

On this page
Promptfoo is a popular open-source toolkit that helps you test and evaluate LLM prompts via simple CLI/YAML definitions. However, as teams move from simple prompt testing to building complex AI agents in production, Promptfoo’s command-line interface and offline nature often hit a ceiling.
Teams then want richer, Python-native frameworks that offer end-to-end observability, test and dataset management, and experiment versioning, features beyond Promptfoo’s scope.
In this article, we compare the 9 leading Promptfoo alternatives that provide more powerful evaluation and deployment capabilities for AI agents.
TL;DR
- Why Look for Alternatives: Promptfoo focuses heavily on local, CLI-based testing using YAML configurations. This creates friction for non-technical team members who need a UI, and it lacks the real-time, online observability required for production agents.
- Who Should Care: ML engineers, python developers, and AI product teams who need a complete lifecycle solution, from testing prompts to monitoring live agents, rather than just a local evaluation runner.
- What to Expect: An in-depth analysis of 9 alternatives to Promptfoo, ranging from dedicated evaluation frameworks like DeepEval and RAGAS to full-stack MLOps platforms like ZenML and LangSmith.
The Need for a Promptfoo Alternative?
While Promptfoo is lightweight and quick to set up, it has its own set of limitations:
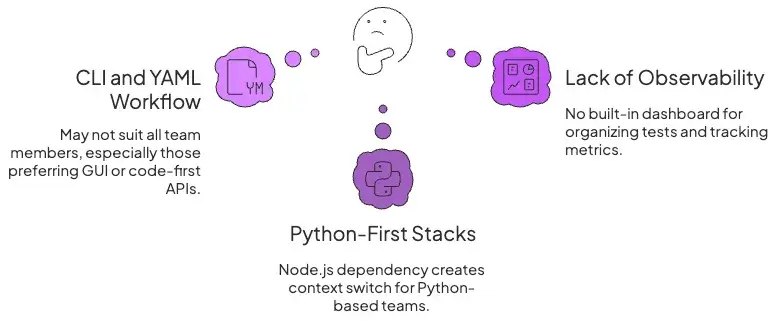
1. CLI and YAML-Heavy Workflow Doesn’t Fit Every Team
Promptfoo operates primarily through a Command Line Interface (CLI) or YAML. While engineers might enjoy this, it alienates developers, and product managers may prefer code-first APIs or GUI-based tools rather than manual config files or Node.js tooling.
2. Python-First Stacks want Native Libraries, Not a Node Tool
Promptfoo is built on Node.js. While it supports Python scripts, it is fundamentally a JavaScript ecosystem tool. For ML teams whose entire infrastructure is Python-based, introducing a Node.js dependency for evaluation creates an unnecessary context switch.
3. Need for End-to-End Observability and Prompt Management
Promptfoo records run results, but it provides no built-in dashboard for organizing tests, datasets, or alerts. There’s no central UI to browse past evaluations, tag experiments, or track metrics over time, unlike full observability platforms.
Additionally, it doesn’t offer version control for prompts, data, or evaluation metrics. Changes to tests require manual file updates. Advanced teams need automatic snapshotting of prompts, answers, and runs for reproducibility and auditability.
Evaluation Criteria
We evaluated Promptfoo alternatives through a lens focused on shipping reliable agents, using these four criteria:
- Supported Tech Stack and Integrations: We prioritized tools that offer native Python SDKs and integrate smoothly with the modern LLM stack (LangChain, LlamaIndex, OpenAI, Anthropic). We looked for tools that fit into existing CI/CD pipelines without forcing a language change.
- Evaluation Capabilities and Metrics: What types of tests can you perform? We looked for tools with advanced, model-graded metrics. Plus, the ability to add custom metrics or human-in-the-loop checks that are essential for validating complex RAG systems.
- Dataset and Test Management: We evaluated how easily a tool allows you to curate, version, and manage 'golden datasets.' Is there a UI or code interface to version datasets of questions or dialogues? A good alternative should allow you to save failing production examples and turn them into future test cases with minimal effort.
- Prompt and Experiment Versioning: Finally, we looked at traceability. Does the tool allow you to version-control your prompts? Can you compare Experiment A vs. Experiment B side-by-side to understand exactly which change caused a regression?
