>
<td>Enterprises standardizing evaluation on Azure</td>
<td>
<ul>
<li>Dataset-driven evaluations</li>
<li>Model and run comparison</li>
<li>Governance and access controls</li>
</ul>
</td>
<td>
<ul>
<li>Usage-based (Azure)</li>
</ul>
</td>
</tr>
<tr>
<td><a href="https://phoenix.arize.com/" target="_blank">Arize Phoenix</a></td>
<td>Evaluation-heavy teams focused on LLM and RAG quality</td>
<td>
<ul>
<li>LLM-as-judge templates</li>
<li>Embedding-based error analysis</li>
<li>OpenTelemetry tracing</li>
</ul>
</td>
<td>
<ul>
<li>Free (Open Source)</li>
<li>Paid plans from $50/month (Hosted)</li>
</ul>
</td>
</tr>
<tr>
<td><a href="https://langfuse.com/" target="_blank">Langfuse</a></td>
<td>Need deep prompt and trace-level evaluation</td>
<td>
<ul>
<li>Trace-level eval scoring</li>
<li>Prompt versioning and tests</li>
<li>OpenTelemetry support</li>
</ul>
</td>
<td>
<ul>
<li>Free (Open Source)</li>
<li>Paid plans from $29/month</li>
</ul>
</td>
</tr>| Comet Alternatives | Best For | Key Features | Pricing |
|---|
1. ZenML
ZenML is the workflow layer that turns evaluation from a dashboard activity into a repeatable pipeline. You define eval runs as steps, persist outputs as artifacts, and keep metric lineage intact across versions. It’s CI-friendly by design, and you can swap trackers, registries, and judges without rewriting pipeline code.
Key Feature 1. End-to-End Pipeline Workflow Management
Comet is good at tracking and analysis. ZenML’s center of gravity is defining and running multi-step ML/LLM workflows (pipelines made of steps that produce artifacts), so you can take a messy notebook-to-prod journey and turn it into a repeatable system.
If your pain is ‘we can’t reliably rerun, schedule, standardize, and operate this workflow,’ ZenML is a stronger and better alternative to Comet.
Key Feature 2. Stronger ‘Artifact-First’ Backbone for Production Workflows
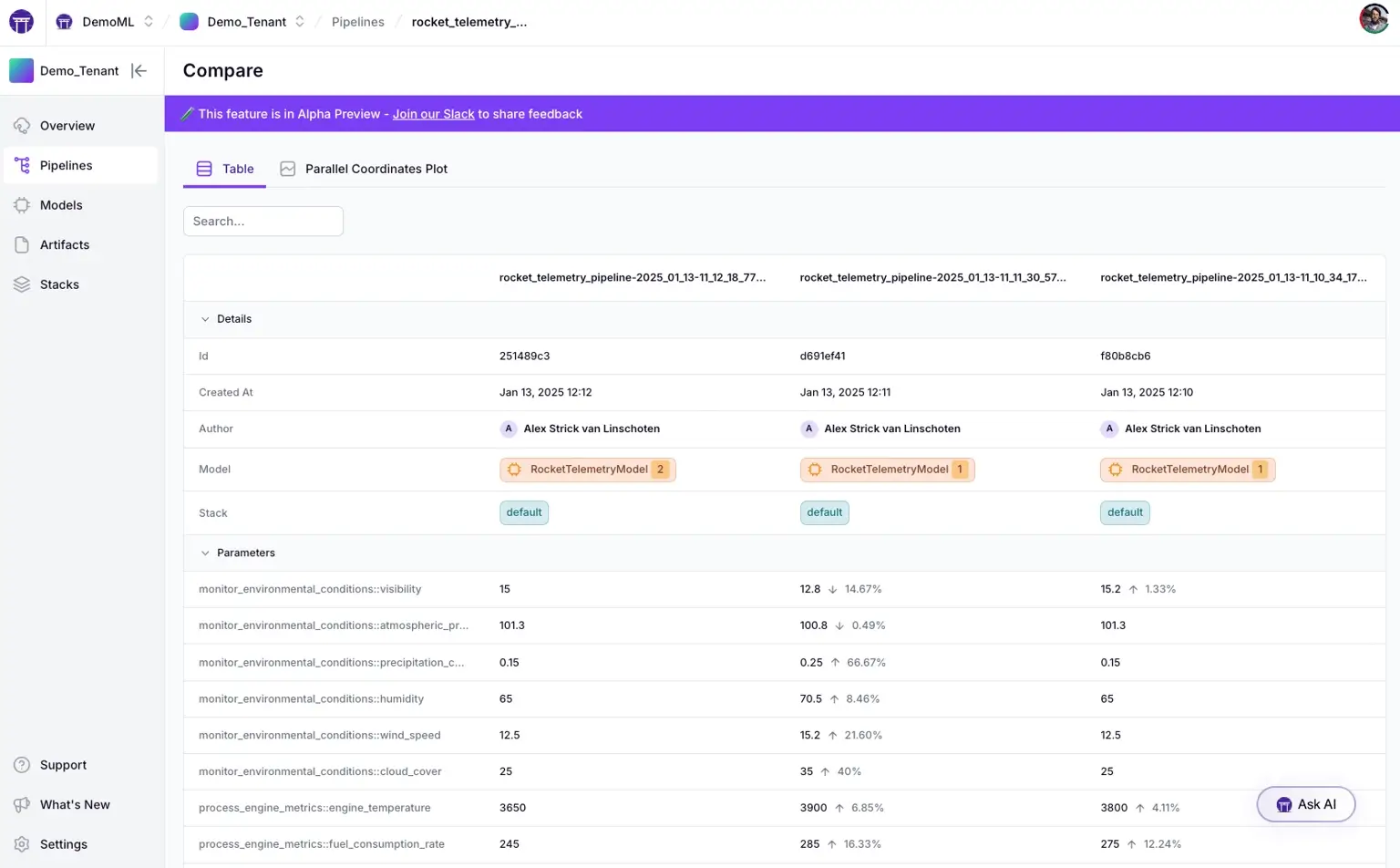
ZenML requires an Artifact Store and treats step inputs/outputs as artifacts that get persisted, which makes it naturally suited to production pipelines where artifacts must live beyond a single experiment session. Comet can version and visualize artifacts/lineage, but ZenML’s workflow model is designed around artifacts as the backbone of execution.