What are the Top Alternatives to Promptfoo
Here is a summary table of the best Promptfoo alternatives:
| Promptfoo Alternatives | Best For | Key Features | Pricing |
|---|---|---|---|
| ZenML | Define reusable evaluation pipelines that track prompts, datasets, metrics, and artifacts end-to-end in a Python-native workflow, with a UI, lineage, and built-in governance. | - Pipeline-first prompt evaluation - Prompts, outputs, and datasets as versioned artifacts - Centralized Model Control Plane for governance - Built-in LLM and RAG evaluation workflows - Prompt experiment reporting with UI playgrounds | Both free (Open source) and paid (custom pricing) |
| LangSmith | Teams using LangChain that want deep tracing, prompt versioning, and structured evals. | - Trace-level visibility for every LLM or tool call - Prompt versioning + playground - Automated and human evals | - Free - Paid plans start at $39 per month |
| Confident AI & DeepEval | Python teams wanting pytest-style tests with UI scorecards and datasets. | - Pythonic unit tests for prompts - Built-in custom metrics - Scorecards and dataset versioning - Automated and custom evals | - Free - Paid plans start at $19.99 per month |
| TruLens | Teams needing feedback-function evals and strong RAG relevance checks. | - Feedback functions for groundedness and relevance - Token-level trace logging - Notebook-based analysis | Free (Open-source) |
| RAGAS | RAG-heavy teams needing retrieval and answer-faithfulness metrics. | - RAG-specific metrics - Synthetic test generation - End-to-end RAG scoring | Free (Open-source) |
| Comet Opik | Teams wanting open-source tracing, prompt versioning, and CI-friendly tests. | - Full trace logging - Prompt + dataset versioning - CI-friendly tests - Automated chain and code evaluation | - Free (Open-source and cloud) - Paid plans start at $89 per month |
| Weights & Biases Weave | Teams already using W&B and wanting eval dashboards with automatic versioning. | - LLM call logging - Two-stage eval dashboards - Auto versioning for data and code | - Free - Paid plans start at $60 per month |
| Maxim AI | Teams wanting a workspace for prompt building, simulation, and monitoring. | - Prompt IDE + versioning - Large-scale simulations - Continuous evals on data and code | - Free - Paid plans start at $29 per month |
| Arize Phoenix | Teams needing local-first debugging and RAG-focused evaluation. | - Local trace execution - Built-in RAG + hallucination checks - Embedding and retrieval analysis | - Free (Open-source and Cloud) - Paid plan starts at $50/mo |
1. ZenML
ZenML is a pipeline-first MLOps + LLMOps framework that can replace Promptfoo when you want more than local YAML tests. Instead of running ad-hoc CLI experiments, you define reusable evaluation pipelines that track prompts, datasets, metrics, and agent runs end-to-end in a Python-native workflow with a UI, lineage, and governance built in.
Features
- Pipeline-first prompt and agent evaluation: Build evaluation pipelines that ingest test datasets, run prompts or full agents, compute metrics, and log everything to the dashboard. Every step becomes a node in a DAG with run history, step logs, and artifact lineage so you can reproduce and compare experiments over time.
- Prompts, configs, and datasets as versioned artifacts: ZenML treats prompt templates, agent configs, datasets, and predictions as artifacts produced by pipeline steps. These artifacts are automatically stored, versioned, and linked to the steps that created them, letting you diff prompt versions, roll back changes, or reuse the same dataset across runs without manual bookkeeping.
- Central Model Control Plane for governance: The Model Control Plane groups pipelines, artifacts, prompt templates, agent configs, and evaluation results under a single “Model” (or agent system). Teams can track versions, attach metrics and metadata, and promote or demote versions between dev, staging, and production with auditability around who changed what and when.
- Built-in LLM and RAG evaluation workflows: ZenML ships patterns and components for LLM-as-judge metrics, retrieval-quality checks, hallucination/faithfulness scoring, and human-in-the-loop review. You can wire these evaluators into your pipelines so every run logs evaluation scores, golden-dataset performance, and review outcomes by default.
- Prompt and experiment management with UI playgrounds: Prompts and experiments can be edited from the dashboard: modify artifacts like prompt templates or configs, trigger new runs, and compare outputs side-by-side with visual diffs. This gives non-CLI users a way to collaborate on prompt iterations while keeping everything tied back to versioned pipelines.
Pricing
ZenML is free and open-source under the Apache 2.0 license. The core framework, dashboard, and orchestration capabilities are fully available at no cost.
Teams needing enterprise-grade collaboration, managed hosting, advanced governance features, and premium support can opt for ZenML’s custom business plans, which vary by deployment model, usage, and team size.
Pros and Cons
ZenML gives you a unified, Python-native control plane for prompts, datasets, models, and agents, with strong lineage, evaluation, and governance; ideal once you outgrow local Promptfoo runs.
The trade-off is that it introduces a pipeline and infrastructure layer, so there is more setup and a learning curve than a simple CLI tool if you only need quick, one-off prompt checks.
2. LangSmith
LangSmith is an LLM observability and evaluation platform from the LangChain team. It helps developers debug, test, and monitor multi-step chains and agents built with LangChain (or any Python app) with built-in dashboards and evaluation tools.
Features
- Capture every step of an LLM run through detailed traces that log prompts, tool calls, outputs, latency, and token use.
- Inspect chain or agent behavior with a visual trace view that opens each step so you can compare inputs and outputs clearly.
- Store and version prompts in a central prompt library, and test them in an interactive playground to adjust variations fast.
- Run structured evaluations using built-in checks for accuracy, safety, and quality, or route samples to human reviewers when needed.
- Integrate with any Python LLM stack through a lightweight SDK that also supports OpenTelemetry for consistent tracing across systems.
Pricing
LangSmith offers a free tier for individual developers and two paid tiers:
- Plus: $39 per seat per month
- Enterprise: Custom pricing

Pros and Cons
LangSmith offers in-depth analysis of LLM apps, especially chain-of-thought workflows. It provides a polished UI and integrates perfectly with LangChain, making it the default choice for that ecosystem.
However, the costs can scale unpredictably if you log every production trace. It’s also closed-source and mainly a hosted SaaS. Self-hosting is only available in the expensive enterprise plan.
**📚 Also read about **LangSmith vs Langfuse
3. DeepEval + Confident AI
Confident AI is an open-source evaluation framework that allows you to unit test your LLMs as easily as you test Python code. Confident AI is the commercial platform built on top of DeepEval that provides a UI for these tests.
Features
- Define unit tests in Python code using ready-made metrics like G-Eval, Hallucination, and Answer Relevancy.
- Integrate directly into CI/CD pipelines (GitHub Actions, GitLab CI) to block breaking changes before merge.
- Score outputs with built-in or custom metrics, including LLM-as-a-judge scoring for quality checks and reasoning.
- View model and prompt performance through scorecards that surface trends and regressions across runs.
- Manage datasets and annotations in one workspace, with support for synthetic data generation and human review.
Pricing
Confident AI offers a free forever plan and three paid plans:
- Starter: $19.99 per user per month (for small teams)
- Premium: $79.99 per user per month (for mission-critical products)
- Enterprise: Custom pricing

Pros and Cons
Because DeepEval is a Python library, it feels quite natural to developers. You can embed tests directly in code. It supports both modern metrics and HITL review LLM evaluation. Plus, the managed UI of Confident AI adds reporting and collaboration.
On the downside, the system also adds some complexity compared to a pure CLI tool. To get the full featureset, like a visual dashboard and historical tracking, you need the paid Confident AI platform. The open-source version is strictly a library without a persistent UI.
4. TruLens

TruLens is an open-source library (supported by Snowflake) for agentic evaluation. It introduces the concept of ‘Feedback Functions,’ which allows you to programmatically score your app’s responses on quality, toxicity, and relevance.
Features
- Apply built-in feedback functions to score relevance, groundedness, bias, and other quality signals on each model output.
- Instrument LLM workflows with the Python SDK or OpenTelemetry to record every call and feed traces into evaluators.
- Compare runs in the dashboard to spot improvements or regressions across prompt or model versions.
- Inspect agent behavior in a notebook UI with interactive trace trees, embeddings, and step-by-step visualizations.