Key Feature 3. Infrastructure Portability via ‘Stacks’
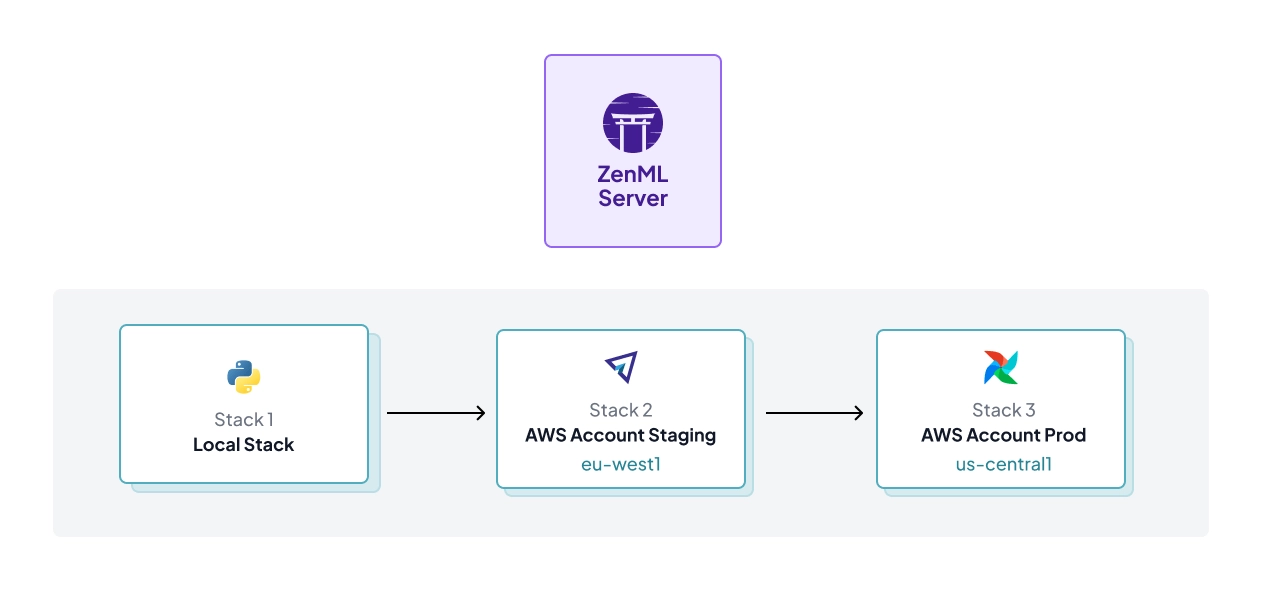
ZenML formalizes your infrastructure as a Stack (orchestrator + artifact store + optional components). This is how you standardize execution across environments and teams and avoid hard-coupling your workflow to one platform. Comet doesn’t position itself as the layer that defines your full execution stack.
Pricing
ZenML offers a free, open-source Community Edition (Apache 2.0). It also has a Pro plan for enterprise users who require managed infrastructure, role-based access control, or advanced collaboration features.
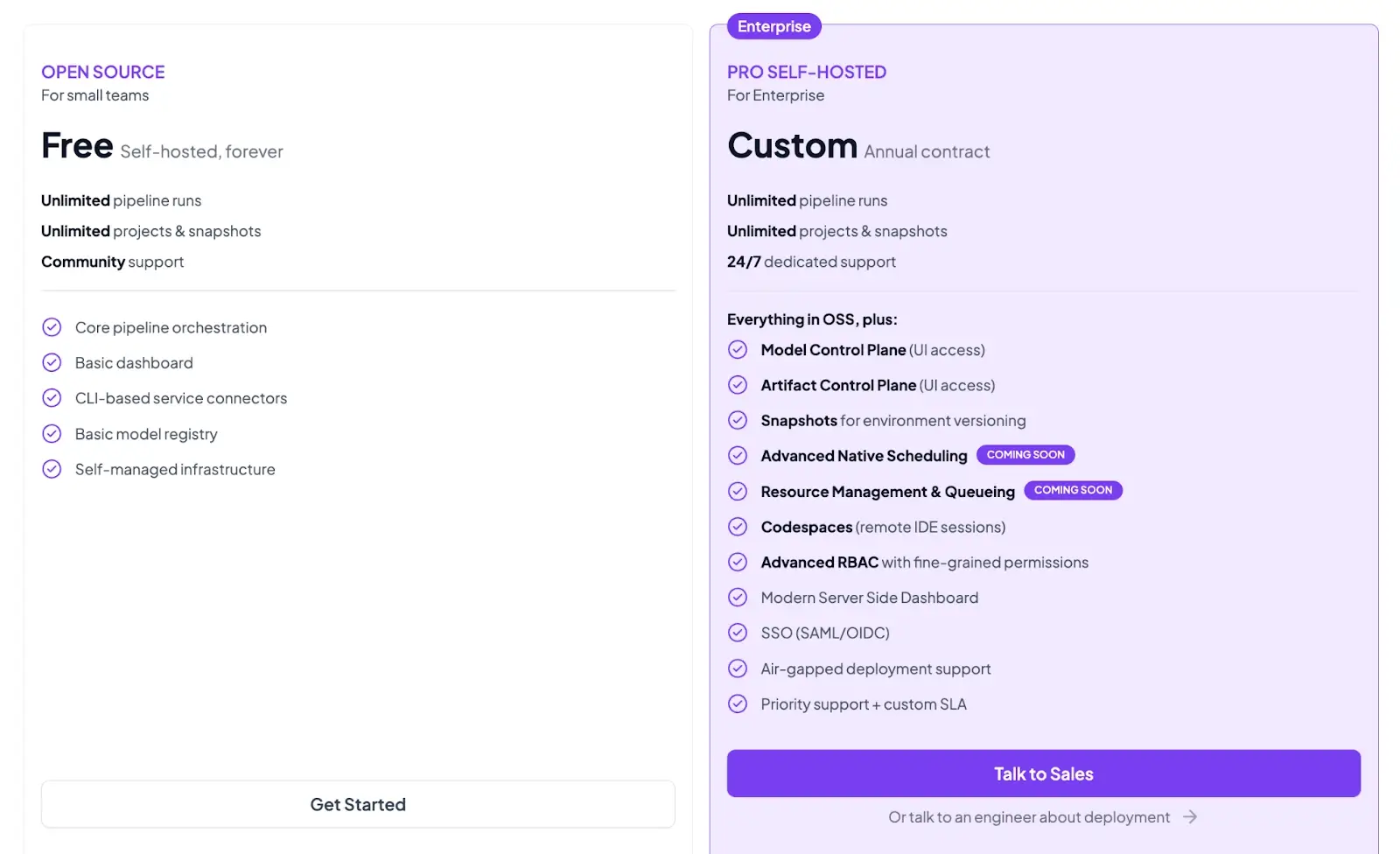
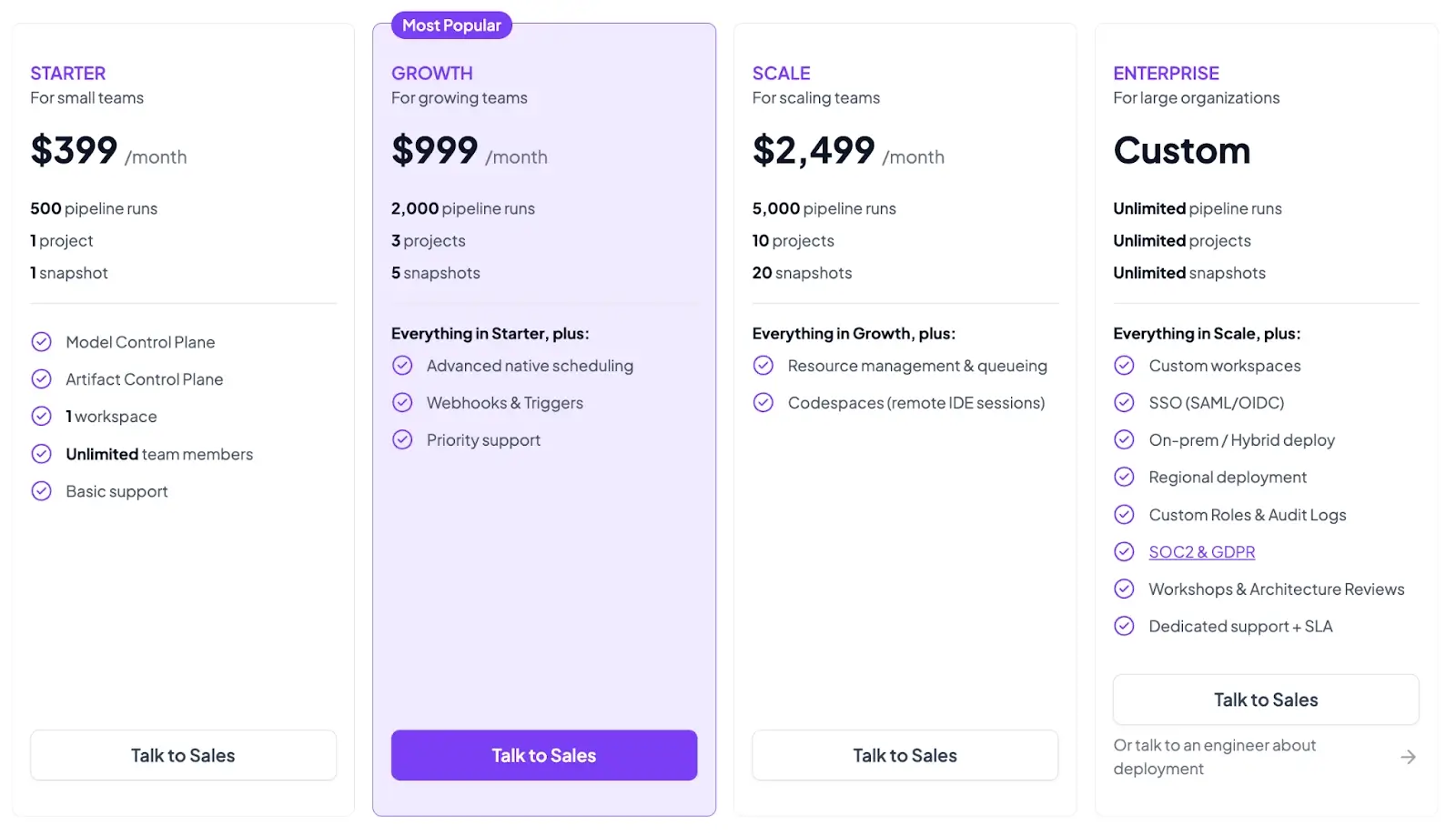
Both the plans above are self-hosted. ZenML now also has 4 paid SaaS plans:
- Starter: $399 per month
- Growth: $999 per month
- Scale: $2,499 per month
- Enterprise: Custom pricing
Pros and Cons
ZenML helps you turn messy ML/LLM work into repeatable pipelines. You define clear steps and rerun the same workflow reliably across environments. It integrates with tools like Comet, MLflow, W&B, cloud services, and orchestrators, so you don’t have to replace everything at once.
But if you are a very small team that just does ad-hoc experiments, the structure that ZenML provides can feel like extra overhead before you see the payoff.
2. Weights & Biases
Weights & Biases is a tracking suite, and Weave adds evaluation primitives for LLM apps. It’s a solid Comet alternative when you want training tracking plus judge scoring under one workspace. It also replaces Comet’s dashboard with interactive charts for model evaluation metrics.
Features
- Define dataset-based evals with Weave Evaluation objects to score runs against the same inputs and metrics every time.
- Apply LLM-as-a-judge scoring patterns using standard judge prompts and grading logic from W&B eval docs.
- Log eval results incrementally with
EvaluationLoggerfor workflows where outputs arrive step by step, not in one pass. - Trace LLM calls and attach scores to traces to inspect prompts, responses, and judgments together during debugging.
- Schedule evals and configure alerts on paid plans to detect regressions without manual reviews.