- Evaluate RAG pipelines with UMAP plots, retrieval metrics, and threshold tuning that reflect answer quality immediately.
Pricing
TruLens is completely free and open-source under the MIT license, with no usage fees or cloud hosting costs.
Pros and Cons
TruLens’s big advantage is flexibility: you can evaluate almost anything about an agent with code-defined feedback. It has no cost and a growing community. Because it’s code-first, it fits smoothly into existing pipelines.
However, it provides no built-in test dataset management or CI integration. There is also no centralized web interface beyond notebooks, so teams needing a turnkey dashboard might find it too raw. In short, it’s powerful and free, but requires more developer effort to set up.
5. RAGAS

RAGAS (Retrieval-Augmented Generation Assessment System) is an open-source Python toolkit specifically for evaluating RAG pipelines without needing ground truth data. It generates synthetic test data to help you bootstrap your evaluation process.
Features
- Compute RAG-focused metrics like contextual relevancy, recall, precision, answer relevancy, and faithfulness to judge how well retrieval and generation work together.
- Generate synthetic Q&A datasets from your corpus to stress-test retrieval and catch weak spots early.
- Score full RAG pipelines by running retrievers and generators on test queries and applying metrics to each step.
- Monitor live traffic with production checks that flag drops in faithfulness or context quality.
- Integrate the library into any Python pipeline and run evaluations in notebooks or CI with a simple install.
Pricing
Ragas is an open-source project and completely free to use. You can install it with pip install ragas and run it anywhere. The only cost is for LLM API calls used by LLM-based metrics.
Pros and Cons
RAGAS solves the ‘cold start’ problem of evaluation by generating test data for you. Its separation of retrieval and generation metrics helps you pinpoint exactly which part of your RAG pipeline is failing. And it’s free and lightweight.
On the other hand, RAGAS is narrowly focused on RAG scenarios. It’s strictly a metrics library, not a full platform. It lacks a UI, trace visualization, or prompt management system, so it’s almost always used along with another tool.
6. Comet Opik
Comet Opik is an open-source LLM evaluation and monitoring platform from Comet. It aims to be an end-to-end tool for logging and testing LLM applications from a single, intuitive interface.
Features
- Log every prompt, tool call, and model output as a detailed trace so you can inspect each step of an LLM run with full context.
- Run automated evaluations using built-in or custom metrics, including LLM-as-judge scoring for subjective checks.
- Version prompts and datasets in a central library that lets you organize experiments and roll back older variants fast.
- Test prompts in an interactive playground where you can switch models, batch-run prompts, and compare outputs instantly.
- Write unit-style tests with assertions that validate expected behaviors and integrate cleanly into CI pipelines.