Pricing
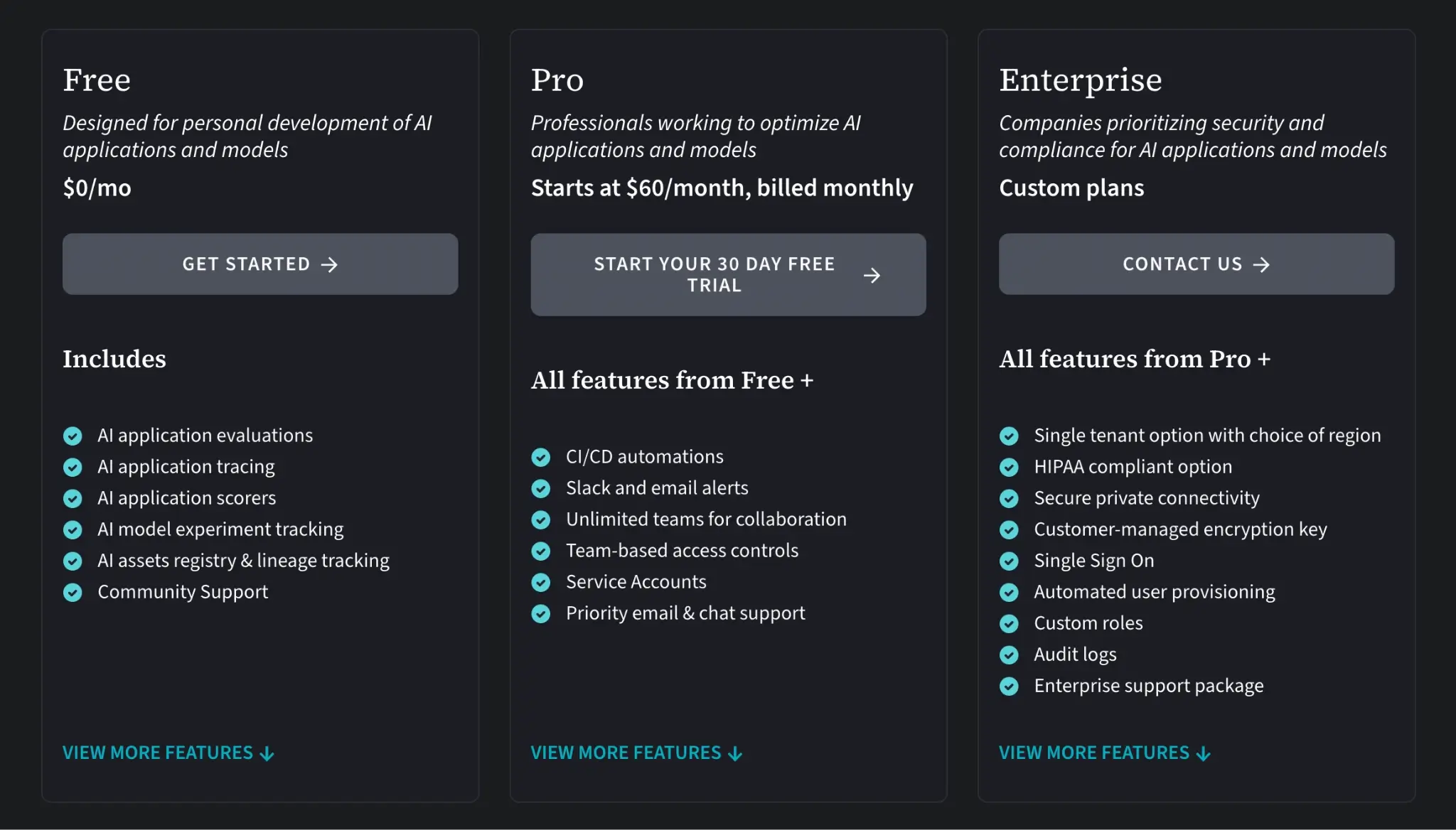
W&B offers a free tier for personal projects and two paid tiers:
- Pro: $60 per month
- Enterprise: Custom pricing
Pros and Cons
On G2, reviewers often describe W&B as easy to use. They frequently highlight the speed and clarity of the interactive UI when comparing multiple model evaluations. The platform makes it simple to share reports and findings across the organization.
W&B supports running a local self-hosted server for Personal (non-corporate) use. For organizational deployments that need compliance, centralized admin controls, or vendor support, self-managed hosting is typically handled via Enterprise offerings and contracts.
📚 Read more about W&B alternatives: What are the top WandB alternatives
3. MLflow
MLflow is an open-source platform dedicated to managing the machine learning lifecycle. It acts as a highly standardized Comet alternative by providing a universal model registry and logging system without proprietary lock-in.
Features
- Evaluate classic models with the built-in evaluation API using standard or custom metrics for regression and classification tasks (and extend evaluation to other task types via custom evaluators/metrics).
- Evaluate LLM apps and agents via
mlflow.genai.evaluate()with scorer objects and optional LLM judges to assess outputs beyond accuracy. - Organize shared tracking servers with workspaces and apply workspace-level permissions for teams and projects.
- Package models in standard formats to guarantee consistent evaluation across different deployment environments.
Pricing
MLflow is open source under the Apache 2.0 license and is free to use.
Pros and Cons
MLflow’s major pro is portability. You can host MLflow anywhere and keep evaluation data in your own infrastructure. The universal format makes transferring models between systems straightforward.
MLflow’s UI can be brittle in practice; Some users report intermittent UI regressions (e.g., sorting or chart interactions) in issue trackers, so it’s worth validating the UX for your workflow before standardizing on it.
📚 Read more about MLflow alternatives: What are the top MLflow alternatives
4. Databricks (Lakehouse + ML tooling)
Databricks provides a unified data platform with native MLflow integration. For evaluation, it’s among popular Comet alternatives because it brings MLflow-based LLM evaluation and agent evaluation close to Lakehouse data. You get an environment where data engineering and model evaluation happen in the same place.
Features
- Track experiments using built-in evaluators to compute metrics like RMSE and F1 Score directly within Spark.
- Build eval datasets from production data and run MLflow evaluation jobs on top of Lakehouse tables.
- Score outputs with LLM-as-a-judge and switch judge models when you need a different provider.
- Define rubric checks with guideline-based judges to enforce pass or fail quality gates.
- Compare agent versions using Mosaic AI Agent Evaluation to track changes across releases.
Pricing
Databricks pricing is usage-based. Databricks cites Mosaic AI Agent Evaluation at $0.15 per million input tokens and $0.60 per million output tokens.