- Connect Opik to any LLM stack or monitoring setup through the OSS SDK and OpenTelemetry-based instrumentation.
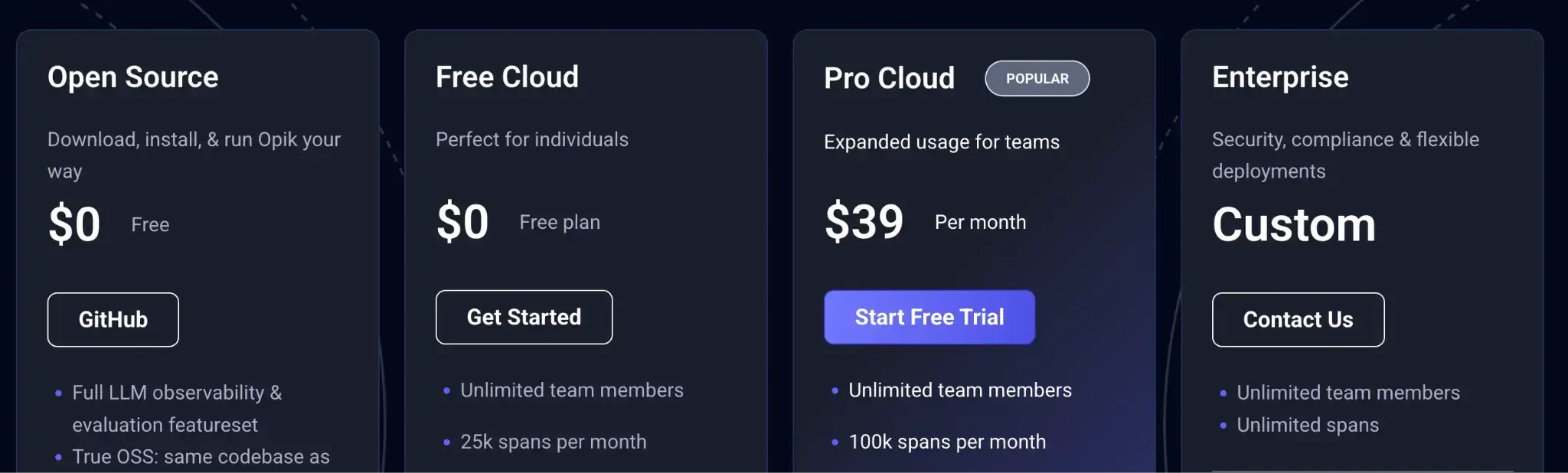
Pricing
Opik is open-source (source-available) to self-host. For the hosted version:
- Free: Generous tier for individuals
- Pro: $39/user per month
- Enterprise: Custom pricing for compliance and scale
Pros and Cons
Opik’s core strengths are performance and feature breadth. It is exceptionally fast in benchmarks, it logs and evaluates interactions far quicker than many rivals. Integration with the broader Comet ecosystem is a plus for existing users.
As a newer tool, however, it may have fewer third-party integrations than established players like LangSmith. It’s also relatively heavyweight to set up and learn.
7. Weights & Biases Weave

Weave is the lightweight toolkit from Weights & Biases designed for tracking and evaluating LLM applications. It brings the familiar W&B experiment tracking philosophy to the world of prompts and agents.
Features
- Log every LLM call with full traces that record prompts, outputs, metadata, latency, and token use for step-by-step debugging.
- Compare model or prompt outputs side by side using visual leaderboards and charts that surface clear performance differences.
- Version datasets, prompts, code, and evaluation functions automatically so you can revert or reproduce any previous run.
- Test prompts in an interactive playground where you can switch models, adjust messages, and log results instantly.
- Handle text, images, audio, and other formats in one place to debug multimodal agent workflows cleanly.
Pricing
W&B offers a free tier for personal projects and two paid plans:
- Pro: $60/user per month
- Enterprise: Custom pricing
Pros and Cons
For teams already living in Weights & Biases, Weave is a natural extension that requires minimal new learning. The visualizations and automatic versioning are top-notch.
The downsides are that it is proprietary and requires using W&B’s cloud service. There’s no open-source option and no pure self-host. Teams must pay per seat for the full feature set, which may be expensive for large teams.
8. Maxim AI
Maxim AI is an end-to-end GenAI evaluation and observability platform designed to speed up agent development. It provides a collaborative environment where product managers and domain experts can review logs, curate datasets, and test prompts alongside engineers.
Features
- Build and version prompts in a no-code workspace that lets you create prompt chains and deploy variants quickly.
- Define custom evaluations or use built-in scorers, including LLM-as-judge and rule-based checks for both offline and live tests.
- Run prompt experiments in a visual playground to test changes against multiple models simultaneously.
- Trace multi-turn agent runs in production and tracks real-time metrics to catch drops in answer quality early.
- Review experiments through dashboards and reports that group runs into clear comparisons or leaderboards.
- Integrate Maxim through Python or CLI SDKs and connect it to any agent framework or CI pipeline with minimal setup.