Pros and Cons
Databricks excels at scale. Teams appreciate the ability to run evaluations directly where their data resides. The tight integration between data pipelines and machine learning workflows eliminates the need to move data between systems.
But remember, adopting Databricks only for evaluation is a large platform decision. The pricing structure is notoriously complex. It’s difficult to predict costs, as charges accumulate across compute, storage, and specific ML features. Also, operating the platform requires specialized knowledge of the Databricks ecosystem.
📚 Read more about Databricks alternatives: What are the top Databricks alternatives
5. Google Agent Development Kit
Google ADK is a code-first toolkit that treats agent evaluation like software testing. It’s a solid Comet alternative for teams building multi-agent architectures rather than traditional machine learning models.
Features
- Evaluate agents against datasets and criteria using ADK’s built-in evaluation APIs to check correctness, safety, and task success.
- Run regression tests from the CLI and plug them into CI with pytest-style patterns to catch behavior changes early.
- Score both final outputs and execution paths so tool calls, intermediate steps, and decisions are judged, not just the answer.
- Test goal completion with user simulation by modeling realistic user behavior instead of enforcing fixed action sequences.
Pricing
Google ADK integrates with Google Cloud and is open source under the Apache 2.0 license. The underlying Vertex AI and compute resources consumed during evaluation are your costs.
Pros and Cons
The main advantage is test discipline. Google ADK provides deep control over agent behavior. Developers value the granular orchestration controls and the native support for multimodal data inputs like audio and video. The experimental grounding features offer a unique way to validate factual accuracy.
The tool remains relatively new and highly specialized. It requires deep commitment to the Google Cloud ecosystem. Teams building standard classification or regression models will find it entirely unsuitable for their needs.
6. Amazon SageMaker
Amazon SageMaker is the managed option for teams on AWS. It delivers an end-to-end suite of machine learning tools for training, tracking, and evaluating models without external dependencies.
Features
- Track inputs, parameters, and outputs as runs and group related runs into experiments for a structured evaluation history.
- Compare runs and metrics in Studio Classic using built-in charts to spot performance differences across versions.
- Log evaluation visuals like confusion matrices and ROC curves through the Experiments SDK for standard model analysis.
- Use MLflow integrations in the new Studio UI if you prefer MLflow-style tracking and evaluation flows.
- Trace model lineage from logged steps and artifacts to support audits and reproducibility checks.
Pricing
SageMaker uses pay-as-you-go pricing based on the AWS resources you consume. You pay hourly rates for the specific EC2 instances used during training and evaluation, plus underlying storage costs.
Pros and Cons
The major advantage is SageMaker’s broad integrations with various systems, which significantly enhance AI and ML workflows. It’s robust and can handle massive training jobs and scale automatically. The integrated JupyterLab environments make it easy for data scientists to start experimenting immediately.
On the flip side, the interface and permission models confuse many beginners. Configuring IAM roles and understanding the pricing details is also tricky. Besides, tying your evaluation pipeline to SageMaker creates a deep vendor lock-in with AWS.
7. Azure Machine Learning
Azure Machine Learning offers an enterprise-grade workspace for the entire machine learning lifecycle. It serves as a highly secure Comet alternative for organizations heavily invested in the Microsoft ecosystem.
Features
- Build evaluation flows that compute metrics from batch outputs against ground truth using prompt flow.
- Run batch evaluation with per-item scores and view aggregated metrics across the full dataset.
- Test prompt variants at scale by running the same eval flow across multiple prompt versions.
- Log evaluation metrics with the prompt flow SDK using log_metric for consistent tracking.
Pricing
Azure Machine Learning is billed pay‑as‑you‑go for the underlying compute and associated Azure services you use; pricing details are published, and enterprise agreements are available for organisations that want negotiated terms.
Pros and Cons
Azure Machine Learning is popular in enterprise environments. You’d love the granular security controls and native compliance features. Another upside is a clear evaluation-flow model for prompts. The platform handles complex deployment topologies and integrates flawlessly with other Azure data services.
The downside is that ownership spreads across several Azure services, so budgeting and access control still need platform involvement. The UI can feel bloated; many complain that simple tasks require navigating through too many menus.
8. Arize Phoenix
Arize Phoenix is an open-source observability platform designed specifically for generative AI. It replaces Comet by focusing deeply on tracing and evaluating large language models rather than traditional machine learning algorithms.
Features
- Ingest OpenTelemetry traces for LLM workflows and inspect prompts, responses, and timings in the Phoenix UI.
- Run judge-style evaluations with Phoenix Evals from Python or TypeScript to score generations using LLM judges.
- Use datasets and experiments to run repeatable evaluations and compare results across models or prompt changes.
- Deploy with Docker or Kubernetes, including Helm when moving beyond local setups.
Pricing
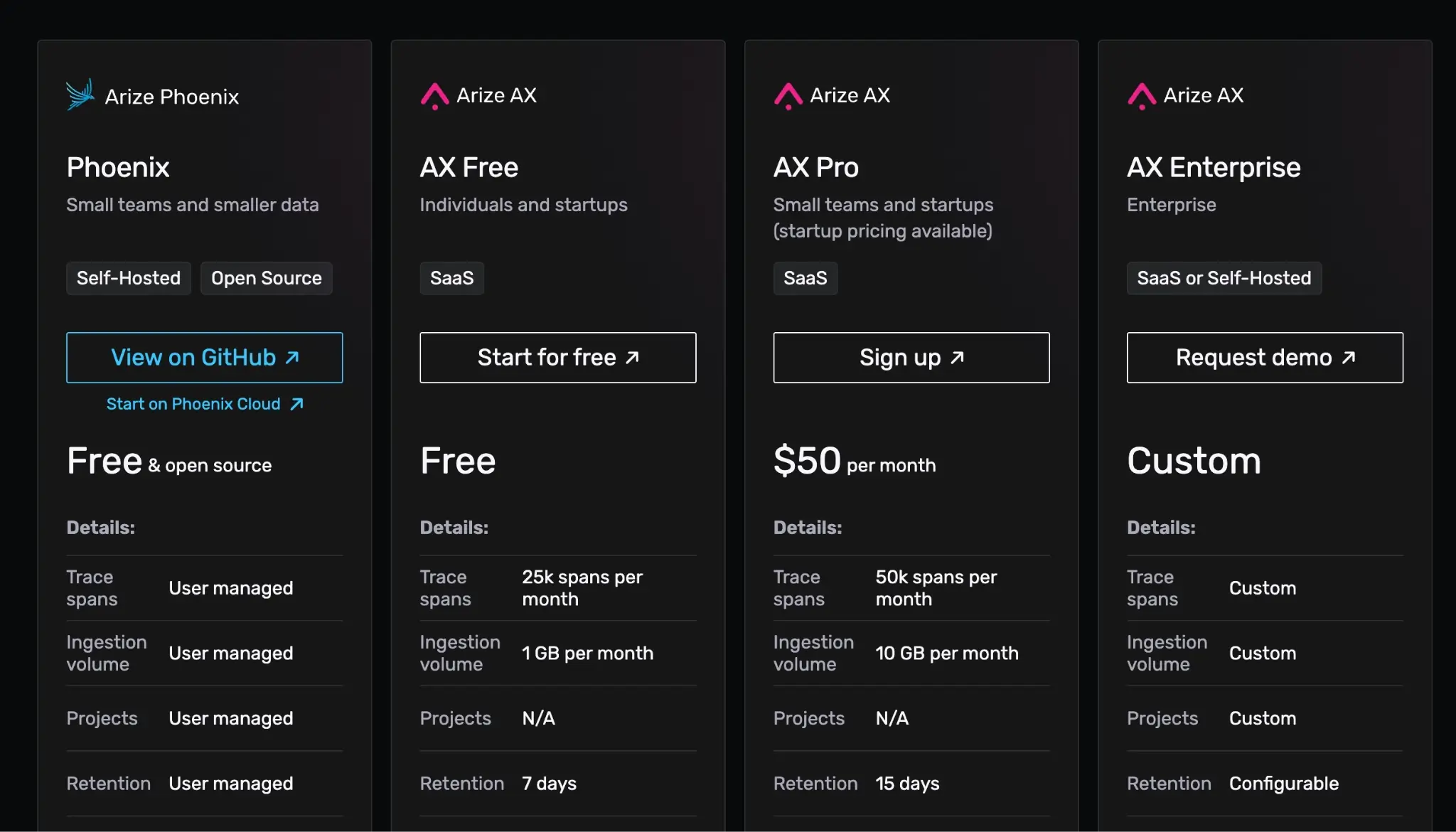
Phoenix is free to self-host and source-available under the Elastic License 2.0 (ELv2). For managed cloud usage, Arize offers AX plans (including a free tier) with paid tiers starting at $50/month and Enterprise with custom pricing.
- AX Pro: $50 per month
- AX Enterprise: Custom
Pros and Cons
Phoenix’s biggest upside is control over data and features in self-hosted mode. Its lightweight deployment and a sleek tracing interface make debugging complex agent workflows straightforward.
On GitHub, a few users have reported trace completeness issues in certain integrations (for example, seeing partial spans), so it’s worth testing end-to-end tracing with your framework and deployment setup.
9. Langfuse
Langfuse is an open-source LLM engineering platform. It serves as a Comet alternative by providing precise metric tracking and prompt management for conversational AI applications.
Features
- Create datasets and run offline experiments to evaluate model or prompt behavior in a repeatable setup.
- Run LLM-as-a-judge evaluators on observations, traces, or experiment datasets to score quality and relevance.
- Collect human feedback through annotation queues and link ratings directly to traces and experiment runs.
- Self-host using documented deployment guides with Postgres and ClickHouse as core storage components.
- Add audit logs and SCIM on Enterprise plans and enable enterprise SSO via the Teams add-on.