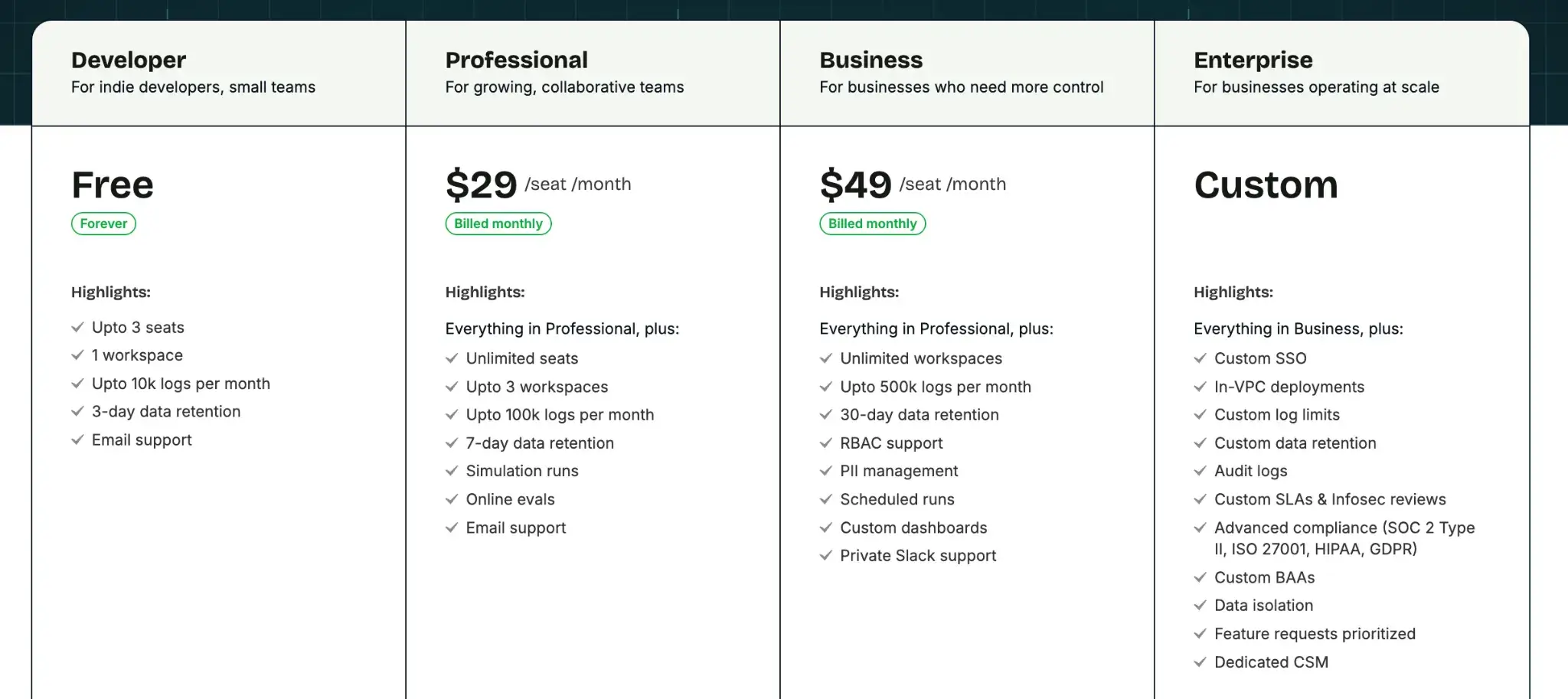
Pricing
Maxim has a Free Developer plan for up to 3 seats, with 10k logs/month. To get the best value, you can choose from its paid plans:
- Professional: $29/seat per month
- Business: $49/seat per month
- Enterprise: Custom pricing
Pros and Cons
Maxim AI offers one of the best user experiences for non-developers. Its simulation engine and end-to-end approach aid development speed.
However, it is a closed ecosystem. Unlike open-source libraries, you are dependent on their platform for all your testing logic and data storage. It’s also relatively new on the scene, so smaller teams should carefully evaluate maturity and support.
9. Arize Phoenix
Phoenix is an open-source observability library from Arize AI. It is designed for ‘notebook-first’ development, allowing you to launch a local server to visualize traces and analyze embeddings without sending data to the cloud.
Features
- Ingest traces from any LLM or agent through local or OpenTelemetry-based instrumentation to record every call in detail.
- Run built-in evaluators that score hallucination, toxicity, accuracy, and RAG retrieval quality directly on logged traces.
- Explore logged data in a notebook UI where you can query runs, view embeddings, inspect retrieval steps, and adjust thresholds.
- Analyze RAG pipelines with clustering views, retrieval-score histograms, and filter tuning that updates results immediately.
- Compare two agent runs side by side to spot metric differences and identify regressions after prompt or model changes.
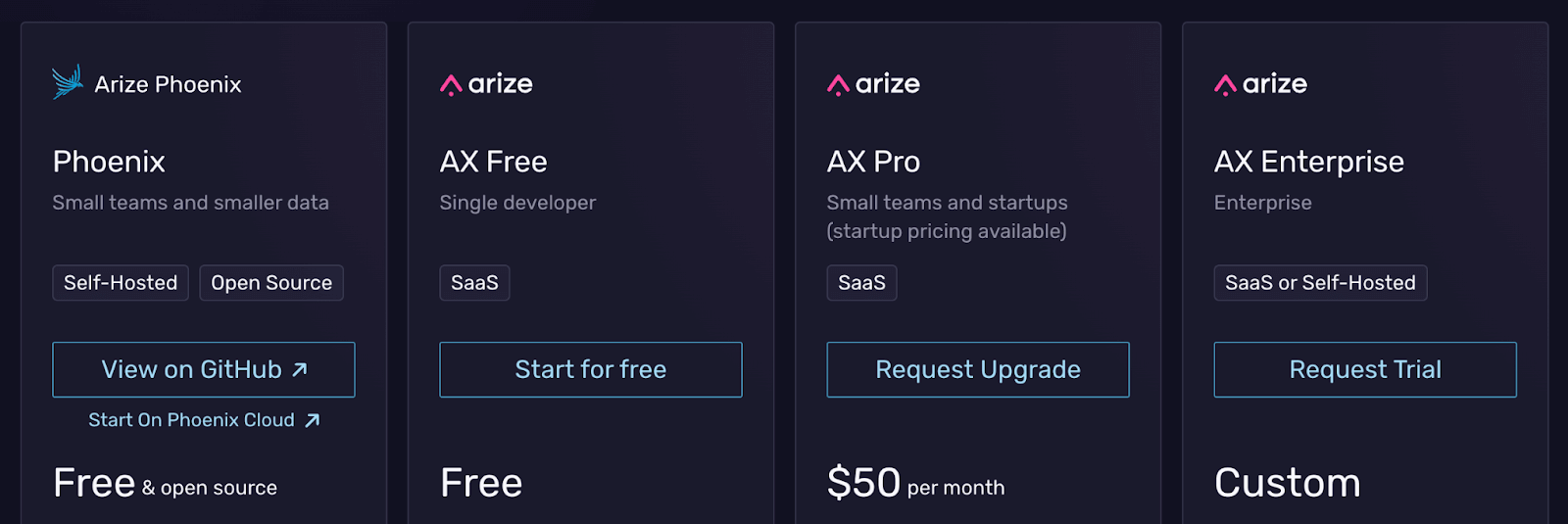
Pricing
Phoenix is open-source and free to run locally. Arize offers a hosted platform (Arize AX) for persistence. It has a free cloud tier and two paid plans:
- AX Pro: $50 per month
- AX Enterprise: Custom pricing
Pros and Cons
Phoenix’s local-first design is its biggest pro. You retain full data control and privacy, which is critical for some use cases. Its RAG-focused visual analytics are unmatched for debugging retrieval issues.
On the con side, Phoenix is not a turnkey cloud service. It can require substantial setup and dev effort to use effectively. It also lacks prompt or version management and is less structured than DeepEval or Promptfoo.
The Best Promptfoo Alternatives to Ship the Most Efficient AI Agents
Promptfoo is a solid starting point for quick prompt testing, but production-grade LLM applications usually demand more. Your choice depends on priorities:
- If you need end-to-end MLOps and reproducibility, a tool like ZenML or Maxim AI may fit best.
- For chain-of-thought tracing in LangChain contexts, LangSmith is convenient.
- For free, customizable observability, Opik or Phoenix shine.
📚 Relevant alternative articles to read:
Take your AI agent projects to the next level with ZenML. We have built first-class support for agentic frameworks (like CrewAI, LangGraph, and more) inside ZenML, for our users who like pushing boundaries of what AI agents can do. With ZenML, you can seamlessly integrate whichever agent framework you choose into robust, production-grade workflows.