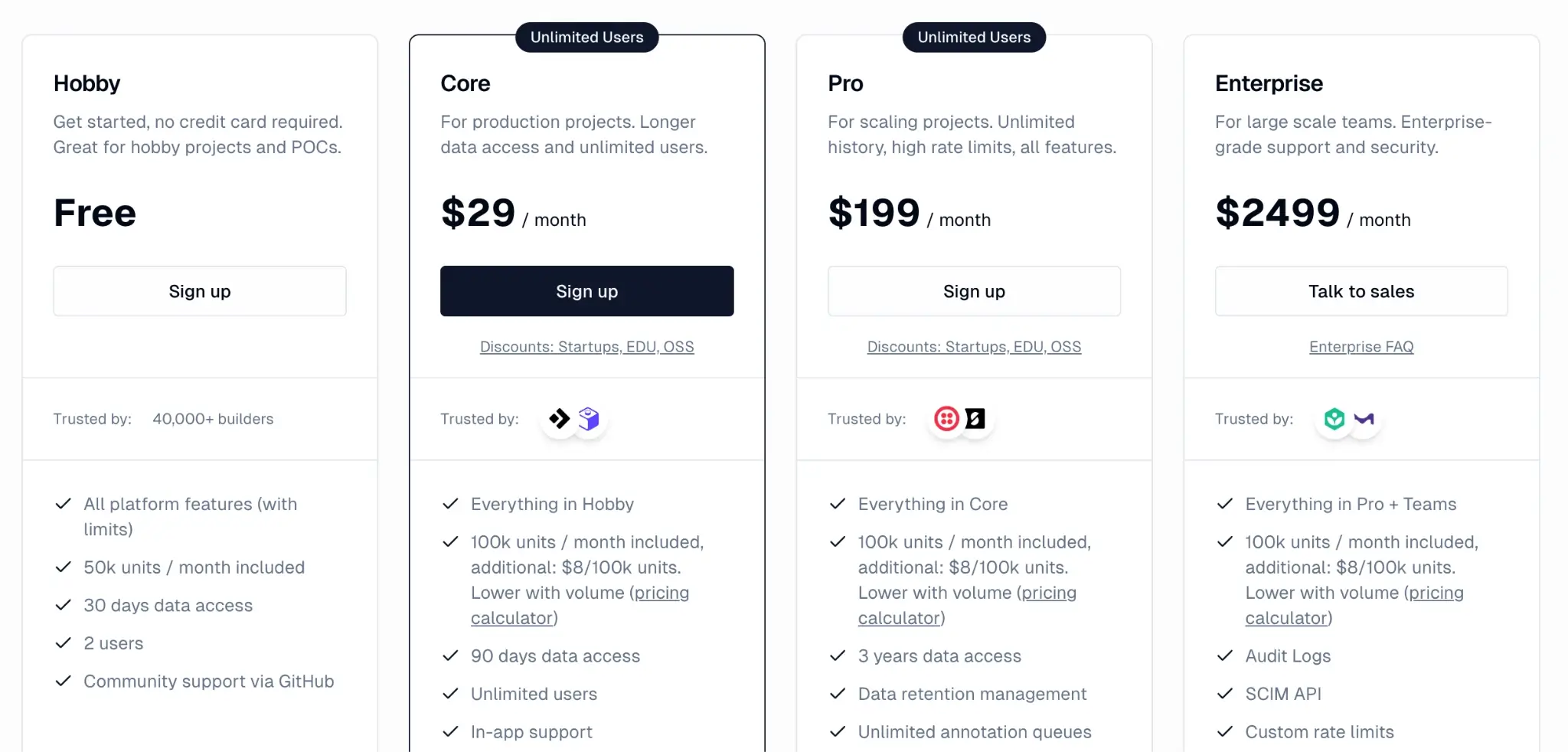
Pricing
Langfuse offers a generous free plan for hobbyists and individual developers. Other than that, it has three paid plans:
- Core: $29 per month
- Pro: $199 per month
- Enterprise: $2,499 per month
Pros and Cons
Langfuse’s docs make it easy to structure evaluations as datasets and experiments, and to run live evaluators on trace data. Community discussions on Reddit also point to manual and automated evaluations, as well as custom scoring, as reasons people try it. Langfuse’s UI also provides immediate clarity on token costs and execution times.
As with many ClickHouse-backed systems, upgrades can occasionally require careful migration review, so platform teams should test upgrades in staging and follow release notes closely.
📚 Read more about Langfuse alternatives: What are the best Langfuse alternatives on the market?
The Best Comet Alternatives for Model Evaluation
Choosing the right alternative to Comet depends entirely on your architectural preferences and your specific AI use case.
- If you build complex agentic systems, tools like Arize Phoenix and Langfuse offer the specialized tracing you need to debug LLM outputs. They focus entirely on the generative AI stack.
- If you require enterprise-grade security and massive scalability, cloud-native solutions like Databricks, SageMaker, or Azure Machine Learning provide managed infrastructure.
- If you want the ultimate freedom to design your evaluation workflow, choose ZenML.
ZenML allows you to build a modular machine learning stack. You can swap your experiment tracker, model registry, and evaluation judges without rewriting your pipeline code. It integrates directly with tools like MLflow or Weights & Biases to give you the exact visualization capabilities you want.


